This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Whether it’s structured data in databases or unstructured content in document repositories, enterprises often struggle to efficiently query and use this wealth of information. The solution combines data from an Amazon Aurora MySQL-Compatible Edition database and data stored in an Amazon Simple Storage Service (Amazon S3) bucket.
Prerequisites Before proceeding with this tutorial, make sure you have the following in place: AWS account – You should have an AWS account with access to Amazon Bedrock. She speaks at internal and external conferences such AWS re:Invent, Women in Manufacturing West, YouTube webinars, and GHC 23. model in Amazon Bedrock.
The Amazon Web Services (AWS) Open Data Sponsorship Program makes high-value, cloud-optimized datasets publicly available on AWS. The full list of publicly available datasets are on the Registry of Open Data on AWS and also discoverable on the AWS Data Exchange. This quarter, AWS released 34 new or updated datasets.
Recent Announcements from Google BigQuery Easier to analyze Parquet and ORC files, a new bucketize transformation, new partitioning options AWSDatabase export to S3 Data from Amazon RDS or Aurora databases can now be exported to Amazon S3 as a Parquet file. The first course in this series should be arriving in February 2020.
In this post, we show you how SnapLogic , an AWS customer, used Amazon Bedrock to power their SnapGPT product through automated creation of these complex DSL artifacts from human language. SnapLogic background SnapLogic is an AWS customer on a mission to bring enterprise automation to the world.
In this two-part series, we demonstrate how you can deploy a cloud-based FL framework on AWS. In the second post , we present the use cases and dataset to show its effectiveness in analyzing real-world healthcare datasets, such as the eICU data , which comprises a multi-center critical care database collected from over 200 hospitals.
To mitigate these challenges, we propose a federated learning (FL) framework, based on open-source FedML on AWS, which enables analyzing sensitive HCLS data. In this two-part series, we demonstrate how you can deploy a cloud-based FL framework on AWS. In the first post , we described FL concepts and the FedML framework.
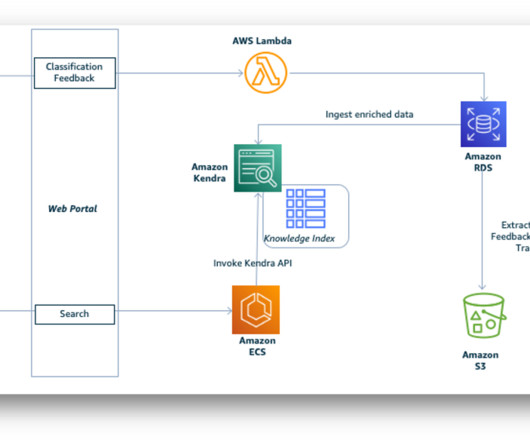
After the documents are successfully copied to the S3 bucket, the event automatically invokes an AWS Lambda The Lambda function invokes the Amazon Bedrock knowledge base API to extract embeddings—essential data representations—from the uploaded documents. Choose the AWS Region where you want to create the bucket. Choose Create bucket.
In line with this mission, Talent.com collaborated with AWS to develop a cutting-edge job recommendation engine driven by deep learning, aimed at assisting users in advancing their careers. The solution does not require porting the feature extraction code to use PySpark, as required when using AWS Glue as the ETL solution.
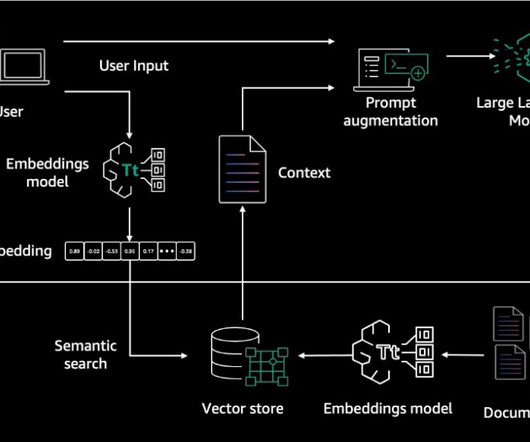
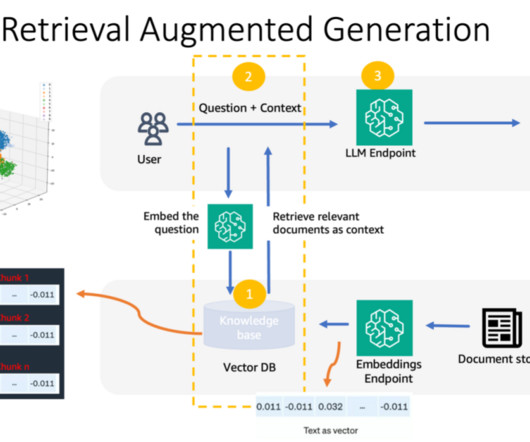
Internally, Amazon Bedrock uses embeddings stored in a vector database to augment user query context at runtime and enable a managed RAG architecture solution. The document embeddings are split into chunks and stored as indexes in a vector database. We use the Amazon letters to shareholders dataset to develop this solution.
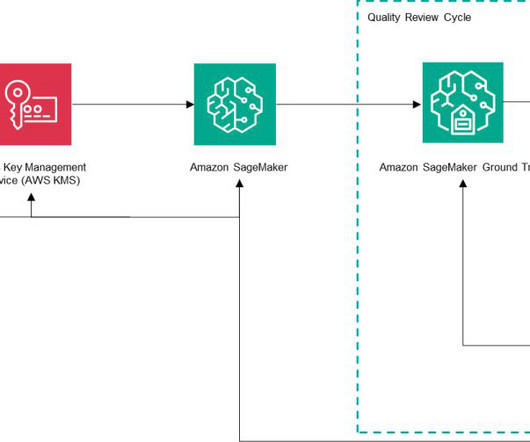
Amazon SageMaker Ground Truth is an AWS managed service that makes it straightforward and cost-effective to get high-quality labeled data for machine learning (ML) models by combining ML and expert human annotation. Overall Architecture Krikey AI built their AI-powered 3D animation platform using a comprehensive suite of AWS services.
In this post, we discuss how the IEO developed UNDP’s artificial intelligence and machine learning (ML) platform—named Artificial Intelligence for Development Analytics (AIDA)— in collaboration with AWS, UNDP’s Information and Technology Management Team (UNDP ITM), and the United Nations International Computing Centre (UNICC).
We stored the embeddings in a vector database and then used the Large Language-and-Vision Assistant (LLaVA 1.5-7b) 7b) model to generate text responses to user questions based on the most similar slide retrieved from the vector database. OpenSearch Serverless is an on-demand serverless configuration for Amazon OpenSearch Service.
The Story of the Name Patrick Lewis, lead author of the 2020 paper that coined the term , apologized for the unflattering acronym that now describes a growing family of methods across hundreds of papers and dozens of commercial services he believes represent the future of generative AI.
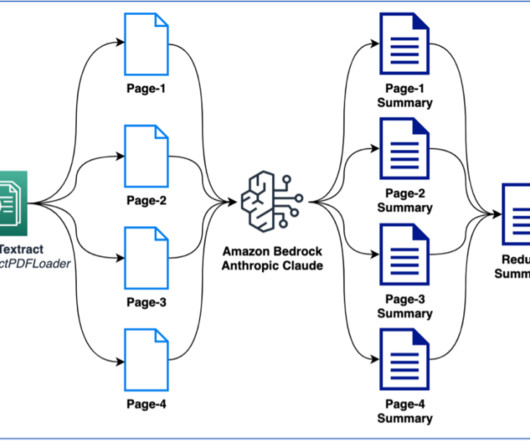
We discuss IDP in detail in our series Intelligent document processing with AWS AI services ( Part 1 and Part 2 ). This is so that the output generated using the IDP workflow can be consumed into a downstream system, for example a relational database. These embeddings are subsequently loaded into a vector database.
That’s why when it was announced that Alation achieved Amazon Web Services (AWS) Data and Analytics Competency in the data governance and security category, we were not only honored to receive this coveted designation, but we were also proud that it confirms the synergy — and customer benefits — of our AWS partnership. Amazon EMR.
Since Amazon Bedrock is serverless, customers don’t have to manage any infrastructure, and they can securely integrate and deploy generative AI capabilities into their applications using the AWS services they are already familiar with. And you can expect the same AWS access controls that you have with any other AWS service.
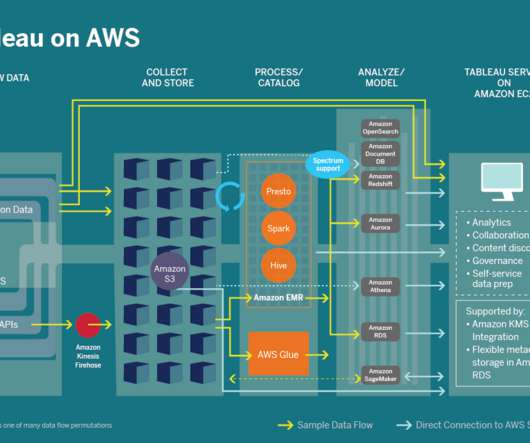
Modern Cloud Analytics (MCA) combines the resources, technical expertise, and data knowledge of Tableau, Amazon Web Services (AWS) , and our respective partner networks to help organizations maximize the value of their end-to-end data and analytics investments. Core product integration and connectivity between Tableau and AWS.
Modern Cloud Analytics (MCA) combines the resources, technical expertise, and data knowledge of Tableau, Amazon Web Services (AWS) , and our respective partner networks to help organizations maximize the value of their end-to-end data and analytics investments. Core product integration and connectivity between Tableau and AWS.
Modern Cloud Analytics (MCA) combines the resources, technical expertise, and data knowledge of Tableau, Amazon Web Services (AWS) , and our respective partner networks to help organizations maximize the value of their end-to-end data and analytics investments. Core product integration and connectivity between Tableau and AWS.
With the right underlying embedding model, capable of producing accurate semantic representations of the input document chunks and the input questions, and an efficient semantic search module, this solution is able to answer questions that require retrieving existent information in a database of documents.
With RAG, the data external to the FM and used to augment user prompts can come from multiple disparate data sources, such as document repositories, databases, or APIs. Bilal Alam is an Enterprise Solutions Architect at AWS with a focus on the Financial Services industry. Pashmeen Mistry is a Senior Product Manager at AWS.
In the RAG-based approach we convert the user question into vector embeddings using an LLM and then do a similarity search for these embeddings in a pre-populated vector database holding the embeddings for the enterprise knowledge corpus. AWS Identity and Access Management roles and policies for access management.
In 2018, other forms of PBAs became available, and by 2020, PBAs were being widely used for parallel problems, such as training of NN. Examples of other PBAs now available include AWS Inferentia and AWS Trainium , Google TPU, and Graphcore IPU. In November 2023, AWS announced the next generation Trainium2 chip.
Amazon Bedrock Knowledge Bases offers a streamlined approach to implement RAG on AWS, providing a fully managed solution for connecting FMs to custom data sources. In a RAG implementation, the knowledge retriever might use a database that supports vector searches to dynamically look up relevant documents that serve as the knowledge source.
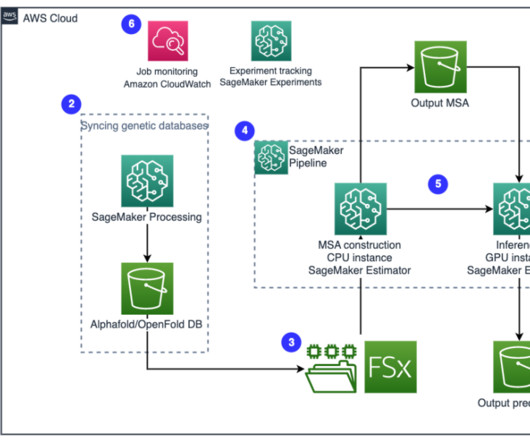
Genetic databases – A genetic database is one or more sets of genetic data stored together with software to enable users to retrieve genetic data. Several genetic databases are required to run AlphaFold and OpenFold algorithms, such as BFD , MGnify , PDB70 , PDB , PDB seqres , UniRef30 (FKA UniClust30) , UniProt , and UniRef90.
introduced RAG models in 2020, conceptualizing them as a fusion of a pre-trained sequence-to-sequence model (parametric memory) and a dense vector index of Wikipedia (non-parametric memory) accessed via a neural retriever. About the authors Sunil Padmanabhan is a Startup Solutions Architect at AWS. Lewis et al.
Though 2020 was challenging and full of change, one constant was our committed work with our partner Snowflake on behalf of our mutual customers. In particular, 2020 was a big year for our work together. we were proud to announce OAuth support for authenticatication via AWS Private Link and Azure Private Link.
BUILDING EARTH OBSERVATION DATA CUBES ON AWS. AWS , GCP , Azure , CreoDIAS , for example, are not open-source, nor are they “standard”. Big ones can: AWS is benefiting a lot from these concepts. F., & Costa, R. The International Archives of Photogrammetry, Remote Sensing and Spatial Information Sciences, 43, 597–602.
For example, a health insurance company may want their question answering bot to answer questions using the latest information stored in their enterprise document repository or database, so the answers are accurate and reflect their unique business rules. RAG models were introduced by Lewis et al. For more details, see the GitHub repo.
Internet companies like Amazon led the charge with the introduction of Amazon Web Services (AWS) in 2002, which offered businesses cloud-based storage and computing services, and the launch of Elastic Compute Cloud (EC2) in 2006, which allowed users to rent virtual computers to run their own applications. Google Workspace, Salesforce).
Though 2020 was challenging and full of change, one constant was our committed work with our partner Snowflake on behalf of our mutual customers. In particular, 2020 was a big year for our work together. we were proud to announce OAuth support for authenticatication via AWS Private Link and Azure Private Link.
Netezza Performance Server (NPS) has recently added the ability to access Parquet files by defining a Parquet file as an external table in the database. All SQL and Python code is executed against the NPS database using Jupyter notebooks, which capture query output and graphing of results during the analysis phase of the demonstration.
These services include things like virtual machines, storage, databases, networks, and tools for artificial intelligence and the Internet of Things. The global cloud computing market is expected to grow at a CAGR of over 17% during the period 2020-2025. What is Cloud Computing? It is managed by a cloud service provider.
Having gone public in 2020 with the largest tech IPO in history, Snowflake continues to grow rapidly as organizations move to the cloud for their data warehousing needs. Importing data allows you to ingest a copy of the source data into an in-memory database.
c/o Ernst & Young LLPSeattle, Washington Attention: Corporate Secretary (2) For the purpose of Article III of the Securities Exchange Act of 1934, the registrant’s name and address are as follows:(3) The registrant’s Exchange Act reportable time period is from and includingJanuary 1, 2020 to the present.(4)
T5 : T5 stands for Text-to-Text Transfer Transformer, developed by Google in 2020. Data is chunked into smaller pieces and stored in a vector database, enabling efficient retrieval based on semantic similarity. VDB service providers can charge based on the requirements, with costs varying by data volume and database choice.
c/o Ernst & Young LLPSeattle, Washington Attention: Corporate Secretary (2) For the purpose of Article III of the Securities Exchange Act of 1934, the registrant’s name and address are as follows:(3) The registrant’s Exchange Act reportable time period is from and includingJanuary 1, 2020 to the present.(4)
Next, OpenAI released GPT-3 in June of 2020. LLaMA wasn’t a direct duplication of GPT-3 (Meta AI had introduced their direct GPT-3 clone, OPT-175B , in May of 2020). The plot was boring and the acting was awful: Negative This movie was okay. At 175 billion parameters, GPT-3 set the new size standard for large language models.
Next, OpenAI released GPT-3 in June of 2020. LLaMA wasn’t a direct duplication of GPT-3 (Meta AI had introduced their direct GPT-3 clone, OPT-175B , in May of 2020). The plot was boring and the acting was awful: Negative This movie was okay. At 175 billion parameters, GPT-3 set the new size standard for large language models.
In this blog post, we will show you how to leverage AI21 Labs’ Task-Specific Models (TSMs) on AWS to enhance your business operations. You will learn the steps to subscribe to AI21 Labs in the AWS Marketplace, set up a domain in Amazon SageMaker, and utilize AI21 TSMs via SageMaker JumpStart. Limits are account and resource specific.
In this blog post, we will showcase how IBM Consulting is partnering with AWS and leveraging Large Language Models (LLMs), on IBM Consulting’s generative AI-Automation platform (ATOM), to create industry-aware, life sciences domain-trained foundation models to generate first drafts of the narrative documents, with an aim to assist human teams.
The AWS global backbone network is the critical foundation enabling reliable and secure service delivery across AWS Regions. Specifically, we need to predict how changes to one part of the AWS global backbone network might affect traffic patterns and performance across the entire system.
This post dives deep into Amazon Bedrock Knowledge Bases , which helps with the storage and retrieval of data in vector databases for RAG-based workflows, with the objective to improve large language model (LLM) responses for inference involving an organization’s datasets.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content