This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Under Settings , enter a name for your database cluster identifier. You can verify the output by cross-referencing the PDF, which has a target as $12 million for the in-store sales channel in 2020. Delete the Aurora MySQL instance and Aurora cluster. Choose Create database. Select Aurora , then Aurora (MySQL compatible).
The firm allocated 70% of its revenue towards AI research, building two supercomputing AI clusters, including one consisting of 10,000 Nvidia A100 chips during 2020 and 2021. banned A100 chip exports to China in 2022.
Within a year, we built a world-class inference platform processing over 2 billion video frames daily using dynamically scaled Amazon Elastic Kubernetes Service (Amazon EKS) clusters. Despite this, exciting events like the AWS DeepRacer F1 Pro-Am kept the community engaged.
Software businesses are using Hadoop clusters on a more regular basis now. The post Big Data Skill sets that Software Developers will Need in 2020 appeared first on SmartData Collective. They’re looking to hire experienced data analysts, data scientists and data engineers.
Yes, data created over the next three years will far exceed the amount created over the past 30 years ( Source : IDC Worldwide Global DataSphere Forecast, 2020-2024). Clustering is a technique that can be used to get a sense of the data while allowing to tell a powerful story. Introducing Multimodal Clustering. Name Clusters.
ACK allows you to take advantage of managed model building pipelines without needing to define resources outside of the Kubernetes cluster. Prerequisites To follow along, you should have the following prerequisites: An EKS cluster where the ML pipeline will be created. kubectl for working with Kubernetes clusters.
Detecting drought in January 2020 (on the left) using the EVI vegetation index Yellow means very healthy vegetation while dark green means unhealthy. Clustering similar fields using unsupervised K-means clustering The outcome of K-means clustering is cluster labels that assign each data point to one of the K clusters.
Authors of AntMan [1] propose a deep learning infrastructure, which is a co-design of cluster schedulers (e.g., Their motivation for this work was their observation on very low GPU utilization on Alibaba cluster. On the other hands, the second kind is for getting more out of the clusters. Kubernetes, SLURM, LSF etc.)
As a result, machine learning practitioners must spend weeks of preparation to scale their LLM workloads to large clusters of GPUs. Aligning SMP with open source PyTorch Since its launch in 2020, SMP has enabled high-performance, large-scale training on SageMaker compute instances. To mitigate this problem, SMP v2.0
Among these models, the spatial fixed effect model yielded the highest mean R-squared value, particularly for the timeframe spanning 2014 to 2020. SageMaker Processing enables the flexible scaling of compute clusters to accommodate tasks of varying sizes, from processing a single city block to managing planetary-scale workloads.
Temperature observation at 1pm UTC on June 15, 2020 Wind speed observation at 1pm UTC on June 15, 2020 Data usage Most of our clients use weather data as a variable in their linear regression model and other machine learning models. June 2020 is ~540 GB). Please, note the projection issue was left out for simplicity.
There were 4 clusters of users that this report broke down to understand the behavior and tendencies of different users. Cluster 2 : Swap Count : Extremely High (around 54,127 swaps on average) Volume in USD : Extremely High (around $4.43 Cluster 3 : Swap Count : Low (around 10 swaps on average) Volume in USD : Moderate (around $60.25
A pitch deck for Anthropic’s Series C fundraising round discloses these and other long-term goals for the company, which was founded in 2020 by former OpenAI researchers. “These models could begin to automate large portions of the economy,” the pitch deck reads.
In 2020, our team launched DataRobot Visual AI. Multimodal Clustering. Multimodal Clustering provides users with a one-click, one line-of-code experience to build and deploy clustering models on any data, including images. Image recognition has a lot of applications in industries and businesses. DataRobot Visual AI.
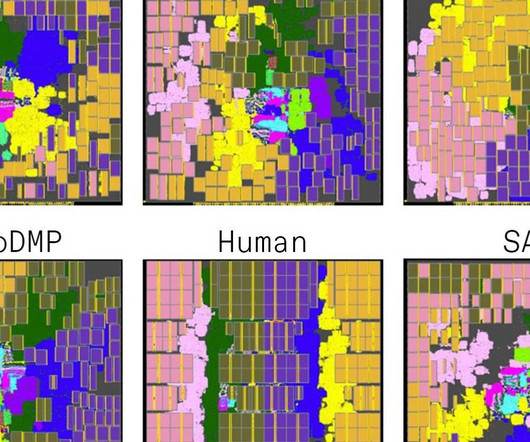
The standard cells are then collected into clusters to help speed up the training process. Recall that, as a preprocessing step, the reinforcement learning method gathers up the standard cells into clusters. Circuit Training then starts placing the macros on the chip “canvas” one at a time.
Businesses today rely on real-time big data analytics to handle the vast and complex clusters of datasets. From 2010 to 2020, there has been a 5000% growth in the quantity of data created, captured, and […] Here’s the state of big data today: The forecasted market value of big data will reach $650 billion by 2029.
The Story of the Name Patrick Lewis, lead author of the 2020 paper that coined the term , apologized for the unflattering acronym that now describes a growing family of methods across hundreds of papers and dozens of commercial services he believes represent the future of generative AI.
In early 2020, research organizations across the world set the emphasis on model size, observing that accuracy correlated with number of parameters. For example, GPT-3 (2020) and BLOOM (2022) feature around 175 billion parameters, Gopher (2021) has 230 billion parameters, and MT-NLG (2021) 530 billion parameters.
In fact, studies by the Gigabit Magazine depict that the amount of data generated in 2020 will be over 25 times greater than it was 10 years ago. sThe recent years have seen a tremendous surge in data generation levels , characterized by the dramatic digital transformation occurring in myriad enterprises across the industrial landscape.
Keep in mind that big data drives search engines in 2020. It’s a bad idea to link from the same domain, or the same cluster of domains repeatedly. Big data is critical for linkbuilding in 2020. Offsite tactics, like link building, are designed to increase the relative trustworthiness of your site. Determine the quality of links.
The Snowflake Data Cloud was unveiled in 2020 as the next iteration of Snowflake’s journey to simplify how organizations interact with their data. What is the Snowflake Data Cloud? The Data Cloud applies technology to solve data problems that exist with every customer, namely; availability, performance, and access.
They also recently showed off a full HCI cluster running on an Intel NUC. Links: Steve's Forbes Column on Scale Computing Moor Insights & Strategy Qualitative Report of Scale Computing's HC3 HCI Solution Scale Computing's January 2020 Announcement of 2019 Performance Scale Computing is a pioneer in HCI (inventing, in fact, the very term).
Since 2020, Ubotica has been providing space AI capabilities to the European Space Agency and NASA JPL. The initial install is a Red Hat OpenShift Kubernetes Service (ROKS) cluster , on which Ubotica will be deploying components to create a hybrid cloud AI platform.
The strategic value of IoT development and data analytics Sierra Wireless Sierra Wireless , a wireless communications equipment designer and service provider, has been honing its focus on IoT software and managed services following its acquisition of M2M Group, a cluster of companies dedicated to IoT connectivity, in 2020.
In 2022, security wasn’t in the news as often as it was in 2020 and 2021. Some alternatives have appeared, including managed Kubernetes, where you delegate management of your cluster to a third party, typically your cloud provider; HashiCorp’s Nomad ; K3S , a lightweight Kubernetes; and even some older tools like Docker Swarm.
They bring deep expertise in machine learning , clustering , natural language processing , time series modelling , optimisation , hypothesis testing and deep learning to the team. The most common data science languages are Python and R — SQL is also a must have skill for acquiring and manipulating data.
Fargate is a technology that you can use with Amazon ECS to run containers without having to manage servers or clusters or virtual machines. On the Amazon ECS console, you can see the clusters on the Clusters page. Model data is stored on Amazon Simple Storage Service (Amazon S3) in the JumpStart account. for the full code.
Building on In-House Hardware Conformer-2 was trained on our own GPU compute cluster of 80GB-A100s. To do this, we deployed a fault-tolerant and highly scalable cluster management and job scheduling Slurm scheduler, capable of managing resources in the cluster, recovering from failures, and adding or removing specific nodes.
These embeddings are useful for various natural language processing (NLP) tasks such as text classification, clustering, semantic search, and information retrieval. For this demonstration, we use a public Amazon product dataset called Amazon Product Dataset 2020 from a kaggle competition.
A several-years-old analysis by Andy Jones at Anthropic postulated that we were then (in 2020) capable of building orders-of-magnitude larger models than those which had been built at that point. Jones' analysis was heavily informed by a paper [ 3 ] from OpenAI, released in 2020, on scaling laws for neural language models.
The model is trained on gameplay data from Bleeding Edge, a 2020 multiplayer game developed by NinjaTheory. Researchers initially used a V100 GPU cluster before transitioning to H100 GPUs, enabling the model to generate higher-resolution visuals (300180 pixels) and operate across all seven maps in BleedingEdge.
Learn the basics of verifying segmentation, analyzing the data, and creating segments in this tutorial. When reviewing survey data, you will typically be handed Likert questions (e.g., on a scale of 1 to 5), and by using a few techniques, you can verify the quality of the survey and start grouping respondents into populations.
Fight sophisticated cyber attacks with AI and ML When “virtual” became the standard medium in early 2020 for business communications from board meetings to office happy hours, companies like Zoom found themselves hot in demand. They also became prime targets for the next big cyberattack.
in 2020 as a model where parametric memory is a pre-trained seq2seq model and the non-parametric memory is a dense vector index of Wikipedia, accessed with a pre-trained neural retriever. RAG models were introduced by Lewis et al. Each node also uses Python multiprocessing to internally also parallelize the file processing.
Since its launch in 2020, DATA ONE has been successfully adopted by multinational companies across sectors, including insurance and banking, automotive, energy and utilities, manufacturing, logistics and telco. Nodes are grouped together in homogeneous clusters, but different clusters can be optimized for different types of workloads.
If you’re training one model, you’re probably training a dozen — hyperparameter optimization, multi-user clusters, & iterative exploration all motivate multi-model training, blowing up compute demands further still. Industry clusters receive jobs from hundreds of users & pipelines. Second, resource apportioning.
HPC clusters have been coming to the attention of people to do their training on them and they tend to use those major frameworks and target nodes with more than one GPU. arXiv preprint arXiv:2012.00825 (2020). [2] ABCI supercomputer ( Japan ): consisting of 1088 nodes of FUJITSU server PRIMERGY CX2570 M4.
For example, rising interest rates and falling equities already in 2013 and again in 2020 and 2022 led to drawdowns of risk parity schemes. In 2023-Q1, we even saw failing banks like SVB simply because of investments in “safe” treasury bonds.
For a given frame, our features are inspired by the 2020 Big Data Bowl Kaggle Zoo solution ( Gordeev et al. ): we construct an image for each time step with the defensive players at the rows and offensive players at the columns. He started at the NFL in February 2020 as a Data Scientist and was promoted to his current role in December 2021.
The following figure illustrates the idea of a large cluster of GPUs being used for learning, followed by a smaller number for inference. In 2018, other forms of PBAs became available, and by 2020, PBAs were being widely used for parallel problems, such as training of NN.
2020) “GPT-4 Technical report ” by Open AI. Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM ” by Deepak Narayanan et al. Use Cases :Language Modeling, Question Answering, Text Generation Significant papers: “Attention is all you need” by Vaswani et al.
First, “Selection via Proxy,” which appeared in ICLR 2020. And please see our work, our paper “Selection via Proxy” from ICLR 2020 for more details on core-set selection, as well as all of the other datasets and methods that we tried there. I was super fortunate to work with amazing researchers from Stanford on this.
First, “Selection via Proxy,” which appeared in ICLR 2020. And please see our work, our paper “Selection via Proxy” from ICLR 2020 for more details on core-set selection, as well as all of the other datasets and methods that we tried there. I was super fortunate to work with amazing researchers from Stanford on this.
First, “Selection via Proxy,” which appeared in ICLR 2020. And please see our work, our paper “Selection via Proxy” from ICLR 2020 for more details on core-set selection, as well as all of the other datasets and methods that we tried there. I was super fortunate to work with amazing researchers from Stanford on this.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content