This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Continuous Integration and Continuous Delivery (CI/CD) for DataPipelines: It is a Game-Changer with AnalyticsCreator! The need for efficient and reliable datapipelines is paramount in data science and data engineering. They transform data into a consistent format for users to consume.
Datapipelines automatically fetch information from various disparate sources for further consolidation and transformation into high-performing data storage. There are a number of challenges in data storage , which datapipelines can help address. Choosing the right datapipeline solution.
One of the key elements that builds a data fabric architecture is to weave integrated data from many different sources, transform and enrich data, and deliver it to downstream data consumers. As a part of datapipeline, Address Verification Interface (AVI) can remediate bad address data.
Implementing a data fabric architecture is the answer. What is a data fabric? Data fabric is defined by IBM as “an architecture that facilitates the end-to-end integration of various datapipelines and cloud environments through the use of intelligent and automated systems.”
The US nationwide fraud losses topped $10 billion in 2023, a 14% increase from 2022. It seems straightforward at first for batch data, but the engineering gets even more complicated when you need to go from batch data to incorporating real-time and streaming data sources, and from batch inference to real-time serving.
Natural language processing (NLP) has been growing in awareness over the last few years, and with the popularity of ChatGPT and GPT-3 in 2022, NLP is now on the top of peoples’ minds when it comes to AI. Cloud Computing, APIs, and Data Engineering NLP experts don’t go straight into conducting sentiment analysis on their personal laptops.
SageMaker Canvas integration with Amazon Redshift provides a unified environment for building and deploying machine learning models, allowing you to focus on creating value with your data rather than focusing on the technical details of building datapipelines or ML algorithms.
Automation Automating datapipelines and models ➡️ 6. Big Ideas What to look out for in 2022 1. Team Building the right data science team is complex. With a range of role types available, how do you find the perfect balance of Data Scientists , Data Engineers and Data Analysts to include in your team?
These tools include things like profiling data sources, validating data migrations, generating datapipelines and dbt sources, and bulk translating SQL. Some of the major improvements that have been made are within the data profiling and validation components of the Toolkit CLI.
You can easily: Store and process data using S3 and RedShift Create datapipelines with AWS Glue Deploy models through API Gateway Monitor performance with CloudWatch Manage access control with IAM This integrated ecosystem makes it easier to build end-to-end machine learning solutions.
It provides a Web-based user interface for creating, managing, and monitoring data flow and a range of pre-built connectors and processors for performing data processing tasks. Datapipeline in Apachine NiFi (image by author) To consume an LDES stream, an LDES client processor is needed in the Apache NiFi flow.
It is 2022, and software developers are observing the dominance of native apps because of the data-driven approach. It uses machine learning and natural language processing technology to improve data matching. The reusability feature will help in data management and analytics, further maintaining the datapipeline.
For our final structured and unstructured datapipeline, we observe Anthropic’s Claude 2 on Amazon Bedrock generated better overall results for our final datapipeline. Did anyone make an ace at the 2022 Shriners Children’s Open? We selected Anthropic’s Claude v2 and Claude Instant on Amazon Bedrock.
December 7, 2022 - 11:16pm. December 8, 2022. Every company today is being asked to do more with less, and leaders need access to fresh, trusted KPIs and data-driven insights to manage their businesses, keep ahead of the competition, and provide unparalleled customer experiences. . Allison (Ally) Witherspoon Johnston.
December 7, 2022 - 11:16pm. December 8, 2022. Every company today is being asked to do more with less, and leaders need access to fresh, trusted KPIs and data-driven insights to manage their businesses, keep ahead of the competition, and provide unparalleled customer experiences. . Allison (Ally) Witherspoon Johnston.
While growing data enables companies to set baselines, benchmarks, and targets to keep moving ahead, it poses a question as to what actually causes it and what it means to your organization’s engineering team efficiency. What’s causing the data explosion? Big data analytics from 2022 show a dramatic surge in information consumption.
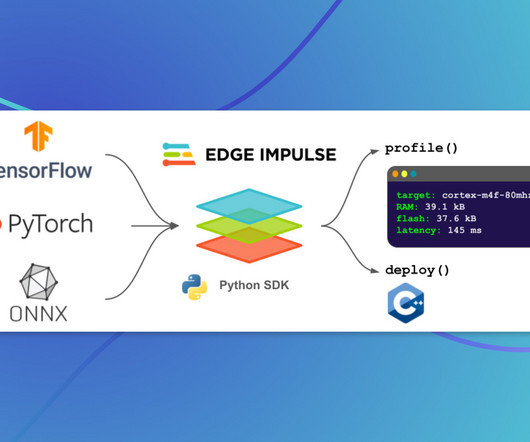
We sketch out ideas in notebooks, build datapipelines and training scripts, and integrate with a vibrant ecosystem of Python tools. on Tuesday, April 4, 2022 “We’ve always been known for our fantastic user interface, but ML practitioners like us live in Python,” says Daniel Situnayake, Edge Impulse’s head of ML. “We
If we were to use RAG to converse with these reports, we could ask questions such as “What are the risks that faced company X in 2022,” or “What is the net revenue of company Y in 2022?” Consider the question: “What are the top 5 companies with the highest revenue in 2022?” Sort the revenues in descending order.
As organisations increasingly rely on data to drive decision-making, understanding the fundamentals of Data Engineering becomes essential. The global Big Data and Data Engineering Services market, valued at USD 51,761.6 million in 2022, is projected to grow at a CAGR of 18.15% , reaching USD 140,808.0
Launched in November 2022, contestants of the ETH price prediction data challenge were asked to engage with Ocean.py This challenge aimed to activate relevant communities of Web3-native data scientists and guide them towards potential use cases such as community-owned algorithms via data NFTs and DeFi protocol design.
Jacks also founded the KubeAcademy, the parent organization of the official Kubernetes community conference KubeCon, and was the co-Founder and CEO of Aljabr which builds cloud-native datapipelines. Sign up for free at: [link] Recorded: 2022-04-04. Our weekly newsletter picks out the most interesting tools and new releases.
Data Engineering : Building and maintaining datapipelines, ETL (Extract, Transform, Load) processes, and data warehousing. One major factor is the increasing demand for skilled data scientists as companies across various industries harness the power of data to drive decision-making.
The primary goal of Data Engineering is to transform raw data into a structured and usable format that can be easily accessed, analyzed, and interpreted by Data Scientists, analysts, and other stakeholders. Future of Data Engineering The Data Engineering market will expand from $18.2
billion in 2022, is expected to soar to USD 505.42 Use Cases in ML Workflows Hydra excels in scenarios requiring frequent parameter tuning, such as hyperparameter optimisation, multi-environment testing, and orchestrating pipelines. These issues can hinder experimentation, reproducibility, and workflow efficiency.
Securing AI models and their access to data While AI models need flexibility to access data across a hybrid infrastructure, they also need safeguarding from tampering (unintentional or otherwise) and, especially, protected access to data. Learn more about IBM watsonx 1.
Indeed, this perspective characterized much of the coverage around generative AI as the release of ChatGPT and other tools mainstreamed the technology in 2022, with some analysts predicting that we were on the brink of a revolution that would reshape the future of work.
Allison (Ally) Witherspoon Johnston Senior Vice President, Product Marketing, Tableau Bronwen Boyd December 7, 2022 - 11:16pm February 14, 2023 In the quest to become a customer-focused company, the ability to quickly act on insights and deliver personalized customer experiences has never been more important.
In 2022, “AI everywhere” has enabled zero marginal cost of content generation. This starts from data wrangling and constructing datapipelines all the way to monitoring models and conducting risk reviews using "policy as code".
Instead of moving customer data to the processing engine, we move the processing engine to the data. Manage data with a seamless, consistent design experience – no need for complex coding or highly technical skills. Simply design datapipelines, point them to the cloud environment, and execute.
Historically, Python was only supported via a connector, so making predictions on our energy data using an algorithm created in Python would require moving data out of our Snowflake environment. Snowflake Dynamic Tables are a new(ish) table type that enables building and managing datapipelines with simple SQL statements.
We developed a custom datapipeline to handle the immense volume of visual data, resulting in significant cost savings and reduced human exposure to hazardous environments. You told us you were implementing these projects in 2020-2022, so it all started amid the Covid-19 times.
Both companies seem to recognize this “necessary evil” dynamic as they continue to be partners as of 2022. Similar to Query Parallelization, Microsoft introduced Horizontal Fusion in September of 2022. Essentially, Horizontal Fusion reduces multiple queries that have a similar shape into a one query.
DagsHub DagsHub is a centralized Github-based platform that allows Machine Learning and Data Science teams to build, manage and collaborate on their projects. In addition to versioning code, teams can also version data, models, experiments and more. It does not support the ‘dvc repro’ command to reproduce its datapipeline.
Ingest your data and DataRobot will use all these data points to train a model—and once it is deployed, your marketing team will be able to get a prediction to know if a customer is likely to redeem a coupon or not and why. AI Experience 2022. All of this can be integrated with your marketing automation application of choice.
Jason Goldfarb, senior data scientist at State Farm , gave a presentation entitled “Reusable Data Cleaning Pipelines in Python” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. It has always amazed me how much time the data cleaning portion of my job takes to complete.
This allows you to perform tasks such as ensuring data quality against data sources (once or over time), compare data metrics and metadata across environments, and create/manage datapipelines for all your tables and views. Be sure to follow: this series for more updates on the phData Toolkit tools and features.
Conclusion Sportradar’s product built on the DJL solution went live before the 2022–23 NFL regular season started, and it has been running smoothly since then. About the authors Fred Wu is a Senior Data Engineer at Sportradar, where he leads infrastructure, DevOps, and data engineering efforts for various NBA and NFL products.
Today, 35% of companies report using AI in their business, which includes ML, and an additional 42% reported they are exploring AI, according to the IBM Global AI Adoption Index 2022. How to use ML to automate the refining process into a cyclical ML process. How MLOps will be used within the organization.
Focusing only on what truly matters reduces data clutter, enhances decision-making, and improves the speed at which actionable insights are generated. Streamlined DataPipelines Efficient datapipelines form the backbone of lean data management. billion in 2023 to $9.28 billion by 2030, at a CAGR of 13%.
Jason Goldfarb, senior data scientist at State Farm , gave a presentation entitled “Reusable Data Cleaning Pipelines in Python” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. It has always amazed me how much time the data cleaning portion of my job takes to complete.
Jason Goldfarb, senior data scientist at State Farm , gave a presentation entitled “Reusable Data Cleaning Pipelines in Python” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. It has always amazed me how much time the data cleaning portion of my job takes to complete.
Data movements lead to high costs of ETL and rising data management TCO. The inability to access and onboard new datasets prolong the datapipeline’s creation and time to market. Contact phData today for any questions, advice, best practices, or data strategy services.
We encourage you to spend a few minutes browsing the apps and tools available in the phData Toolkit today to set yourself up for success in 2022. phData Toolkit If you haven’t already explored the phData Toolkit, we highly recommend checking it out! Be sure to follow: this series for more updates on the phData Toolkit tools and features.
When bad data is inputted, it inevitably leads to poor outcomes. A coding error impacted credit scoring In 2022, Equifax - a major credit bureau - reported inaccurate credit scores for millions of consumers. In 2022, the company ingested bad data from one of its major customers.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content