This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
At the time, I knew little about AI or machine learning (ML). But AWS DeepRacer instantly captured my interest with its promise that even inexperienced developers could get involved in AI and ML. Panic set in as we realized we would be competing on stage in front of thousands of people while knowing little about ML.
Its scalability and load-balancing capabilities make it ideal for handling the variable workloads typical of machine learning (ML) applications. Amazon SageMaker provides capabilities to remove the undifferentiated heavy lifting of building and deploying ML models. kubectl for working with Kubernetes clusters.
SageMaker geospatial capabilities make it straightforward for data scientists and machine learning (ML) engineers to build, train, and deploy models using geospatial data. Among these models, the spatial fixed effect model yielded the highest mean R-squared value, particularly for the timeframe spanning 2014 to 2020.
The onset of the pandemic has triggered a rapid increase in the demand and adoption of ML technology. Building ML team Following the surge in ML use cases that have the potential to transform business, the leaders are making a significant investment in ML collaboration, building teams that can deliver the promise of machine learning.
They bring deep expertise in machine learning , clustering , natural language processing , time series modelling , optimisation , hypothesis testing and deep learning to the team. Machine Learning In this section, we look beyond ‘standard’ ML practices and explore the 6 ML trends that will set you apart from the pack in 2021.
Be sure to check out his talk, “ ML Applications in Asset Allocation and Portfolio Management ,” there! For example, rising interest rates and falling equities already in 2013 and again in 2020 and 2022 led to drawdowns of risk parity schemes. Editor’s note: Peter Schwendner, PhD is a speaker for ODSC Europe this June.
Authors of AntMan [1] propose a deep learning infrastructure, which is a co-design of cluster schedulers (e.g., Their motivation for this work was their observation on very low GPU utilization on Alibaba cluster. On the other hands, the second kind is for getting more out of the clusters. Kubernetes, SLURM, LSF etc.)
Starting June 7th, both Falcon LLMs will also be available in Amazon SageMaker JumpStart, SageMaker’s machine learning (ML) hub that offers pre-trained models, built-in algorithms, and pre-built solution templates to help you quickly get started with ML. 24xlarge instances, cumulating in 384 NVIDIA A100 GPUs.
The seeds of a machine learning (ML) paradigm shift have existed for decades, but with the ready availability of virtually infinite compute capacity, a massive proliferation of data, and the rapid advancement of ML technologies, customers across industries are rapidly adopting and using ML technologies to transform their businesses.
In fact, studies by the Gigabit Magazine depict that the amount of data generated in 2020 will be over 25 times greater than it was 10 years ago. New data warehousing architectures will act as the foundation of AI data sets, with AI and ML improving the capabilities and operations of these business intelligence solutions.
Clustered under visual encoding , we have topics of self-service analysis , authoring , and computer assistance. May 2020) shifted sheets to a multiple-table data model, where the sheet’s fields allow the computer to write much more efficient queries to the data sources. Gestalt properties including clusters are salient on scatters.
These activities cover disparate fields such as basic data processing, analytics, and machine learning (ML). ML is often associated with PBAs, so we start this post with an illustrative figure. The ML paradigm is learning followed by inference. The union of advances in hardware and ML has led us to the current day.
Through a collaboration between the Next Gen Stats team and the Amazon ML Solutions Lab , we have developed the machine learning (ML)-powered stat of coverage classification that accurately identifies the defense coverage scheme based on the player tracking data. In this post, we deep dive into the technical details of this ML model.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody. Everybody can train a model.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody. Everybody can train a model.
This solution includes the following components: Amazon Titan Text Embeddings is a text embeddings model that converts natural language text, including single words, phrases, or even large documents, into numerical representations that can be used to power use cases such as search, personalization, and clustering based on semantic similarity.
Fight sophisticated cyber attacks with AI and ML When “virtual” became the standard medium in early 2020 for business communications from board meetings to office happy hours, companies like Zoom found themselves hot in demand. There is also concern that attackers are using AI and ML technology to launch smarter, more advanced attacks.
Clustered under visual encoding , we have topics of self-service analysis , authoring , and computer assistance. May 2020) shifted sheets to a multiple-table data model, where the sheet’s fields allow the computer to write much more efficient queries to the data sources. Gestalt properties including clusters are salient on scatters.
These embeddings are useful for various natural language processing (NLP) tasks such as text classification, clustering, semantic search, and information retrieval. For this demonstration, we use a public Amazon product dataset called Amazon Product Dataset 2020 from a kaggle competition.
For decades, Amazon has pioneered and innovated machine learning (ML), bringing delightful experiences to its customers. From the earliest days, Amazon has used ML for various use cases such as book recommendations, search, and fraud detection. In order to achieve this, the M5 team regularly evaluates new techniques to reduce cost.
It involves training a global machine learning (ML) model from distributed health data held locally at different sites. The eICU data is ideal for developing ML algorithms, decision support tools, and advancing clinical research. Training ML models with a single data point at a time is tedious and time-consuming.
Machine learning (ML) methods can help identify suitable compounds at each stage in the drug discovery process, resulting in more streamlined drug prioritization and testing, saving billions in drug development costs (for more information, refer to AI in biopharma research: A time to focus and scale ). that runs run_alphafold.py
in 2020 as a model where parametric memory is a pre-trained seq2seq model and the non-parametric memory is a dense vector index of Wikipedia, accessed with a pre-trained neural retriever. RAG models were introduced by Lewis et al. Each node also uses Python multiprocessing to internally also parallelize the file processing.
We’ll solve this with self-supervised learning, which is basically the [research] area catching on fire since 2020 onward when Google released the SimCLR. This is the example from California from 2020. It just happened that when the system started clustering the images, it started to make some sort of a sense.
We’ll solve this with self-supervised learning, which is basically the [research] area catching on fire since 2020 onward when Google released the SimCLR. This is the example from California from 2020. It just happened that when the system started clustering the images, it started to make some sort of a sense.
In this article, we’ll look at the evolution of these state-of-the-art (SOTA) models and algorithms, the ML techniques behind them, the people who envisioned them, and the papers that introduced them. 2020) “GPT-4 Technical report ” by Open AI. 2018) “ Language models are few-shot learners ” by Brown et al.
Iris was designed to use machine learning (ML) algorithms to predict the next steps in building a data pipeline. Since joining SnapLogic in 2010, Greg has helped design and implement several key platform features including cluster processing, big data processing, the cloud architecture, and machine learning.
JumpStart is a machine learning (ML) hub that can help you accelerate your ML journey. in 2020 as a model where parametric memory is a pre-trained seq2seq model and the non-parametric memory is a dense vector index of Wikipedia, accessed with a pre-trained neural retriever. RAG models were introduced by Lewis et al.
I’m Cody Coleman and I’m really excited to share my research on how careful data selection can make ML development faster, cheaper, and better by focusing on quality rather than quantity. First, “Selection via Proxy,” which appeared in ICLR 2020. I’m super excited to chat with you all today. of the unlabeled data.
I’m Cody Coleman and I’m really excited to share my research on how careful data selection can make ML development faster, cheaper, and better by focusing on quality rather than quantity. First, “Selection via Proxy,” which appeared in ICLR 2020. I’m super excited to chat with you all today. of the unlabeled data.
I’m Cody Coleman and I’m really excited to share my research on how careful data selection can make ML development faster, cheaper, and better by focusing on quality rather than quantity. First, “Selection via Proxy,” which appeared in ICLR 2020. I’m super excited to chat with you all today. of the unlabeled data.
HPC clusters have been coming to the attention of people to do their training on them and they tend to use those major frameworks and target nodes with more than one GPU. arXiv preprint arXiv:2012.00825 (2020). [2] ABCI supercomputer ( Japan ): consisting of 1088 nodes of FUJITSU server PRIMERGY CX2570 M4.
JumpStart is the machine learning (ML) hub of Amazon SageMaker that offers a one-click access to over 350 built-in algorithms; pre-trained models from TensorFlow, PyTorch, Hugging Face, and MXNet; and pre-built solution templates. This page lists available end-to-end ML solutions, pre-trained models, and example notebooks.
JumpStart helps you quickly and easily get started with machine learning (ML) and provides a set of solutions for the most common use cases that can be trained and deployed readily with just a few steps. Defining hyperparameters involves setting the values for various parameters used during the training process of an ML model.
Traditional AI can recognize, classify, and cluster, but not generate the data it is trained on. Major milestones in the last few years comprised BERT (Google, 2018), GPT-3 (OpenAI, 2020), Dall-E (OpenAI, 2021), Stable Diffusion (Stability AI, LMU Munich, 2022), ChatGPT (OpenAI, 2022). Let’s play the comparison game. No, no, no!
Figure 2: Multi-dimensionality of Netflix recommendation system (source: Basilico, “Recent Trends in Personalization at Netflix,” NeurIPS , 2020 ). Machine learning (ML) approaches can be used to learn utility functions by training it on historical data of which home pages have been created for members (i.e.,
It turned out that a better solution was to annotate data by using a clustering algorithm, in particular, I chose the popular K-means. So I simply run the K-means on the whole dataset, partitioning it into 4 different clusters. The label of a cluster was set as a label for every one of its samples. in both metrics. and Corke, P.,
In May 2020, researchers in their paper “ Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks ” explored models which combine pre-trained parametric and non-parametric memory for language generation. ML models are mathematical models and therefore require numerical data. However, now they recommend ada v2 for all tasks.
Image by Author Large Language Models (LLMs) entered the spotlight with the release of OpenAI’s GPT-3 in 2020. Document Retrieval and Clustering: LangChain can simplify retrieval and clustering using embedding models. We have seen exploding interest in LLMs and in a broader discipline, Generative AI. models by OpenAI.
Image Source: NVIDIA A100 — The Revolution in High-Performance Computing The A100 is the pioneer of NVIDIA’s Ampere architecture and emerged as a GPU that redefined computing capability when it was introduced in the first half of 2020. The A100 has significantly improved, especially compared to its previous series, the Volta.
Even for basic inference on LLM, multiple accelerators or multi-node computing clusters like multiple Kubernetes pods are required. But the issue we found was that MP is efficient in single-node clusters, but in a multi-node setting, the inference isn’t efficient. 2020 or Hoffman et al., For instance, a 1.5B
For instance, you could extract a few noisy metrics, such as a general “positivity” sentiment score that you track in a dashboard, while you also produce more nuanced clustering of the posts which are reviewed periodically in more detail. You might want to view the data in a variety of ways. The results in Section 3.7,
Like most of the world, I spent even more time indoors in 2020 than I usually do. Or cluster them first, and see if the clustering ends up being useful to determine who to assign a ticket to? You know all about LDA and topic modeling , so you go ahead and create the clusters easily.
JumpStart helps you quickly and easily get started with machine learning (ML) and provides a set of solutions for the most common use cases that can be trained and deployed readily with just a few steps. Defining hyperparameters involves setting the values for various parameters used during the training process of an ML model.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









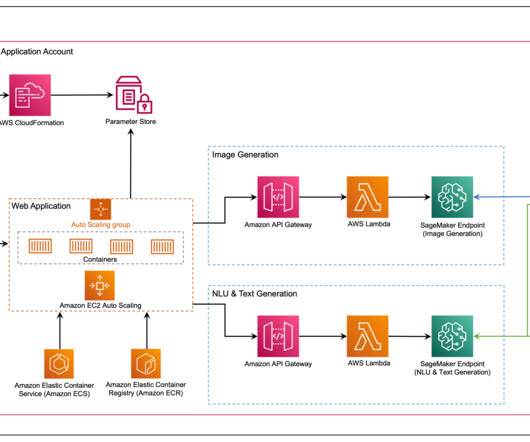












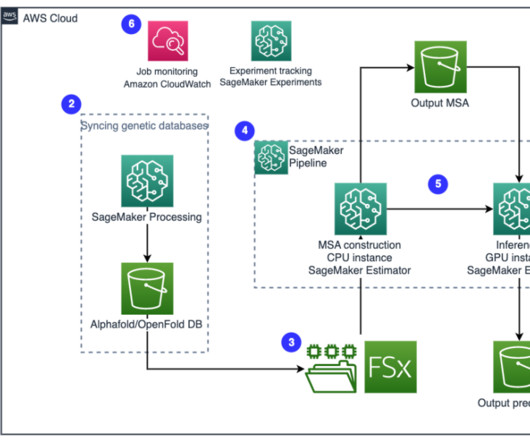



























Let's personalize your content