This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction GPUs as main accelerators for deeplearning training tasks suffer from under-utilization. Authors of AntMan [1] propose a deeplearning infrastructure, which is a co-design of cluster schedulers (e.g., with deeplearning frameworks (e.g., with deeplearning frameworks (e.g.,
As a result, machine learning practitioners must spend weeks of preparation to scale their LLM workloads to large clusters of GPUs. Aligning SMP with open source PyTorch Since its launch in 2020, SMP has enabled high-performance, large-scale training on SageMaker compute instances. To mitigate this problem, SMP v2.0
Image recognition is one of the most relevant areas of machine learning. Deeplearning makes the process efficient. However, not everyone has deeplearning skills or budget resources to spend on GPUs before demonstrating any value to the business. In 2020, our team launched DataRobot Visual AI.
The Story of the Name Patrick Lewis, lead author of the 2020 paper that coined the term , apologized for the unflattering acronym that now describes a growing family of methods across hundreds of papers and dozens of commercial services he believes represent the future of generative AI.
Introduction Deeplearning tasks usually demand high computation/memory requirements and their computations are embarrassingly parallel. The paper claims that distributed training has been facilitated by deeplearning frameworks, but fault tolerance did not get enough attention.
Due to their size and the volume of training data they interact with, LLMs have impressive text processing abilities, including summarization, question answering, in-context learning, and more. In early 2020, research organizations across the world set the emphasis on model size, observing that accuracy correlated with number of parameters.
DeepLearning (Late 2000s — early 2010s) With the evolution of needing to solve more complex and non-linear tasks, The human understanding of how to model for machine learning evolved. 2017) “ BERT: Pre-training of deep bidirectional transformers for language understanding ” by Devlin et al.
They bring deep expertise in machine learning , clustering , natural language processing , time series modelling , optimisation , hypothesis testing and deeplearning to the team. The most common data science languages are Python and R — SQL is also a must have skill for acquiring and manipulating data.
Learning means identifying and capturing historical patterns from the data, and inference means mapping a current value to the historical pattern. The following figure illustrates the idea of a large cluster of GPUs being used for learning, followed by a smaller number for inference.
Traditional AI can recognize, classify, and cluster, but not generate the data it is trained on. Major milestones in the last few years comprised BERT (Google, 2018), GPT-3 (OpenAI, 2020), Dall-E (OpenAI, 2021), Stable Diffusion (Stability AI, LMU Munich, 2022), ChatGPT (OpenAI, 2022). Deeplearning neural network.
A several-years-old analysis by Andy Jones at Anthropic postulated that we were then (in 2020) capable of building orders-of-magnitude larger models than those which had been built at that point. Jones' analysis was heavily informed by a paper [ 3 ] from OpenAI, released in 2020, on scaling laws for neural language models.
The unprecedented amount of available data has been critical to many of deeplearning’s recent successes, but this big data brings its own problems. Active learning is a really powerful data selection technique for reducing labeling costs. First, “Selection via Proxy,” which appeared in ICLR 2020.
The unprecedented amount of available data has been critical to many of deeplearning’s recent successes, but this big data brings its own problems. Active learning is a really powerful data selection technique for reducing labeling costs. First, “Selection via Proxy,” which appeared in ICLR 2020.
The unprecedented amount of available data has been critical to many of deeplearning’s recent successes, but this big data brings its own problems. Active learning is a really powerful data selection technique for reducing labeling costs. First, “Selection via Proxy,” which appeared in ICLR 2020.
Sentence transformers are powerful deeplearning models that convert sentences into high-quality, fixed-length embeddings, capturing their semantic meaning. These embeddings are useful for various natural language processing (NLP) tasks such as text classification, clustering, semantic search, and information retrieval.
Fight sophisticated cyber attacks with AI and ML When “virtual” became the standard medium in early 2020 for business communications from board meetings to office happy hours, companies like Zoom found themselves hot in demand. They also became prime targets for the next big cyberattack.
Image Source: NVIDIA A100 — The Revolution in High-Performance Computing The A100 is the pioneer of NVIDIA’s Ampere architecture and emerged as a GPU that redefined computing capability when it was introduced in the first half of 2020. The H100 pioneered AI computing with its capability of machine learning and deeplearning workloads.
Figure 2: Multi-dimensionality of Netflix recommendation system (source: Basilico, “Recent Trends in Personalization at Netflix,” NeurIPS , 2020 ). These features can be simple metadata or model-based features (extracted from a deeplearning model), representing how good that video is for a member.
Similar to the rest of the industry, the advancements of accelerated hardware have allowed Amazon teams to pursue model architectures using neural networks and deeplearning (DL). He focuses on building systems and tooling for scalable distributed deeplearning training and real time inference.
Even for basic inference on LLM, multiple accelerators or multi-node computing clusters like multiple Kubernetes pods are required. But the issue we found was that MP is efficient in single-node clusters, but in a multi-node setting, the inference isn’t efficient. 2020 or Hoffman et al., For instance, a 1.5B
in 2020 as a model where parametric memory is a pre-trained seq2seq model and the non-parametric memory is a dense vector index of Wikipedia, accessed with a pre-trained neural retriever. He focuses on developing scalable machine learning algorithms. RAG models were introduced by Lewis et al.
Automated algorithms for image segmentation have been developed based on various techniques, including clustering, thresholding, and machine learning (Arbeláez et al., 2019) proposed a novel adversarial training framework for improving the robustness of deeplearning-based segmentation models. 2018; Sitawarin et al.,
For a given frame, our features are inspired by the 2020 Big Data Bowl Kaggle Zoo solution ( Gordeev et al. ): we construct an image for each time step with the defensive players at the rows and offensive players at the columns. Haibo Ding is a senior applied scientist at Amazon Machine Learning Solutions Lab.
Gain hands-on experience in implementing algorithms and working with AI frameworks such as TensorFlow , PyTorch, or scikit-learn. Learn Machine Learning and DeepLearning Deepen your understanding of machine learning algorithms, statistical modelling, and deeplearning architectures.
Image by Author Large Language Models (LLMs) entered the spotlight with the release of OpenAI’s GPT-3 in 2020. Document Retrieval and Clustering: LangChain can simplify retrieval and clustering using embedding models. We have seen exploding interest in LLMs and in a broader discipline, Generative AI. models by OpenAI.
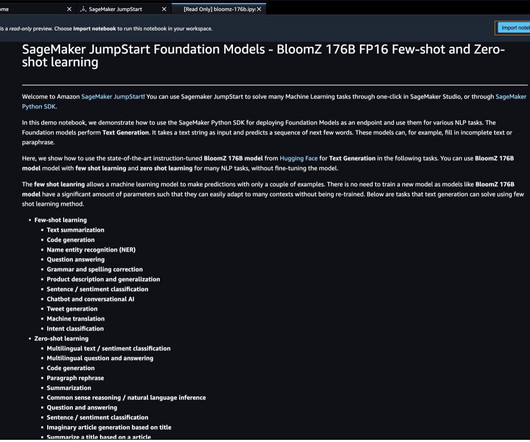
Answer: 2021 ### Context: NLP Cloud developed their API by mid-2020 and they added many pre-trained open-source models since then. For details, refer to Deploy BLOOM-176B and OPT-30B on Amazon SageMaker with large model inference DeepLearning Containers and DeepSpeed. Question: When was NLP Cloud founded?
FedML supports several out-of-the-box deeplearning algorithms for various data types, such as tabular, text, image, graphs, and Internet of Things (IoT) data. Benchmarking machine learning models on multi-centre eICU critical care dataset.” 2020): e0235424. Define the model. ACM Computing Surveys (CSUR) , 54 (6), pp.1-36.
One of the major challenges in training and deploying LLMs with billions of parameters is their size, which can make it difficult to fit them into single GPUs, the hardware commonly used for deeplearning. He focuses on developing scalable machine learning algorithms. Outside of work, he enjoys running and hiking.
The Challenge Make LLMs respond with up-to-date information Make LLMs not respond with factually inaccurate information Make LLMs aware of proprietary information Providing Context While model re-training/fine-tuning/reinforcement learning are options that solve the aforementioned challenges, these approaches are time-consuming and costly.
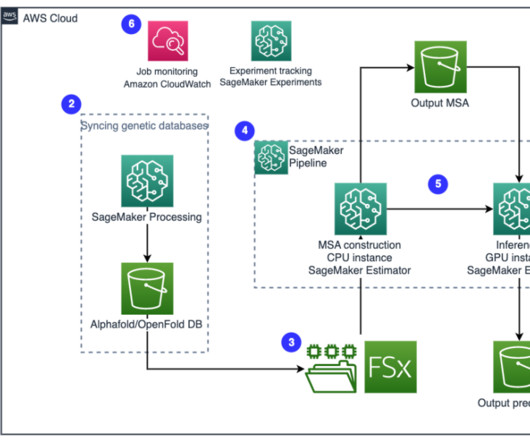
Recent advances in deeplearning methods for protein research have shown promise in using neural networks to predict protein folding with remarkable accuracy. With SageMaker Processing, you can run a long-running job with a proper compute without setting up any compute cluster and storage and without needing to shut down the cluster.
in 2020 as a model where parametric memory is a pre-trained seq2seq model and the non-parametric memory is a dense vector index of Wikipedia, accessed with a pre-trained neural retriever. He focuses on developing scalable machine learning algorithms. RAG models were introduced by Lewis et al.
These algorithms help legal professionals swiftly discover essential information, speed up document review, and assure comprehensive case analysis through approaches such as document clustering and topic modeling. Natural language processing and machine learning as practical toolsets for archival processing.
A myriad of instruction tuning research has been performed since 2020, producing a collection of various tasks, templates, and methods. He focuses on developing scalable machine learning algorithms. Vivek Gangasani is a Senior Machine Learning Solutions Architect at Amazon Web Services.
You could imagine, for deeplearning, you need, really, a lot of examples. So, deeplearning, similarity search is a very easy, simple, task. We’ll solve this with self-supervised learning, which is basically the [research] area catching on fire since 2020 onward when Google released the SimCLR.
You could imagine, for deeplearning, you need, really, a lot of examples. So, deeplearning, similarity search is a very easy, simple, task. We’ll solve this with self-supervised learning, which is basically the [research] area catching on fire since 2020 onward when Google released the SimCLR.
One of the major challenges in training and deploying LLMs with billions of parameters is their size, which can make it difficult to fit them into single GPUs, the hardware commonly used for deeplearning. He focuses on developing scalable machine learning algorithms. Outside of work, he enjoys running and hiking.
Model scale has become an absolutely essential aspect of modern deeplearning practice. And if there’s one thing we’ve learned from our collaborations at UCSD and with our industry partners, it’s that deeplearning jobs are never run in isolation. Language Models are Few-Shot Learners (Brown et al.,
Redmon and Farhadi (2017) published YOLOv2 at the CVPR Conference and improved the original model by incorporating batch normalization, anchor boxes, and dimension clusters. Do you think learning computer vision and deeplearning has to be time-consuming, overwhelming, and complicated? The authors continued from there.
Amazon Bedrock Knowledge Bases provides industry-leading embeddings models to enable use cases such as semantic search, RAG, classification, and clustering, to name a few, and provides multilingual support as well. data # Assing local directory path to a python variable local_data_path = ". .
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content