This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The growth of the AI and Machine Learning (ML) industry has continued to grow at a rapid rate over recent years. Hidden Technical Debt in Machine Learning Systems More money, more problems — Rise of too many ML tools 2012 vs 2023 — Source: Matt Turck People often believe that money is the solution to a problem. Spark, Flink, etc.)
Aleksandr Timashov is an ML Engineer with over a decade of experience in AI and Machine Learning. In this interview, Aleksandr shares his unique experiences of leading groundbreaking projects in Computer Vision and Data Science at the Petronas global energy group (Malaysia). Did the pandemic and isolation complicate your work?
Automation Automating datapipelines and models ➡️ 6. The Data Engineer Not everyone working on a data science project is a data scientist. Data engineers are the glue that binds the products of data scientists into a coherent and robust datapipeline.
Wearable devices (such as fitness trackers, smart watches and smart rings) alone generated roughly 28 petabytes (28 billion megabytes) of data daily in 2020. And in 2024, global daily data generation surpassed 402 million terabytes (or 402 quintillion bytes). ML technologies help computers achieve artificial intelligence.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python MLPipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python MLPipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
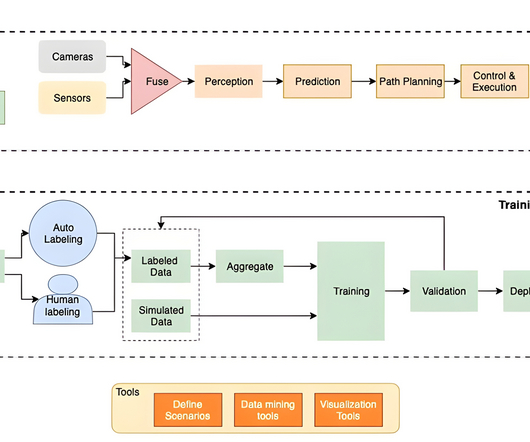
Identification of relevant representation data from a huge volume of data – This is essential to reduce biases in the datasets so that common scenarios (driving at normal speed with obstruction) don’t create class imbalance. To yield better accuracy, DNNs require large volumes of diverse, good quality data.
These activities cover disparate fields such as basic data processing, analytics, and machine learning (ML). ML is often associated with PBAs, so we start this post with an illustrative figure. The ML paradigm is learning followed by inference. The union of advances in hardware and ML has led us to the current day.
Second, the ability of these models to generate SQL queries from natural language has been proven for years, as seen in the 2020 release of Amazon QuickSight Q. It can take the form of rule-based filters, similarity matching against a database of known prompt injection examples, or an ML classifier.
It does not support the ‘dvc repro’ command to reproduce its datapipeline. DVC Released in 2017, Data Version Control ( DVC for short) is an open-source tool created by iterative. However, these tools have functional gaps for more advanced data workflows.
Introduction to LangChain for Including AI from Large Language Models (LLMs) Inside Data Applications and DataPipelines This article will provide an overview of LangChain, the problems it addresses, its use cases, and some of its limitations. Python : Great for including AI in Python-based software or datapipelines.
One should really think of us at the level of doing the technical implementation work around designing, developing and operationally deploying data products and services that use ML. I’ll give you a rough guide to what we’ll talk about—in the first place, a very macro and micro view of the importance of data.
One should really think of us at the level of doing the technical implementation work around designing, developing and operationally deploying data products and services that use ML. I’ll give you a rough guide to what we’ll talk about—in the first place, a very macro and micro view of the importance of data.
One should really think of us at the level of doing the technical implementation work around designing, developing and operationally deploying data products and services that use ML. I’ll give you a rough guide to what we’ll talk about—in the first place, a very macro and micro view of the importance of data.
Today’s data management and analytics products have infused artificial intelligence (AI) and machine learning (ML) algorithms into their core capabilities. These modern tools will auto-profile the data, detect joins and overlaps, and offer recommendations. 2) Line of business is taking a more active role in data projects.
The article is based on a case study that will enable readers to understand the different aspects of the ML monitoring phase and likewise perform actions that can make ML model performance monitoring consistent throughout the deployment. So let’s get into it. predict(val_dataloader) print((actuals - baseline_predictions).abs().mean().item())
SageMaker geospatial capabilities make it straightforward for data scientists and machine learning (ML) engineers to build, train, and deploy models using geospatial data. Among these models, the spatial fixed effect model yielded the highest mean R-squared value, particularly for the timeframe spanning 2014 to 2020.
The onset of the pandemic has triggered a rapid increase in the demand and adoption of ML technology. Building ML team Following the surge in ML use cases that have the potential to transform business, the leaders are making a significant investment in ML collaboration, building teams that can deliver the promise of machine learning.
Iris was designed to use machine learning (ML) algorithms to predict the next steps in building a datapipeline. He currently is working on Generative AI for data integration. Clay Elmore is an AI/ML Specialist Solutions Architect at AWS. He is the author of the upcoming book “What’s Your Problem?”
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

























Let's personalize your content