This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Liang, who began his career in smart imaging and later managed a research team, was praised for hiring top algorithm engineers and fostering a collaborative environment. The firm allocated 70% of its revenue towards AI research, building two supercomputing AI clusters, including one consisting of 10,000 Nvidia A100 chips during 2020 and 2021.
Detecting drought in January 2020 (on the left) using the EVI vegetation index Yellow means very healthy vegetation while dark green means unhealthy. Clustering similar fields using unsupervised K-means clustering The outcome of K-means clustering is cluster labels that assign each data point to one of the K clusters.
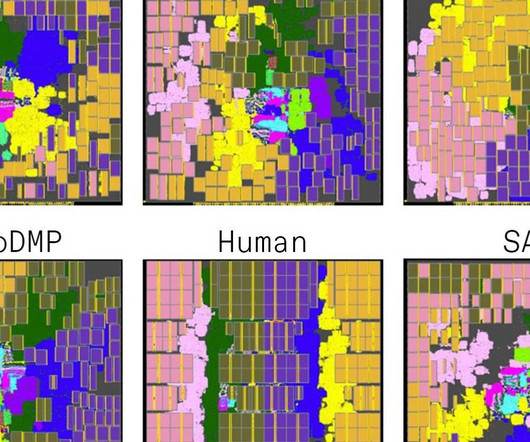
The crux of the clash was whether Google’s AI solution to one of chip design’s thornier problems was really better than humans or state-of-the-art algorithms. In Circuit Training and Morpheus, a separate algorithm fills in the gaps with the smaller parts, called standard cells. The agent places one block at a time on the chip canvas.
Yes, data created over the next three years will far exceed the amount created over the past 30 years ( Source : IDC Worldwide Global DataSphere Forecast, 2020-2024). Clustering is a technique that can be used to get a sense of the data while allowing to tell a powerful story. Introducing Multimodal Clustering. Name Clusters.
A pitch deck for Anthropic’s Series C fundraising round discloses these and other long-term goals for the company, which was founded in 2020 by former OpenAI researchers. The deck confirms that target number, though only half was raised at the time of the document’s creation from a “confidential investor.”
As a result, machine learning practitioners must spend weeks of preparation to scale their LLM workloads to large clusters of GPUs. Aligning SMP with open source PyTorch Since its launch in 2020, SMP has enabled high-performance, large-scale training on SageMaker compute instances. To mitigate this problem, SMP v2.0
it’s possible to build a robust image recognition algorithm with high accuracy. In 2020, our team launched DataRobot Visual AI. Multimodal Clustering. Multimodal Clustering provides users with a one-click, one line-of-code experience to build and deploy clustering models on any data, including images.
Keep in mind that big data drives search engines in 2020. They use a sophisticated data-driven algorithm to assess the quality of these sites based on the volume and quantity of inbound links. This algorithm is known as Google PageRank. It’s a bad idea to link from the same domain, or the same cluster of domains repeatedly.
Charting the evolution of SOTA (State-of-the-art) techniques in NLP (Natural Language Processing) over the years, highlighting the key algorithms, influential figures, and groundbreaking papers that have shaped the field. NLP algorithms help computers understand, interpret, and generate natural language.
Starting June 7th, both Falcon LLMs will also be available in Amazon SageMaker JumpStart, SageMaker’s machine learning (ML) hub that offers pre-trained models, built-in algorithms, and pre-built solution templates to help you quickly get started with ML. The model weights are available to download, inspect and deploy anywhere.
They bring deep expertise in machine learning , clustering , natural language processing , time series modelling , optimisation , hypothesis testing and deep learning to the team. This allows for a much richer interpretation of predictions, without sacrificing the algorithm’s power.
Fight sophisticated cyber attacks with AI and ML When “virtual” became the standard medium in early 2020 for business communications from board meetings to office happy hours, companies like Zoom found themselves hot in demand. They also became prime targets for the next big cyberattack.
in 2020 as a model where parametric memory is a pre-trained seq2seq model and the non-parametric memory is a dense vector index of Wikipedia, accessed with a pre-trained neural retriever. If you have a large dataset, the SageMaker KNN algorithm may provide you with an effective semantic search. For more details, see the GitHub repo.
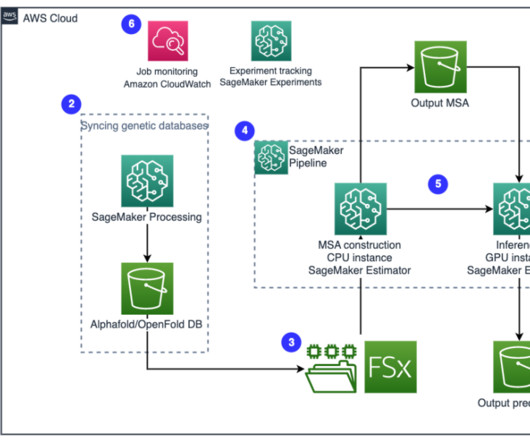
Folding algorithms like AlphaFold2 , ESMFold , OpenFold , and RoseTTAFold can be used to quickly build accurate models of protein structures. Several genetic databases are required to run AlphaFold and OpenFold algorithms, such as BFD , MGnify , PDB70 , PDB , PDB seqres , UniRef30 (FKA UniClust30) , UniProt , and UniRef90.
The following figure illustrates the idea of a large cluster of GPUs being used for learning, followed by a smaller number for inference. In 2018, other forms of PBAs became available, and by 2020, PBAs were being widely used for parallel problems, such as training of NN. The following figure illustrates the Neuron software stack.
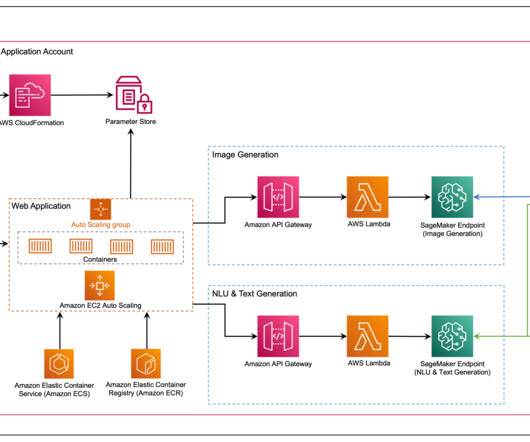
For information about how to use JumpStart models programmatically, see Use SageMaker JumpStart Algorithms with Pretrained Models. Fargate is a technology that you can use with Amazon ECS to run containers without having to manage servers or clusters or virtual machines. SubnetSelection( subnet_type=ec2.SubnetType.PRIVATE_WITH_EGRESS
Control algorithm. It provides an out-of-the-box implementation of Madgwick’s filter , an algorithm that fuses angular velocities (from the gyroscope) and linear accelerations (from the accelerometer) to compute an orientation wrt the Earth’s magnetic field. Depending on the context, this assumption may be too optimistic.
First, “Selection via Proxy,” which appeared in ICLR 2020. And please see our work, our paper “Selection via Proxy” from ICLR 2020 for more details on core-set selection, as well as all of the other datasets and methods that we tried there. I was super fortunate to work with amazing researchers from Stanford on this. AB : Got it.
First, “Selection via Proxy,” which appeared in ICLR 2020. And please see our work, our paper “Selection via Proxy” from ICLR 2020 for more details on core-set selection, as well as all of the other datasets and methods that we tried there. I was super fortunate to work with amazing researchers from Stanford on this. AB : Got it.
First, “Selection via Proxy,” which appeared in ICLR 2020. And please see our work, our paper “Selection via Proxy” from ICLR 2020 for more details on core-set selection, as well as all of the other datasets and methods that we tried there. I was super fortunate to work with amazing researchers from Stanford on this. AB : Got it.
If you’re training one model, you’re probably training a dozen — hyperparameter optimization, multi-user clusters, & iterative exploration all motivate multi-model training, blowing up compute demands further still. Industry clusters receive jobs from hundreds of users & pipelines. Second, resource apportioning.
in 2020 as a model where parametric memory is a pre-trained seq2seq model and the non-parametric memory is a dense vector index of Wikipedia, accessed with a pre-trained neural retriever. Xin Huang is a Senior Applied Scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms.
Figure 1: Netflix Recommendation System (source: “Netflix Film Recommendation Algorithm,” Pinterest ). Netflix recommendations are not just one algorithm but a collection of various state-of-the-art algorithms that serve different purposes to create the complete Netflix experience.
Automated algorithms for image segmentation have been developed based on various techniques, including clustering, thresholding, and machine learning (Arbeláez et al., Understanding the robustness of image segmentation algorithms to adversarial attacks is critical for ensuring their reliability and security in practical applications.
For a given frame, our features are inspired by the 2020 Big Data Bowl Kaggle Zoo solution ( Gordeev et al. ): we construct an image for each time step with the defensive players at the rows and offensive players at the columns. This is achieved through the Guided GradCAM algorithm ( Ramprasaath et al. ). probability.
Even for basic inference on LLM, multiple accelerators or multi-node computing clusters like multiple Kubernetes pods are required. But the issue we found was that MP is efficient in single-node clusters, but in a multi-node setting, the inference isn’t efficient. 2020 or Hoffman et al., For instance, a 1.5B
Sometimes it’s a story of creating a superalgorithm that encapsulates decades of algorithmic development. One very simple example (introduced in 2015) is Nothing : Another, introduced in 2020, is Splice : An old chestnut of Wolfram Language design concerns the way infinite evaluation loops are handled. there are 6602.
Consider a scenario where legal practitioners are armed with clever algorithms capable of analyzing, comprehending, and extracting key insights from massive collections of legal papers. Algorithms can automatically detect and extract key items. But what if there was a technique to quickly and accurately solve this language puzzle?
They possess a deep understanding of AI technologies, algorithms, and frameworks and have the ability to translate business requirements into robust AI systems. AI Engineers focus primarily on implementing and deploying AI models and algorithms, working closely with data scientists and machine learning experts.
JumpStart is the machine learning (ML) hub of Amazon SageMaker that offers a one-click access to over 350 built-in algorithms; pre-trained models from TensorFlow, PyTorch, Hugging Face, and MXNet; and pre-built solution templates. He focuses on developing scalable machine learning algorithms.
This solution includes the following components: Amazon Titan Text Embeddings is a text embeddings model that converts natural language text, including single words, phrases, or even large documents, into numerical representations that can be used to power use cases such as search, personalization, and clustering based on semantic similarity.
Iris was designed to use machine learning (ML) algorithms to predict the next steps in building a data pipeline. Since joining SnapLogic in 2010, Greg has helped design and implement several key platform features including cluster processing, big data processing, the cloud architecture, and machine learning.
In May 2020, researchers in their paper “ Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks ” explored models which combine pre-trained parametric and non-parametric memory for language generation. Faster Search Algorithm. In majority of the use-case, these costs are prohibitive. Another important consideration is cost.
The eICU data is ideal for developing ML algorithms, decision support tools, and advancing clinical research. FedML supports several out-of-the-box deep learning algorithms for various data types, such as tabular, text, image, graphs, and Internet of Things (IoT) data. 2020): e0235424. Define the model. Plos one 15.7
Organization Gigaforce Inc Industry InsurTech provider Team size Gigaforce built an ML team three years ago in 2020 and has a team size of 5-7. Team composition The team comprises domain experts, data engineers, data scientists, and ML engineers. Machine learning collaboration Gigaforce allocates work based on the phase of the project.
To make things easy, these three inputs depend solely on the model name, version (for a list of the available models, see Built-in Algorithms with pre-trained Model Table ), and the type of instance you want to train on. learning_rate – Controls the step size or learning rate of the optimization algorithm during training.
Traditional AI can recognize, classify, and cluster, but not generate the data it is trained on. Major milestones in the last few years comprised BERT (Google, 2018), GPT-3 (OpenAI, 2020), Dall-E (OpenAI, 2021), Stable Diffusion (Stability AI, LMU Munich, 2022), ChatGPT (OpenAI, 2022). Let’s play the comparison game.
To make things easy, these three inputs depend solely on the model name, version (for a list of the available models, see Built-in Algorithms with pre-trained Model Table ), and the type of instance you want to train on. learning_rate – Controls the step size or learning rate of the optimization algorithm during training.
You can see, this is a study that was done by Forrester back in 2020, and the key piece there is 14%. So you’ve got these transformer objects that can transform the data (for example, one-hot encoding), I can train an estimator, which abstracts the machine learning algorithm. And this is not just us saying it. PA : Got it.
You can see, this is a study that was done by Forrester back in 2020, and the key piece there is 14%. So you’ve got these transformer objects that can transform the data (for example, one-hot encoding), I can train an estimator, which abstracts the machine learning algorithm. And this is not just us saying it. PA : Got it.
T5 : T5 stands for Text-to-Text Transfer Transformer, developed by Google in 2020. Whether you are opting to fine-tune on a local machine or the cloud, predominant factors related to cost will be fine-tuning time, GPU clusters, and storage. You can automatically manage and monitor your clusters using AWS, GCD, or Azure.
Amazon SageMaker JumpStart is a machine learning (ML) hub offering algorithms, models, and ML solutions. Answer: 2021 ### Context: NLP Cloud developed their API by mid-2020 and they added many pre-trained open-source models since then. He focuses on developing scalable machine learning algorithms.
billion) using algorithmic trading that relied heavily on artificial intelligence. Instead of simply refining trading algorithms, they went all in on AGI. First AI cluster (2020): Built with 1,100 Nvidia A100 GPUs at a cost of 200 million yuan. At its peak, it managed nearly 100 billion yuan (about $13.79
Amazon Bedrock Knowledge Bases provides industry-leading embeddings models to enable use cases such as semantic search, RAG, classification, and clustering, to name a few, and provides multilingual support as well. data # Assing local directory path to a python variable local_data_path = ". .
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content