This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Businesses are under pressure to show return on investment (ROI) from AI use cases, whether predictive machine learning (ML) or generative AI. Only 54% of ML prototypes make it to production, and only 5% of generative AI use cases make it to production. Using SageMaker, you can build, train and deploy ML models.
Machine learning (ML) helps organizations to increase revenue, drive business growth, and reduce costs by optimizing core business functions such as supply and demand forecasting, customer churn prediction, credit risk scoring, pricing, predicting late shipments, and many others. Let’s learn about the services we will use to make this happen.
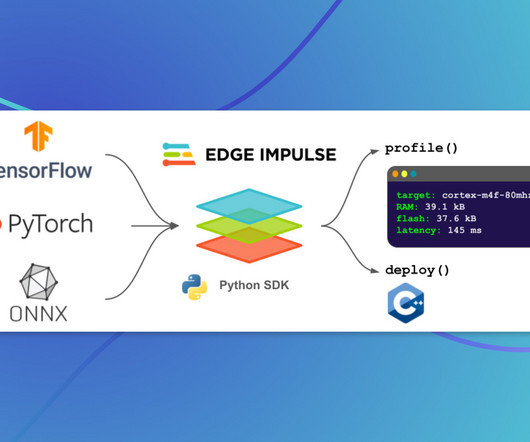
Last Updated on April 4, 2023 by Editorial Team Introducing a Python SDK that allows enterprises to effortlessly optimize their ML models for edge devices. With their groundbreaking web-based Studio platform, engineers have been able to collect data, develop and tune ML models, and deploy them to devices.
Aleksandr Timashov is an ML Engineer with over a decade of experience in AI and Machine Learning. In this interview, Aleksandr shares his unique experiences of leading groundbreaking projects in Computer Vision and Data Science at the Petronas global energy group (Malaysia). Did the pandemic and isolation complicate your work?
Automation Automating datapipelines and models ➡️ 6. Big Ideas What to look out for in 2022 1. Team Building the right data science team is complex. With a range of role types available, how do you find the perfect balance of Data Scientists , Data Engineers and Data Analysts to include in your team?
You can easily: Store and process data using S3 and RedShift Create datapipelines with AWS Glue Deploy models through API Gateway Monitor performance with CloudWatch Manage access control with IAM This integrated ecosystem makes it easier to build end-to-end machine learning solutions.
It enhances scalability, experimentation, and reproducibility, allowing ML teams to focus on innovation. billion in 2022, is expected to soar to USD 505.42 This blog highlights the importance of organised, flexible configurations in ML workflows and introduces Hydra. As the global Machine Learning market, valued at USD 35.80
Natural language processing (NLP) has been growing in awareness over the last few years, and with the popularity of ChatGPT and GPT-3 in 2022, NLP is now on the top of peoples’ minds when it comes to AI. Cloud Computing, APIs, and Data Engineering NLP experts don’t go straight into conducting sentiment analysis on their personal laptops.
Since 2018, our team has been developing a variety of ML models to enable betting products for NFL and NCAA football. These models are then pushed to an Amazon Simple Storage Service (Amazon S3) bucket using DVC, a version control tool for ML models. Business requirements We are the US squad of the Sportradar AI department.
For our final structured and unstructured datapipeline, we observe Anthropic’s Claude 2 on Amazon Bedrock generated better overall results for our final datapipeline. Did anyone make an ace at the 2022 Shriners Children’s Open? Grace Lang is an Associate Data & ML engineer with AWS Professional Services.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python MLPipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python MLPipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
If we were to use RAG to converse with these reports, we could ask questions such as “What are the risks that faced company X in 2022,” or “What is the net revenue of company Y in 2022?” Consider the question: “What are the top 5 companies with the highest revenue in 2022?” Sort the revenues in descending order.
2022 will be remembered as a defining year for the crypto ecosystem. And we at deployr , worked alongside them to find the best possible answers for everyone involved and build their Data and MLPipelines. There’s an old saying in Argentina that goes: “A río revuelto, ganancia de pescadores”.
Both computer scientists and business leaders have taken note of the potential of the data. Machine learning (ML), a subset of artificial intelligence (AI), is an important piece of data-driven innovation. MLOps is the next evolution of data analysis and deep learning. What is MLOps?
The PdMS includes AWS services to securely manage the lifecycle of edge compute devices and BHS assets, cloud data ingestion, storage, machine learning (ML) inference models, and business logic to power proactive equipment maintenance in the cloud. It’s an easy way to run analytics on IoT data to gain accurate insights.
In this blog, we’ll show you how to build a robust energy price forecasting solution within the Snowflake Data Cloud ecosystem. We’ll cover how to get the data via the Snowflake Marketplace, how to apply machine learning with Snowpark , and then bring it all together to create an automated ML model to forecast energy prices.
The webinar hosts Eli Stein, Partner and Modern Marketing Capabilities Leader from McKinsey, Ze’ev Rispler, ML Engineer, from Iguazio (acquired by McKinsey), and myself. In 2022, “AI everywhere” has enabled zero marginal cost of content generation. Watch the entire webinar here. This results in money being left on the table.
DagsHub DagsHub is a centralized Github-based platform that allows Machine Learning and Data Science teams to build, manage and collaborate on their projects. In addition to versioning code, teams can also version data, models, experiments and more. It does not support the ‘dvc repro’ command to reproduce its datapipeline.
Jacomo Corbo is a Partner and Chief Scientist, and Bryan Richardson is an Associate Partner and Senior Data Scientist, for QuantumBlack AI by McKinsey. They presented “Automating Data Quality Remediation With AI” at Snorkel AI’s The Future of Data-Centric AI Summit in 2022. It has been lightly edited for reading clarity.
Jacomo Corbo is a Partner and Chief Scientist, and Bryan Richardson is an Associate Partner and Senior Data Scientist, for QuantumBlack AI by McKinsey. They presented “Automating Data Quality Remediation With AI” at Snorkel AI’s The Future of Data-Centric AI Summit in 2022. It has been lightly edited for reading clarity.
Jacomo Corbo is a Partner and Chief Scientist, and Bryan Richardson is an Associate Partner and Senior Data Scientist, for QuantumBlack AI by McKinsey. They presented “Automating Data Quality Remediation With AI” at Snorkel AI’s The Future of Data-Centric AI Summit in 2022. It has been lightly edited for reading clarity.
Even the most sophisticated ML models, neural networks, or large language models require high-quality data to learn meaningful patterns. When bad data is inputted, it inevitably leads to poor outcomes. In 2022, the company ingested bad data from one of its major customers.
Data movements lead to high costs of ETL and rising data management TCO. The inability to access and onboard new datasets prolong the datapipeline’s creation and time to market. Contact phData today for any questions, advice, best practices, or data strategy services.
Three experts from Capital One ’s data science team spoke as a panel at our Future of Data-Centric AI conference in 2022. Please welcome to the stage, Senior Director of Applied ML and Research, Bayan Bruss; Director of Data Science, Erin Babinski; and Head of Data and Machine Learning, Kishore Mosaliganti.
Three experts from Capital One ’s data science team spoke as a panel at our Future of Data-Centric AI conference in 2022. Please welcome to the stage, Senior Director of Applied ML and Research, Bayan Bruss; Director of Data Science, Erin Babinski; and Head of Data and Machine Learning, Kishore Mosaliganti.
Jason Goldfarb, senior data scientist at State Farm , gave a presentation entitled “Reusable Data Cleaning Pipelines in Python” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. It has always amazed me how much time the data cleaning portion of my job takes to complete.
Jason Goldfarb, senior data scientist at State Farm , gave a presentation entitled “Reusable Data Cleaning Pipelines in Python” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. It has always amazed me how much time the data cleaning portion of my job takes to complete.
As the order of the variables in the resulting sentence is irrelevant when dealing with tabular data, a random permutation of the components is subsequently performed to improve the final performance of the model. Finally, it is possible to generate new synthetic data from the initial tabular data. Thanks for reading!
The release of ChatGPT in late 2022 introduced generative artificial intelligence to the general public and triggered a new wave of AI-oriented companies, products, and open-source projects that provide tools and frameworks to enable enterprise AI.
Data scientists use data-driven approaches to enable AI systems to make better predictions, optimize decision-making, and uncover hidden patterns that ultimately drive innovation and improve performance across various domains. It includes techniques like supervised, unsupervised, and reinforcement learning.
One of the most prevalent complaints we hear from ML engineers in the community is how costly and error-prone it is to manually go through the ML workflow of building and deploying models. Building end-to-end machine learning pipelines lets ML engineers build once, rerun, and reuse many times.
Purina used artificial intelligence (AI) and machine learning (ML) to automate animal breed detection at scale. The solution focuses on the fundamental principles of developing an AI/ML application workflow of data preparation, model training, model evaluation, and model monitoring. DynamoDB is used to store the pet attributes.
There comes a time when every ML practitioner realizes that training a model in Jupyter Notebook is just one small part of the entire project. Getting a workflow ready which takes your data from its raw form to predictions while maintaining responsiveness and flexibility is the real deal.
These activities cover disparate fields such as basic data processing, analytics, and machine learning (ML). ML is often associated with PBAs, so we start this post with an illustrative figure. The ML paradigm is learning followed by inference. The union of advances in hardware and ML has led us to the current day.
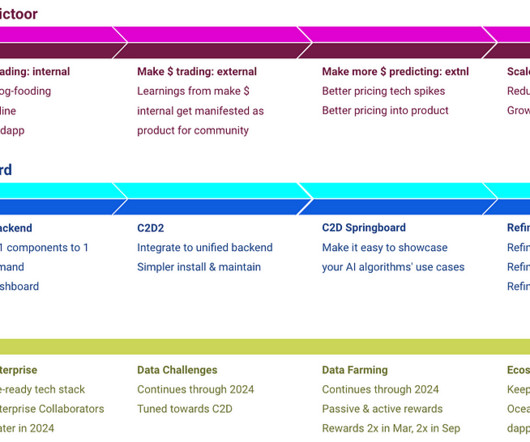
Simultaneously, build a first-class datapipeline and analytics dapp, to better answer the question “how much $ am I making” and drill-down questions. Continually improve datapipeline and analytics dapp. We’ve been running them since 2022. Data Farming (DF) DF is Ocean’s incentives program.
From gathering and processing data to building models through experiments, deploying the best ones, and managing them at scale for continuous value in production—it’s a lot. As the number of ML-powered apps and services grows, it gets overwhelming for data scientists and ML engineers to build and deploy models at scale.
Datapipelines that ingest data to the knowledge base should account for throttling and use backoff techniques. Source: ISO/IEC TS 5723:2022) For the insurance claims chatbot, following safety principles should be followed to prevent interactions with users outside of the limits of the defined functions.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content