This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Later in 2019, the researchers proposed the ALBERT (“A Lite BERT”) model for self-supervisedlearning of language representations, which shares the same architectural backbone as BERT. The post ALBERT Model for Self-SupervisedLearning appeared first on Analytics Vidhya. The key […].
“If intelligence was a cake, unsupervised learning would be the cake, supervisedlearning would be the icing on the cake, and reinforcement learning would. The post You Can’t Miss these 4 Powerful Reinforcement Learning Sessions at DataHack Summit 2019 appeared first on Analytics Vidhya.
The following article is an introduction to classification and regression — which are known as supervisedlearning — and unsupervised learning — which in the context of machine learning applications often refers to clustering — and will include a walkthrough in the popular python library scikit-learn.
It is an annual tradition for Xavier Amatriain to write a year-end retrospective of advances in AI/ML, and this year is no different. Gain an understanding of the important developments of the past year, as well as insights into what expect in 2020.
A demonstration of the RvS policy we learn with just supervisedlearning and a depth-two MLP. It uses no TD learning, advantage reweighting, or Transformers! Offline reinforcement learning (RL) is conventionally approached using value-based methods based on temporal difference (TD) learning.
Semi-Supervised Sequence Learning As we all know, supervisedlearning has a drawback, as it requires a huge labeled dataset to train. Generating Wikipedia By Summarizing Long Sequences This work was published by Peter J Liu at Google in 2019. But, the question is, how did all these concepts come together?
Using such data to train a model is called “supervisedlearning” On the other hand, pretraining requires no such human-labeled data. This process is called “self-supervisedlearning”, and is identical to supervisedlearning except for the fact that humans don’t have to create the labels.
Improvements using foundation models Despite yielding promising results, PORPOISE and HEEC algorithms use backbone architectures trained using supervisedlearning (for example, ImageNet pre-trained ResNet50). Having joined the organization in 2019, Prabhu trained in medicine St. Bartholomew’s and the Royal London.
Given the availability of diverse data sources at this juncture, employing the CNN-QR algorithm facilitated the integration of various features, operating within a supervisedlearning framework. His focus was building machine learning algorithms to simulate nervous network anomalies.
Transformers made self-supervisedlearning possible, and AI jumped to warp speed,” said NVIDIA founder and CEO Jensen Huang in his keynote address this week at GTC. Transformers are in many cases replacing convolutional and recurrent neural networks (CNNs and RNNs), the most popular types of deep learning models just five years ago.
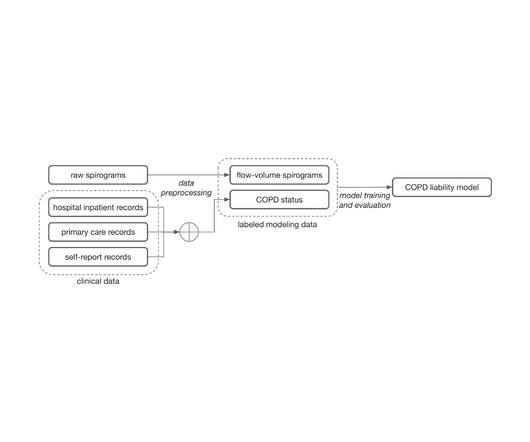
ML for deeper understanding of exhalation For this demonstration, we focused on COPD, the third leading cause of worldwide death in 2019 , in which airway inflammation and impeded airflow can progressively reduce lung function. The profile of individuals w/o COPD is different.
I generated unlabeled data for semi-supervisedlearning with Deberta-v3, then the Deberta-v3-large model was used to predict soft labels for the unlabeled data. The semi-supervisedlearning was repeated using the gemma2-9b model as the soft labeling model.
As opposed to training a model from scratch with task-specific data, which is the usual case for classical supervisedlearning, LLMs are pre-trained to extract general knowledge from a broad text dataset before being adapted to specific tasks or domains with a much smaller dataset (typically on the order of hundreds of samples).
Foundation models are large AI models trained on enormous quantities of unlabeled data—usually through self-supervisedlearning. What is self-supervisedlearning? Self-supervisedlearning is a kind of machine learning that creates labels directly from the input data. Find out in the guide below.
2019) Data Science with Python. 2019) Applied SupervisedLearning with Python. Skicit-Learn (2023): Cross-validation: evaluating estimator performance, available at: [link] [5 September 2023] WRITER at MLearning.ai / AI Agents LLM / Good-Bad AI Art / Sensory Mlearning.ai Reference: Chopra, R., England, A.
2019) Data Science with Python. 2019) Applied SupervisedLearning with Python. 2019) Python Machine Learning. References: Chopra, R., England, A. and Alaudeen, M. Packt Publishing. Available at: [link] (Accessed: 25 March 2023). Johnston, B. and Mathur, I. Packt Publishing. Raschka, S. and Mirjalili, V.
According to a 2019 survey by Deloitte , only 18% of businesses reported being able to take advantage of unstructured data. As AI adoption continues to accelerate, developing efficient mechanisms for digesting and learning from unstructured data becomes even more critical in the future.
Conclusion This article described regression which is a supervisinglearning approach. We discussed the statistical method of fitting a line in Skicit Learn. 2019) Data Science with Python. 2020) Pragmatic Machine Learning with Python. 2019) Python Machine Learning. England, A. and Alaudeen, M.
[link] David Mezzetti is the founder of NeuML, a data analytics and machine learning company that develops innovative products backed by machine learning. In August 2019, Data Works was acquired and Dave worked to ensure a successful transition. What supervisedlearning methods did you use?
Trained with reinforcement learning to generate completions that are more desired by the user. The bitter lesson and E2E models In 2019 Rich Sutton wrote an essay called “The Bitter Lesson” explaining how in the long run end-to-end AI models that leverage computation always wins against human ones that leverage human expertise.
Diffusion models, introduced in “ Deep Unsupervised Learning using Nonequilibrium Thermodynamics ” in 2015, systematically and slowly destroy structure in a data distribution through an iterative forward diffusion process. Similar updates were published in 2021 , 2020 , and 2019. Left: From I. Goodfellow, et al. Middle: From M.
Data science teams that want to further reduce the need for human labeling can employ supervised or semi-supervisedlearning methods to relabel likely-incorrect records based on the patterns set by the high-confidence data points.
Data science teams that want to further reduce the need for human labeling can employ supervised or semi-supervisedlearning methods to relabel likely-incorrect records based on the patterns set by the high-confidence data points.
Data scientists and researchers train LLMs on enormous amounts of unstructured data through self-supervisedlearning. The model then predicts the missing words (see “what is self-supervisedlearning?” OpenAI’s GPT-2, finalized in 2019 at 1.5 billion parameters, raised eyebrows by producing convincing prose.
Data scientists and researchers train LLMs on enormous amounts of unstructured data through self-supervisedlearning. The model then predicts the missing words (see “what is self-supervisedlearning?” OpenAI’s GPT-2, finalized in 2019 at 1.5 billion parameters, raised eyebrows by producing convincing prose.
It’s better than the top-word (zero temperature) case, but still at best a bit weird: This was done with the simplest GPT-2 model (from 2019). And many of the practical challenges around neural nets—and machine learning in general—center on acquiring or preparing the necessary training data. Here’s a random example.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

























Let's personalize your content