This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Loong evaluates a model’s ability to locate, compare, cluster, and reason on evidence spread across multiple documents, typically ranging from 10,000 to over 250,000 tokens. Clustering : Aggregating and grouping relevant information from multiple sources based on specific criteria.
The court clerk of AI is a process called retrieval-augmented generation, or RAG for short. That’s when researchers in information retrieval prototyped what they called question-answering systems, apps that use naturallanguageprocessing ( NLP ) to access text, initially in narrow topics such as baseball.
Charting the evolution of SOTA (State-of-the-art) techniques in NLP (NaturalLanguageProcessing) over the years, highlighting the key algorithms, influential figures, and groundbreaking papers that have shaped the field. Evolution of NLP Models To understand the full impact of the above evolutionary process.
They bring deep expertise in machine learning , clustering , naturallanguageprocessing , time series modelling , optimisation , hypothesis testing and deep learning to the team. The most common data science languages are Python and R — SQL is also a must have skill for acquiring and manipulating data.
We also demonstrate how you can engineer prompts for Flan-T5 models to perform various naturallanguageprocessing (NLP) tasks. A myriad of instruction tuning research has been performed since 2020, producing a collection of various tasks, templates, and methods. encode("utf-8") client = boto3.client("runtime.sagemaker")
These embeddings are useful for various naturallanguageprocessing (NLP) tasks such as text classification, clustering, semantic search, and information retrieval. For this demonstration, we use a public Amazon product dataset called Amazon Product Dataset 2020 from a kaggle competition.
The size of large NLP models is increasing | Source Such large naturallanguageprocessing models require significant computational power and memory, which is often the leading cause of high infrastructure costs. Deploying a large language model requires multiple network requests to retrieve data from different servers.
For a given frame, our features are inspired by the 2020 Big Data Bowl Kaggle Zoo solution ( Gordeev et al. ): we construct an image for each time step with the defensive players at the rows and offensive players at the columns. He is broadly interested in Deep Learning and NaturalLanguageProcessing.
But what if there was a technique to quickly and accurately solve this language puzzle? Enter NaturalLanguageProcessing (NLP) and its transformational power. But what if there was a way to unravel this language puzzle swiftly and accurately?
in 2020 as a model where parametric memory is a pre-trained seq2seq model and the non-parametric memory is a dense vector index of Wikipedia, accessed with a pre-trained neural retriever. Each node processes a subset of the files and this brings down the overall time required to ingest the data into OpenSearch Service.
Image Source: NVIDIA A100 — The Revolution in High-Performance Computing The A100 is the pioneer of NVIDIA’s Ampere architecture and emerged as a GPU that redefined computing capability when it was introduced in the first half of 2020. Tensor Cores contribute to efficient inference processing. How Many Are Needed?
PBAs, such as graphics processing units (GPUs), have an important role to play in both these phases. The following figure illustrates the idea of a large cluster of GPUs being used for learning, followed by a smaller number for inference. With Inf1, they were able to reduce their inference latency by 25%, and costs by 65%.
RAG retrieves data from outside the language model (non-parametric) and augments the prompts by adding the relevant retrieved data in context. in 2020 as a model where parametric memory is a pre-trained seq2seq model and the non-parametric memory is a dense vector index of Wikipedia, accessed with a pre-trained neural retriever.
This solution includes the following components: Amazon Titan Text Embeddings is a text embeddings model that converts naturallanguage text, including single words, phrases, or even large documents, into numerical representations that can be used to power use cases such as search, personalization, and clustering based on semantic similarity.
A lot of people are building truly new things with Large Language Models (LLMs), like wild interactive fiction experiences that weren’t possible before. But if you’re working on the same sort of NaturalLanguageProcessing (NLP) problems that businesses have been trying to solve for a long time, what’s the best way to use them?
Large language models (LLMs) with billions of parameters are currently at the forefront of naturallanguageprocessing (NLP). These models are shaking up the field with their incredible abilities to generate text, analyze sentiment, translate languages, and much more.
We’ve been running Explosion for about five years now, which has given us a lot of insights into what NaturalLanguageProcessing looks like in industry contexts. Like most of the world, I spent even more time indoors in 2020 than I usually do. I keep trying to turn the computer on, but it goes black and resets.
Explore topics such as regression, classification, clustering, neural networks, and naturallanguageprocessing. billion in 2020. Learn Machine Learning and Deep Learning Deepen your understanding of machine learning algorithms, statistical modelling, and deep learning architectures. to reach US$ 7.8
Automated algorithms for image segmentation have been developed based on various techniques, including clustering, thresholding, and machine learning (Arbeláez et al., Generative adversarial networks-based adversarial training for naturallanguageprocessing. 2012; Otsu, 1979; Long et al., Another study by Jin et al.
Large language models (LLMs) with billions of parameters are currently at the forefront of naturallanguageprocessing (NLP). These models are shaking up the field with their incredible abilities to generate text, analyze sentiment, translate languages, and much more.
Create better access to health with machine learning and naturallanguageprocessing. Clustering health aspects ? Clustering health aspects Health aspects can have many synonyms or similar contexts such as: ” sore throat ”, ” itchy throat ”, or ” swollen throat ”. Hello everyone, my name is Edward! Annotation 2.4
Introduction Large Language Models (LLMs) represent the cutting-edge of artificial intelligence, driving advancements in everything from naturallanguageprocessing to autonomous agentic systems. T5 : T5 stands for Text-to-Text Transfer Transformer, developed by Google in 2020.
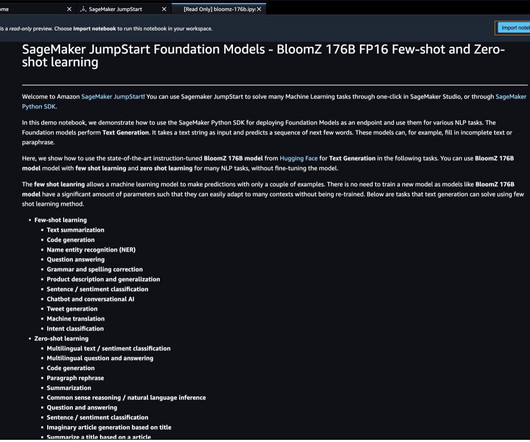
In this post and accompanying notebook, we demonstrate how to deploy the BloomZ 176B foundation model using the SageMaker Python simplified SDK in Amazon SageMaker JumpStart as an endpoint and use it for various naturallanguageprocessing (NLP) tasks. You can also access the foundation models thru Amazon SageMaker Studio.
I have about 3 YoE training PyTorch models on HPC clusters and 1 YoE optimizing PyTorch models, including with custom CUDA kernels. Ideal job would be designing, developing (CRDs, operators), monitoring and troubleshooting K8s clusters. I currently work at a public HPC center, where I am also doing a PhD. authenticated REST APIs.
Amazon Bedrock Knowledge Bases provides industry-leading embeddings models to enable use cases such as semantic search, RAG, classification, and clustering, to name a few, and provides multilingual support as well. data # Assing local directory path to a python variable local_data_path = ". .
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






























Let's personalize your content