This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Whereas a data warehouse will need rigid datamodeling and definitions, a data lake can store different types and shapes of data. In a data lake, the schema of the data can be inferred when it’s read, providing the aforementioned flexibility. However, this flexibility is a double-edged sword.
But decisions made without proper data foundations, such as well-constructed and updated datamodels, can lead to potentially disastrous results. For example, the Imperial College London epidemiology datamodel was used by the U.K. Government in 2020 […].
Photo by Matt Foxx on Unsplash The below analysis aims to look at the problem of how different parameters shape the performance of AI models. Before going deeper, few things to keep in mind: Paper considers compute as the most precious resource and models the equations around compute.
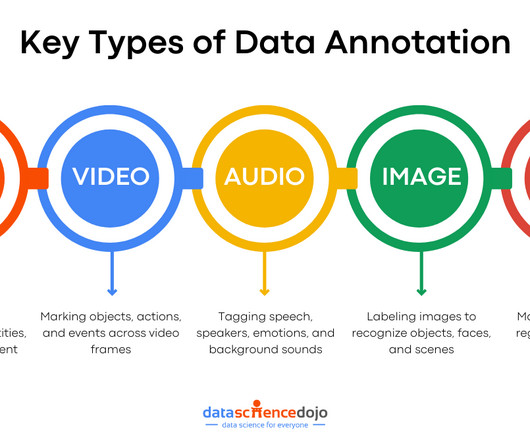
A critical component in the success of LLMs is data annotation, a process that ensures the data fed into these models is accurate, relevant, and meaningful. billion in 2020 to $4.1 This indicates the increased demand for high-quality annotated data sources to ensure LLMs generate accurate and relevant results.
By combining the capabilities of LLM function calling and Pydantic datamodels, you can dynamically extract metadata from user queries. In this post, we explore an innovative approach that uses LLMs on Amazon Bedrock to intelligently extract metadata filters from natural language queries.
For some of the world’s most valuable companies, data forms the core of their business model. The scale of data production and transmission has grown exponentially. However, raw data alone doesn’t equate to actionable insights. In one pivotal project, we faced this challenge head-on.
In a 2020 Capgemini Research study, only a meager 13% of businesses had successfully deployed use cases in production and continued to scale the use cases throughout multiple business teams. In 2019, Beacon Street Services needed new datamodels to enable its marketing team to run more targeted and effective campaigns.
Big Data Analytics News has hailed big data as the future of the translation industry. You might use predictive analysis-based data that can help you analyse buying trends or look at how the business might perform in a range of new markets. Further, big data itself incorporates working with growing amounts of data these days.
In this article, you’ll discover: upcoming trends in business intelligence what benefits will BI provide for businesses in 2020 and on? Thanks to this feature, QlickView collects, integrates and processes data at an increased speed, making it one of the fastest and most relevant BI tools in 2020. Future of BI: What Does it Hold?
With your input, we released more than 200 new capabilities across the Tableau platform in 2020. In every release, we're making Tableau easier to use, more powerful, and simpler to deploy to support governed data and analytics at scale. In 2020, we added the ability to write to external databases so you can use clean data anywhere.
From there, that question is fed into ChatGPT along with dbt datamodels that provide information about the fields in the various tables. From there, ChatGPT generates a SQL query which is then executed in the Snowflake Data Cloud , and the results are brought back into the application in a table format.
In my September 2020Data is Risky Business column for TDAN.com, I wrote about the strategy lessons for data that we can learn from the writings of a 16thcentury Japanese swordsman. To summarize: – We need to study different disciplines to understand how they relate to each other.
Not only this, but they can reduce your costs by ensuring that you can harness your data by yourself, without the need to employ a data analyst. The best data analysis software can help you to collect and organize your data, to construct potential datamodels, and can also help you to write up reports.
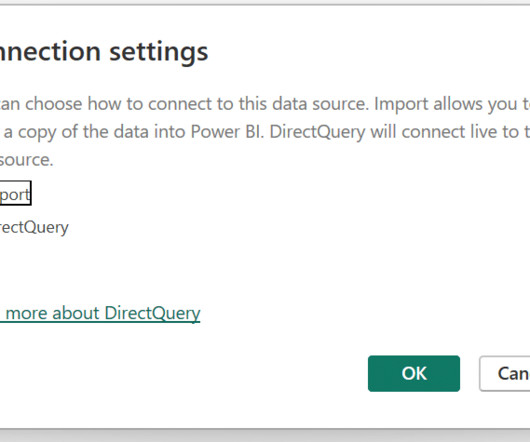
Snowflake is a cloud computing–based data cloud company that provides data warehousing services that are far more scalable and flexible than traditional data warehousing products. Creating an efficient datamodel can be the difference between having good or bad performance, especially when using DirectQuery.
DataRobot is excited to announce the graduation of the first class of our 10X Applied Data Science Academy. We started the 10x Academy in 2020 to address employers’ need for talent with strong applied automated AI skills and workers’ desire to upskill.
With your input, we released more than 200 new capabilities across the Tableau platform in 2020. In every release, we're making Tableau easier to use, more powerful, and simpler to deploy to support governed data and analytics at scale. In 2020, we added the ability to write to external databases so you can use clean data anywhere.
April 2018), which focused on users who do understand joins and curating federated data sources. May 2020) shifted sheets to a multiple-table datamodel, where the sheet’s fields allow the computer to write much more efficient queries to the data sources. Relationships in Tableau 2020.2 (May
With enough data, models can be created to “read between the lines” in both helpful and dangerous ways. In 2020, Wink suddenly applied a monthly service charge; if you didn’t pay, the device would stop working. Also in 2020, Sonos caused a stir by saying they were going to “recycle” (disable) old devices.
DagsHub DagsHub is a centralized Github-based platform that allows Machine Learning and Data Science teams to build, manage and collaborate on their projects. In addition to versioning code, teams can also version data, models, experiments and more. However, these tools have functional gaps for more advanced data workflows.
Data analysis and modeling : Certified Business Analysis Professionals have a solid grasp of data analysis techniques and can create datamodels to support business analysis activities. They identify data requirements, develop data dictionaries, and collaborate with data management teams.
Professionals witness upward career trajectories against India’s escalating demand for Data Science skills. With 93,000 vacant Data Science jobs in India by August 2020 and projections of 11 million job openings by 2026, the field presents unprecedented growth opportunities, especially for those with less than five years of experience.
April 2018), which focused on users who do understand joins and curating federated data sources. May 2020) shifted sheets to a multiple-table datamodel, where the sheet’s fields allow the computer to write much more efficient queries to the data sources. Relationships in Tableau 2020.2 (May
Unsupervised learning requires no labels and identifies underlying patterns in the data. Model architectures that qualify as “supervised learning”—from traditional regression models to random forests to most neural networks—require labeled data for training. What are some examples of Foundation Models?
Collectively, these modules address governance across various dimensions, such as infrastructure, data, model, and cost. Maira has been with AWS since January 2020. Prior to that, she worked as a data scientist in multiple industries focusing on achieving business value from data.
Greater Functionality Unlike in Direct Query, you are able to use all M and DAX functions (notably all-time intelligence functions), format fields however you desire, add calculated columns, and there are no limitations to datamodeling.
ML collaboration and timely evaluation of system design Thanks to Abhishek Rai, a data scientist with Gigaforce Inc, for collaborating with me on this interview post and reviewing it before it was published. Team composition The team comprises domain experts, data engineers, data scientists, and ML engineers.
The reason for using a mixture of domain-specific and public data is a model that excels in financial assessments while also performing well on standard benchmarks. Scaling Laws for Neural Language Models.” 2020) and Chinchilla scaling laws with prior large language model and BloombergGPT parameter and data sizes.
Like most of the world, I spent even more time indoors in 2020 than I usually do. Instead, you need to try out different ideas for the data, model implementation and even evaluation. Applied NLP Thinking: an analogy It’s a fairly abstract idea, but while I was writing this, I think I came up with a pretty fitting analogy.
Our new Global Tracker pulls information from multiple data sources into one visualization, updated daily, allowing people to see and interact with those data to inform individual behavior, business decisions, and government policy. . . Different data sources, one data visualization: the power of Prep Builder.
The Institute for the Study of Labor has talked about the use of big data in economic forecasts. Investors take it a step further and build the data into a model that projects market prices. Big data is the key to successful stock future trading. Successful investors recognize the importance of technology.
Our new Global Tracker pulls information from multiple data sources into one visualization, updated daily, allowing people to see and interact with those data to inform individual behavior, business decisions, and government policy. . . Different data sources, one data visualization: the power of Prep Builder.
data # Assing local directory path to a python variable local_data_path = ". . By using the flexible document datamodel of MongoDB Atlas, organizations can represent and query complex knowledge entities and their relationships within Amazon Bedrock.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































Let's personalize your content