This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Later in 2019, the researchers proposed the ALBERT (“A Lite BERT”) model for self-supervisedlearning of language representations, which shares the same architectural backbone as BERT. The post ALBERT Model for Self-SupervisedLearning appeared first on Analytics Vidhya. The key […].
The following article is an introduction to classification and regression — which are known as supervisedlearning — and unsupervised learning — which in the context of machine learning applications often refers to clustering — and will include a walkthrough in the popular python library scikit-learn.
According to a 2019 survey by Deloitte , only 18% of businesses reported being able to take advantage of unstructured data. As AI adoption continues to accelerate, developing efficient mechanisms for digesting and learning from unstructured data becomes even more critical in the future. Choose Python (PySpark) for this use-case.
As opposed to training a model from scratch with task-specific data, which is the usual case for classical supervisedlearning, LLMs are pre-trained to extract general knowledge from a broad text dataset before being adapted to specific tasks or domains with a much smaller dataset (typically on the order of hundreds of samples).
2019) Data Science with Python. 2019) Applied SupervisedLearning with Python. Skicit-Learn (2023): Cross-validation: evaluating estimator performance, available at: [link] [5 September 2023] WRITER at MLearning.ai / AI Agents LLM / Good-Bad AI Art / Sensory Mlearning.ai Reference: Chopra, R.,
2019) Data Science with Python. 2019) Applied SupervisedLearning with Python. 2019) Python Machine Learning. References: Chopra, R., England, A. and Alaudeen, M. Packt Publishing. Available at: [link] (Accessed: 25 March 2023). Johnston, B. and Mathur, I. Packt Publishing. Raschka, S.
In this tutorial, you will learn about the concepts behind simple linear regression. We will also show how to code it in Python. There are various types of regressions used in data science and machine learning. Conclusion This article described regression which is a supervisinglearning approach. England, A.
Data scientists and researchers train LLMs on enormous amounts of unstructured data through self-supervisedlearning. The model then predicts the missing words (see “what is self-supervisedlearning?” OpenAI’s GPT-2, finalized in 2019 at 1.5 billion parameters, raised eyebrows by producing convincing prose.
Data scientists and researchers train LLMs on enormous amounts of unstructured data through self-supervisedlearning. The model then predicts the missing words (see “what is self-supervisedlearning?” OpenAI’s GPT-2, finalized in 2019 at 1.5 billion parameters, raised eyebrows by producing convincing prose.
We can ask the model to generate a python function or a recipe for a cheesecake. Trained with reinforcement learning to generate completions that are more desired by the user. A similar approach was used in “ Exploring the limits of transfer learning with a unified text-to-text transformer ” which introduced a model called T5.
[link] David Mezzetti is the founder of NeuML, a data analytics and machine learning company that develops innovative products backed by machine learning. In August 2019, Data Works was acquired and Dave worked to ensure a successful transition. What supervisedlearning methods did you use?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




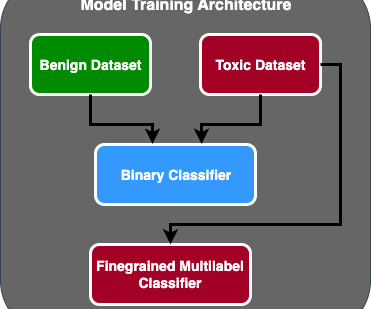



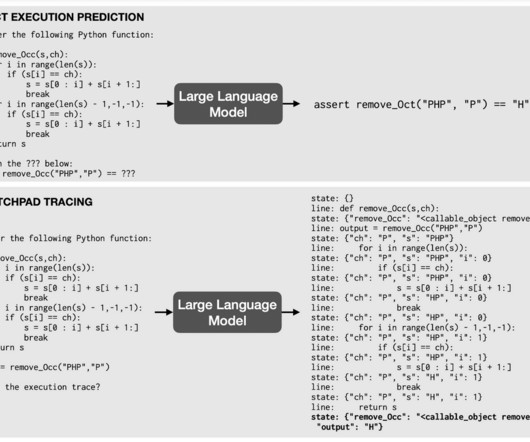
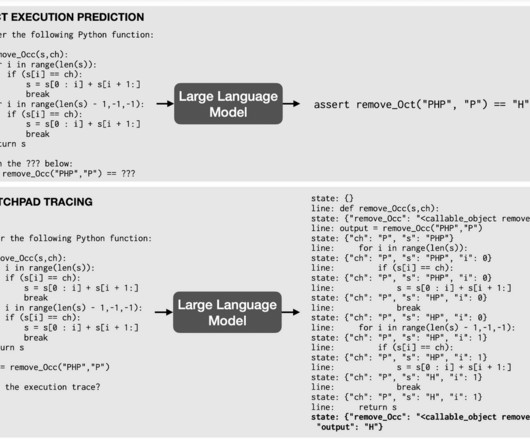








Let's personalize your content