This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A visual representation of discriminative AI – Source: Analytics Vidhya Discriminative modeling, often linked with supervisedlearning, works on categorizing existing data. Generative AI often operates in unsupervised or semi-supervisedlearning settings, generating new data points based on patterns learned from existing data.
Louis-François Bouchard in What is Artificial Intelligence Introduction to self-supervisedlearning·4 min read·May 27, 2020 80 … Read the full blog for free on Medium. Author(s): Louis-François Bouchard Originally published on Towards AI. Join thousands of data leaders on the AI newsletter.
“Self-Supervised methods […] are going to be the main method to train neural nets before we train them for difficult tasks” — Yann LeCun Well! Let’s have a look at this Self-SupervisedLearning! Let’s have a look at Self-SupervisedLearning. That is why it is called Self -SupervisedLearning.
Gain an understanding of the important developments of the past year, as well as insights into what expect in 2020. It is an annual tradition for Xavier Amatriain to write a year-end retrospective of advances in AI/ML, and this year is no different.
Foundation models are pre-trained on unlabeled datasets and leverage self-supervisedlearning using neural network s. Foundation models are becoming an essential ingredient of new AI-based workflows, and IBM Watson® products have been using foundation models since 2020.
Since the release of the Language Model GPT-3 in 2020, LMs have been used in isolation to complete tasks on their own, rather than being used as parts of other systems. Let’s first take a look at the process of supervisedlearning as motivation. Let’s take a look at how this works now. Can we do better?
GPT-3 wurde mit mehr als 100 Milliarden Wörter trainiert, das parametrisierte Machine Learning Modell selbst wiegt 800 GB (quasi nur die Neuronen!) Neben SupervisedLearning kam auch Reinforcement Learning zum Einsatz. Oktober 2014 ↑ Bussler, Frederik (July 21, 2020). Retrieved August 1, 2020.
Once you’re past prototyping and want to deliver the best system you can, supervisedlearning will often give you better efficiency, accuracy and reliability than in-context learning for non-generative tasks — tasks where there is a specific right answer that you want the model to find. That’s not a path to improvement.
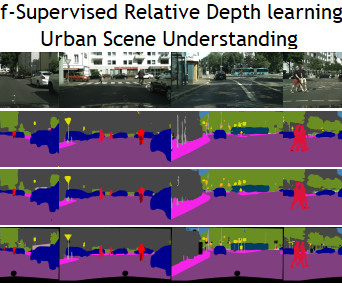
Slot-TTA builds on top of slot-centric models by incorporating segmentation supervision during the training phase. ii) We showcase the effectiveness of SSL-based TTA approaches for scene decomposition, while previous self-supervised test-time adaptation methods have primarily demonstrated results in classification tasks.
Using such data to train a model is called “supervisedlearning” On the other hand, pretraining requires no such human-labeled data. This process is called “self-supervisedlearning”, and is identical to supervisedlearning except for the fact that humans don’t have to create the labels.
A demonstration of the RvS policy we learn with just supervisedlearning and a depth-two MLP. It uses no TD learning, advantage reweighting, or Transformers! Offline reinforcement learning (RL) is conventionally approached using value-based methods based on temporal difference (TD) learning.
Self-supervision: As in the Image Similarity Challenge , all winning solutions used self-supervisedlearning and image augmentation (or models trained using these techniques) as the backbone of their solutions. His research interest is deep metric learning and computer vision.
The introduction of ChatGPT capabilities has generated a lot of interest in generative AI foundation models (these are pre-trained on unlabeled datasets and leverage self-supervisedlearning with the help of Large Language Models using a neural network ). The ROE ranges also varied by country, from –5% to +13% [1].
For this demonstration, we use a public Amazon product dataset called Amazon Product Dataset 2020 from a kaggle competition. It is a multi-task, multi-lingual, multi-locale, and multi-modal BERT-based encoder-only model trained on text and structured data input.
Foundation models are large AI models trained on enormous quantities of unlabeled data—usually through self-supervisedlearning. What is self-supervisedlearning? Self-supervisedlearning is a kind of machine learning that creates labels directly from the input data. Find out in the guide below.
Acquiring Essential Machine Learning Knowledge Once you have a strong foundation in mathematics and programming, it’s time to dive into the world of machine learning. Additionally, you should familiarize yourself with essential machine learning concepts such as feature engineering, model evaluation, and hyperparameter tuning.
In contrast to classification, a supervisedlearning paradigm, generation is most often done in an unsupervised manner: for example an autoencoder , in the form of a neural network, can capture the statistical properties of a dataset. One does not need to look into the math to see that it’s inherently more difficult.
We have begun to observe diminishing returns and are already exploring other promising research directions into multimodality and self-supervisedlearning. While this progress has been exciting, bootstrapping strong teacher models was bound to run into an asymptotic limit and stop bearing fruit. 5206-5210, doi: 10.1109/ICASSP.2015.7178964.
2020) Scaling Laws for Neural Language Models [link] First formal study documenting empirical scaling laws Published by OpenAI The Data Quality Conundrum Not all data is created equal. Some argue that while scaling has driven progress so far, we may eventually exhaust high-quality training data, leading to diminishing returns.
I was looking forward to the 2020 tournament and had a model I was very excited about. When the 2020 March Madness competition was cancelled and COVID-19 was really starting to hit hard, I wanted to find a way to get involved and help. What supervisedlearning methods did you use?
My work demonstrated broad expertise in computer vision, deep learning, and industrial IoT, showcasing the ability to adapt cutting-edge technologies to the specific needs of the oil and gas industry and tackle unprecedented challenges in the Malaysian context. One of the most promising trends in Computer Vision is Self-SupervisedLearning.
And that’s the power of self-supervisedlearning. But desert, ocean, desert, in this way, I think that’s what the power of self-supervisedlearning is. It’s essentially self -supervisedlearning. This is the example from California from 2020. So here’s this example.
And that’s the power of self-supervisedlearning. But desert, ocean, desert, in this way, I think that’s what the power of self-supervisedlearning is. It’s essentially self -supervisedlearning. This is the example from California from 2020. So here’s this example.
The intuition behind my choice of image pre-processing was aimed at primarily creating weakly delineated boundaries in the images to enable the models gain better visual perception of the fields and also to offer a better supervisedlearning procedure. I encourage you to check it out here.
Conclusion This article described regression which is a supervisinglearning approach. We discussed the statistical method of fitting a line in Skicit Learn. 2020) Pragmatic Machine Learning with Python. 2019) Python Machine Learning. It is not always the case that there is a linear relationship. England, A.
One trend that started with our work on Vision Transformers in 2020 is to use the Transformer architecture in computer vision models rather than convolutional neural networks. Similar updates were published in 2021 , 2020 , and 2019. Top Computer Vision Computer vision continues to evolve and make rapid progress.
As humans, we learn a lot of general stuff through self-supervisedlearning by just experiencing the world. We have papers from 2020 where we showed that these models hallucinate less than regular parametric models. DK: Absolutely, I think that’s a perfect metaphor. You can point back and say, “It comes from here.
As humans, we learn a lot of general stuff through self-supervisedlearning by just experiencing the world. We have papers from 2020 where we showed that these models hallucinate less than regular parametric models. DK: Absolutely, I think that’s a perfect metaphor. You can point back and say, “It comes from here.
Data scientists and researchers train LLMs on enormous amounts of unstructured data through self-supervisedlearning. The model then predicts the missing words (see “what is self-supervisedlearning?” Next, OpenAI released GPT-3 in June of 2020.
Data scientists and researchers train LLMs on enormous amounts of unstructured data through self-supervisedlearning. The model then predicts the missing words (see “what is self-supervisedlearning?” Next, OpenAI released GPT-3 in June of 2020.
2020) and Chinchilla scaling laws with prior large language model and BloombergGPT parameter and data sizes. International Conference on Learning Representations. [20] 20] Once you have your instruction data, you split it into training, validation, and test sets, like in standard supervisedlearning. 32] Alex Wang, et al.
On the other hand, the labels put by me only rely on time, but in practice we know that’s gonna make errors, so a classifier would learn from bad data. Now I have to stress one thing: what I’ve done here, that is using a clustering algorithm to annotate data for supervisedlearning, cannot be done most time. 2657–2666, Nov.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content