This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
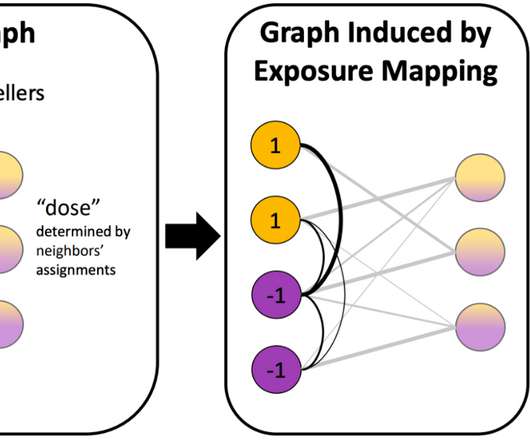
In 2022, we continued this journey, and advanced the state-of-the-art in several related areas. We continued our efforts in developing new algorithms for handling large datasets in various areas, including unsupervised and semi-supervised learning , graph-based learning , clustering , and large-scale optimization.
Over time, it is true that artificial intelligence and deeplearning models will be help process these massive amounts of data (in fact, this is already being done in some fields). The post Biggest Trends in Data Visualization Taking Shape in 2022 appeared first on SmartData Collective. In forecasting future events.
Over the course of 2023, we rapidly scaled up our training clusters from 1K, 2K, 4K, to eventually 16K GPUs to support our AI workloads. Today, we’re training our models on two 24K-GPU clusters. We don’t expect this upward trajectory for AI clusters to slow down any time soon. Building AI clusters requires more than just GPUs.
Modern model pre-training often calls for larger cluster deployment to reduce time and cost. In October 2022, we launched Amazon EC2 Trn1 Instances , powered by AWS Trainium , which is the second generation machine learning accelerator designed by AWS. We use Slurm as the cluster management and job scheduling system.
For reference, GPT-3, an earlier generation LLM has 175 billion parameters and requires months of non-stop training on a cluster of thousands of accelerated processors. The Carbontracker study estimates that training GPT-3 from scratch may emit up to 85 metric tons of CO2 equivalent, using clusters of specialized hardware accelerators.
Introduction Training deeplearning models is a heavy task from computation and memory requirement perspective. Enterprises, research and development teams shared GPU clusters for this purpose. on the clusters to get the jobs and allocate GPUs, CPUs, and system memory to the submitted tasks by different users.
With containers, scaling on a cluster becomes much easier. In late 2022, AWS announced the general availability of Amazon EC2 Trn1 instances powered by AWS Trainium accelerators, which are purpose built for high-performance deeplearning training. On the Amazon ECS console, choose Clusters in the navigation pane.
Natural language processing (NLP) has been growing in awareness over the last few years, and with the popularity of ChatGPT and GPT-3 in 2022, NLP is now on the top of peoples’ minds when it comes to AI. Developing NLP tools isn’t so straightforward, and requires a lot of background knowledge in machine & deeplearning, among others.
In 2022, we expanded our research interactions and programs to faculty and students across Latin America , which included grants to women in computer science in Ecuador. We also help make global conferences accessible to more researchers around the world, for example, by funding 24 students this year to attend DeepLearning Indaba in Tunisia.
billion by the end of 2024 , reflecting a remarkable increase from $29 billion in 2022. The primary components include: Graphics Processing Units (GPUs) These are specially designed for parallel processing, making them ideal for training deeplearning models. The global Generative AI market is projected to exceed $66.62
The research explores machine learning methods in image coaddition, a process used by astronomers to combine multiple images into a single higher-resolution image. CDS spoke with Harlan about the project, deeplearning methods in the field of astronomy, and advice for current CDS students.
For example, on a commercially available cluster of 3,584 H100 GPUs co-developed by startup Inflection AI and operated by CoreWeave , a cloud service provider specializing in GPU-accelerated workloads, the system completed the massive GPT-3-based training benchmark in less than eleven minutes.
LLMs disrupt the industry Towards the end of 2022, groundbreaking LLMs were released that realized drastic improvements over previous model capabilities. In order to provision a highly scalable cluster that is resilient to hardware failures, Thomson Reuters turned to Amazon SageMaker HyperPod. Chinchilla point 52b 132b 260b 600b 1.3t
Figure 5: Architecture of Convolutional Autoencoder for Image Segmentation (source: Bandyopadhyay, “Autoencoders in DeepLearning: Tutorial & Use Cases [2023],” V7Labs , 2023 ). VAEs can generate new samples from the learned latent distribution, making them ideal for image generation and style transfer tasks.
These factors require training an LLM over large clusters of accelerated machine learning (ML) instances. Within one launch command, Amazon SageMaker launches a fully functional, ephemeral compute cluster running the task of your choice, and with enhanced ML features such as metastore, managed I/O, and distribution.
For example, GPT-3 (2020) and BLOOM (2022) feature around 175 billion parameters, Gopher (2021) has 230 billion parameters, and MT-NLG (2021) 530 billion parameters. In 2022, Hoffman et al. In 2022, Hoffman et al. They implemented their guidance in the 70B parameter Chinchilla (2022) model, that outperformed much bigger models.
The DJL is a deeplearning framework built from the ground up to support users of Java and JVM languages like Scala, Kotlin, and Clojure. With the DJL, integrating this deeplearning is simple. Business requirements We are the US squad of the Sportradar AI department. The architecture of DJL is engine agnostic.
machine learning, statistics, probability, and algebra) are employed to recommend our popular daily applications. Each service uses unique techniques and algorithms to analyze user data and provide recommendations that keep us returning for more. Figure 1: Distribution of applications of recommendation systems (source: Ko et al.,
NOTES, DEEPLEARNING, REMOTE SENSING, ADVANCED METHODS, SELF-SUPERVISED LEARNING A note of the paper I have read Photo by Kelly Sikkema on Unsplash Hi everyone, In today’s story, I would share notes I took from 32 pages of Wang et al., 2022’s paper. 2022Deeplearning notoriously needs a lot of data in training.
Big Ideas What to look out for in 2022 1. They bring deep expertise in machine learning , clustering , natural language processing , time series modelling , optimisation , hypothesis testing and deeplearning to the team. Automation Automating data pipelines and models ➡️ 6.
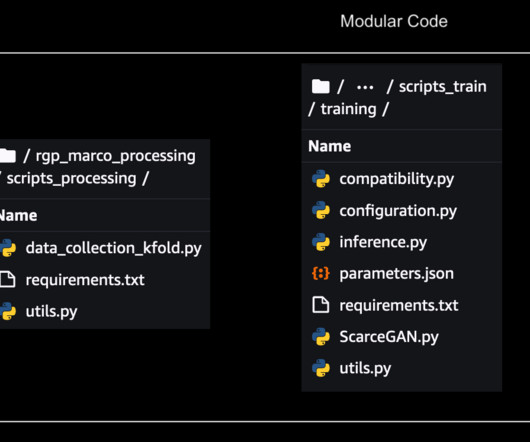
They’ve built a deep-learning model ScarceGAN, which focuses on identification of extremely rare or scarce samples from multi-dimensional longitudinal telemetry data with small and weak labels. This work has been published in CIKM’21 and is open source for rare class identification for any longitudinal telemetry data.
In these cases, you might be able to speed up the process by distributing training over multiple machines or processes in a cluster. This post discusses how SageMaker LightGBM helps you set up and launch distributed training, without the expense and difficulty of directly managing your training clusters. 1 5329 5414 0.937 0.947 65.6
Machine Learning : Supervised and unsupervised learning algorithms, including regression, classification, clustering, and deeplearning. Tools and frameworks like Scikit-Learn, TensorFlow, and Keras are often covered.
Large model sizes The MT-NLG model released in 2022 has 530 billion parameters and requires several hundred gigabytes of storage. Even for basic inference on LLM, multiple accelerators or multi-node computing clusters like multiple Kubernetes pods are required. 2022 where they show how to train a model on a fixed-compute budget.
billion in 2022, an increase of 21.3% Nevertheless, we are still left with the question: How can we do machine learning better? To find out, we’ve taken some of the upcoming tutorials and workshops from ODSC West 2023 and let the experts via their topics guide us toward building better machine learning.
Cody Coleman, CEO and co-founder of Coactive AI gave a presentation entitled “Data Selection for Data-Centric AI: Quality over Quantity” at Snorkel AI’s Future of Data-Centric AI Event in August 2022. Active learning is a really powerful data selection technique for reducing labeling costs. And this work appeared in AAAI 2022.
Cody Coleman, CEO and co-founder of Coactive AI gave a presentation entitled “Data Selection for Data-Centric AI: Quality over Quantity” at Snorkel AI’s Future of Data-Centric AI Event in August 2022. Active learning is a really powerful data selection technique for reducing labeling costs. And this work appeared in AAAI 2022.
Cody Coleman, CEO and co-founder of Coactive AI gave a presentation entitled “Data Selection for Data-Centric AI: Quality over Quantity” at Snorkel AI’s Future of Data-Centric AI Event in August 2022. Active learning is a really powerful data selection technique for reducing labeling costs. And this work appeared in AAAI 2022.
A Machine Learning Engineer is crucial in designing, building, and deploying models that drive this transformation. The global Machine Learning market was valued at USD 35.80 billion in 2022 and is expected to grow to USD 505.42 Neural networks are the foundation of DeepLearning techniques.
Through a collaboration between the Next Gen Stats team and the Amazon ML Solutions Lab , we have developed the machine learning (ML)-powered stat of coverage classification that accurately identifies the defense coverage scheme based on the player tracking data. In this post, we deep dive into the technical details of this ML model.
scikit-learn – The most widely Machine learning for text used for Python, scikit-learn is an open-source, free machine learning library. It has many useful tools for stats modeling and machine learning including regression, classification, and clustering.
The average cost of a data breach was $4.35M in 2022 , and it took an average of 277 days for a company to identify and contain a breach. from 2022 to 2030. Clustering saves serious time in data analysis by grouping together similar and/or related data, revealing when there are patterns of unique activity and behavior.
Further, it will provide a step-by-step guide on anomaly detection Machine Learning python. Key Takeaways: As of 2021, the market size of Machine Learning was USD 25.58 CAGR during 2022-2030. By 2028, the market value of global Machine Learning is projected to be $31.36 Billion which is supposed to increase by 35.6%
Posted by Yanqi Zhou, Research Scientist, Google Research, Brain Team The capacity of a neural network to absorb information is limited by the number of its parameters, and as a consequence, finding more effective ways to increase model parameters has become a trend in deeplearning research.
These features can be simple metadata or model-based features (extracted from a deeplearning model), representing how good that video is for a member. Users are grouped into small clusters based on their viewing history to obtain context-only features. Context features refer to the user and his query (e.g., That’s not the case.
One of the major challenges in training and deploying LLMs with billions of parameters is their size, which can make it difficult to fit them into single GPUs, the hardware commonly used for deeplearning. We select Amazon’s SEC filing reports for years 2021–2022 as the training data to fine-tune the GPT-J 6B model.
clustering, matching) can dictate the best metric. from langchain.evaluation import RegexMatchStringEvaluator evaluator = RegexMatchStringEvaluator() evaluator.evaluate_strings( prediction="The date is 2022-01-01", reference="The date is 2022-01-01" ) # {'score': 1} # Check for the presence of a MM-DD-YYYY string.
FedML supports several out-of-the-box deeplearning algorithms for various data types, such as tabular, text, image, graphs, and Internet of Things (IoT) data. Please review the presentation at re:MARS 2022 focused on “ Managed Federated Learning on AWS: A case study for healthcare ” for a detailed walkthrough of this solution.
Clustering — we can cluster our sentences, useful for topic modeling. text-similarity-{ada, babbage, curie, davinci}-001, use cases: Clustering, regression, anomaly detection, visualization Text search : Semantic information retrieval over documents. The article is clustering “Fine Food Reviews” dataset. lower price.
Introduction Machine Learning is critical in shaping modern technologies, from autonomous vehicles to personalised recommendations. The global Machine Learning market was valued at USD 35.80 billion in 2022 and is expected to grow significantly, reaching USD 505.42 For unSupervised Learning tasks (e.g., Random Forests).
Introduction Machine Learning has become a cornerstone in transforming industries worldwide. billion in 2022 and is projected to grow at a CAGR of 34.8% A key aspect of building effective Machine Learning models is feature extraction in Machine Learning. The global market was valued at USD 36.73 from 2023 to 2030.
Posted by Eleni Triantafillou, Research Scientist, and Malik Boudiaf, Student Researcher, Google Deeplearning has recently made tremendous progress in a wide range of problems and applications, but models often fail unpredictably when deployed in unseen domains or distributions.
Data requirements for GPT-3 and a 100T parameter model according to OpenAI's 2020 and DeepMind's 2022 scaling laws. This is about 20 times more data than expected based on the scaling laws in [ 3 ], and a staggering 4,000 times more data than GPT-3.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content