This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
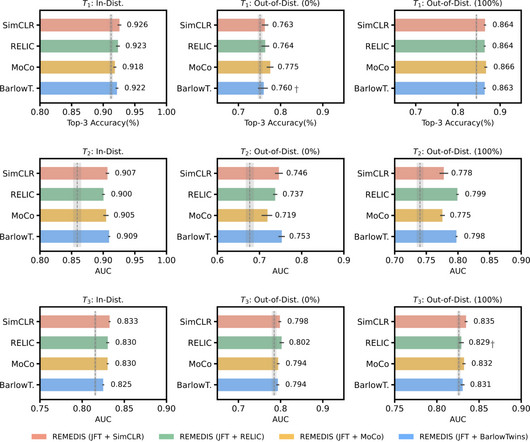
This problem of data-efficient generalization (a model’s ability to generalize to new settings using minimal new data) continues to be a key translational challenge for medical machine learning (ML) models and has in turn, prevented their broad uptake in real world healthcare settings.
According to Gartner, a renowned research firm, by 2022, an astounding 70% of customer interactions are expected to flow through technologies like machine learning applications, chatbots, and mobile messaging. Data Annotation in AI & ML At the heart of the Machine Learning (ML) journey lies the crucial step of data annotation.
Robust algorithm design is the backbone of systems across Google, particularly for our ML and AI models. Google Research has been at the forefront of this effort, developing many innovations from privacy-safe recommendation systems to scalable solutions for large-scale ML. You can find other posts in the series here.)
Please keep your eye on this space and look for the title “Google Research, 2022 & Beyond” for more articles in the series. With this post, I am kicking off a series in which researchers across Google will highlight some exciting progress we've made in 2022 and present our vision for 2023 and beyond.
NOTES, DEEP LEARNING, REMOTE SENSING, ADVANCED METHODS, SELF-SUPERVISEDLEARNING A note of the paper I have read Photo by Kelly Sikkema on Unsplash Hi everyone, In today’s story, I would share notes I took from 32 pages of Wang et al., 2022’s paper. 2022 Deep learning notoriously needs a lot of data in training.
Aleksandr Timashov is an ML Engineer with over a decade of experience in AI and Machine Learning. On these projects, I mentored numerous ML engineers, fostering a culture of innovation within Petronas. You told us you were implementing these projects in 2020-2022, so it all started amid the Covid-19 times.
Machine learning (ML) technologies can drive decision-making in virtually all industries, from healthcare to human resources to finance and in myriad use cases, like computer vision , large language models (LLMs), speech recognition, self-driving cars and more. However, the growing influence of ML isn’t without complications.
As part of its goal to help people live longer, healthier lives, Genomics England is interested in facilitating more accurate identification of cancer subtypes and severity, using machine learning (ML). 2022 ) was implemented (Section 2.1). by AWS, which aimed to mitigate the limitations of PORPOISE. Although Chen et al.,
In December 2022, DrivenData and Meta AI launched the Video Similarity Challenge. Between December 2022 and April 2023, 404 participants from 59 countries signed up to solve the problems posed by the two tracks, and 82 went on to submit solutions. student in ReLER, University of Technology Sydney, supervised by Yi Yang.
2022 was a big year for AI, and we’ve seen significant advancements in various areas – including natural language processing (NLP), machine learning (ML), and deep learning. Unsupervised and self-supervisedlearning are making ML more accessible by lowering the training data requirements.
Rapid, model-guided iteration with New Studio for all core ML tasks. Enhanced studio experience for all core ML tasks. Snorkel introduced Data-centric Foundation Model Development capabilities in November 2022 for enterprises to overcome these challenges and leverage foundation models in production. PDF extraction improvements.
(ii) We showcase the effectiveness of SSL-based TTA approaches for scene decomposition, while previous self-supervised test-time adaptation methods have primarily demonstrated results in classification tasks. 2021) with test time adaptation using BYOL self-supervised loss of MT3 (Bartler et al.
Amazon Forecast is a fully managed service that uses machine learning (ML) algorithms to deliver highly accurate time series forecasts. Initially, daily forecasts for each country are formulated through ML models. These daily predictions are subsequently broken down into hourly segments, as depicted in the following graph.
Once you’re past prototyping and want to deliver the best system you can, supervisedlearning will often give you better efficiency, accuracy and reliability than in-context learning for non-generative tasks — tasks where there is a specific right answer that you want the model to find. That’s not a path to improvement.
As shown in the following table, many of the top-selling drugs in 2022 were either proteins (especially antibodies) or other molecules like mRNA translated into proteins in the body. Name Manufacturer 2022 Global Sales ($ billions USD) Indications Comirnaty Pfizer/BioNTech $40.8 Top companies and drugs by sales in 2022.
Machine learning (ML), a subset of artificial intelligence (AI), is an important piece of data-driven innovation. Machine learning engineers take massive datasets and use statistical methods to create algorithms that are trained to find patterns and uncover key insights in data mining projects. What is MLOps?
Anirudh Koul is Machine Learning Lead for the NASA Frontier Development Lab and the Head of Machine Learning Sciences at Pinterest. He presented at Snorkel AI’s 2022 Future of Data Centric AI (FDCAI) Conference. And that’s the power of self-supervisedlearning. A transcript of Koul’s talk is provided below.
Anirudh Koul is Machine Learning Lead for the NASA Frontier Development Lab and the Head of Machine Learning Sciences at Pinterest. He presented at Snorkel AI’s 2022 Future of Data Centric AI (FDCAI) Conference. And that’s the power of self-supervisedlearning. A transcript of Koul’s talk is provided below.
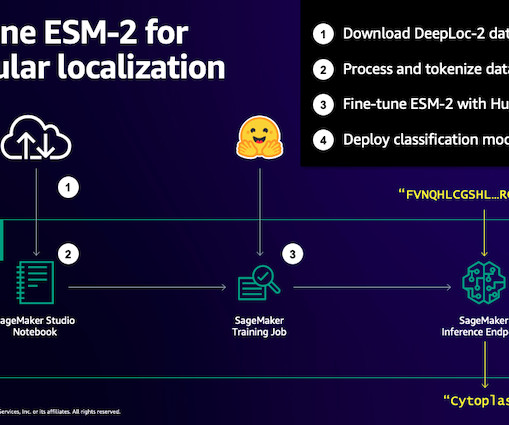
Since the advent of deep learning in the 2000s, AI applications in healthcare have expanded. Machine Learning Machine learning (ML) focuses on training computer algorithms to learn from data and improve their performance, without being explicitly programmed. A few AI technologies are empowering drug design.
Understanding Machine Learning algorithms and effective data handling are also critical for success in the field. Introduction Machine Learning ( ML ) is revolutionising industries, from healthcare and finance to retail and manufacturing. The global Machine Learning market was valued at USD 35.80 billion in 2023 to $181.15
Reminder : Training data refers to the data used to train an AI model, and commonly there are three techniques for it: Supervisedlearning: The AI model learns from labeled data, which means that each data point has a known output or target value. In March of 2022, DeepMind released Chinchilla AI.
Reminder : Training data refers to the data used to train an AI model, and commonly there are three techniques for it: Supervisedlearning: The AI model learns from labeled data, which means that each data point has a known output or target value. In March of 2022, DeepMind released Chinchilla AI.
Foundation models are large AI models trained on enormous quantities of unlabeled data—usually through self-supervisedlearning. What is self-supervisedlearning? Self-supervisedlearning is a kind of machine learning that creates labels directly from the input data. Find out in the guide below.
in 2022, according to the PYPL Index. Its robust ecosystem of libraries and frameworks tailored for Data Science, such as NumPy, Pandas, and Scikit-learn, contributes significantly to its popularity. Its versatility enables it to be applied in various domains, including web development, automation, Data Analysis, and more.
supervisedlearning and time series regression). Note: the DataRobot platform supports both supervised and unsupervised learning. Configuring an ML project. To begin training your model, just hit the Start button and let the DataRobot platform train ML models for you. AI Experience 2022 Recordings.
Abhishek Ratna, in AI ML marketing, and TensorFlow developer engineer Robert Crowe, both from Google, spoke as part of a panel entitled “Practical Paths to Data-Centricity in Applied AI” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. And in supervisedlearning, it has to be labeled data.
Abhishek Ratna, in AI ML marketing, and TensorFlow developer engineer Robert Crowe, both from Google, spoke as part of a panel entitled “Practical Paths to Data-Centricity in Applied AI” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. And in supervisedlearning, it has to be labeled data.
Abhishek Ratna, in AI ML marketing, and TensorFlow developer engineer Robert Crowe, both from Google, spoke as part of a panel entitled “Practical Paths to Data-Centricity in Applied AI” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. And in supervisedlearning, it has to be labeled data.
Established in 1987 at the University of California, Irvine, it has become a global go-to resource for ML practitioners and researchers. The global Machine Learning market continues to expand. billion in 2022 and is projected to reach USD 505.42 What is the UCI Machine Learning Repository? It was valued at USD 35.80
Prasanna Balaprakash, research and development lead from Argonne National Laboratory gave a presentation entitled “Extracting the Impact of Climate Change from Scientific Literature using Snorkel-Enabled NLP” at Snorkel AI’s Future of Data-Centric AI Workshop in August, 2022. One way that we did is using weak supervisedlearning.
Prasanna Balaprakash, research and development lead from Argonne National Laboratory gave a presentation entitled “Extracting the Impact of Climate Change from Scientific Literature using Snorkel-Enabled NLP” at Snorkel AI’s Future of Data-Centric AI Workshop in August, 2022. One way that we did is using weak supervisedlearning.
Generative AI Overview According to McKinsey , Generative AI is “a type of AI that can create new data (text, code, images, video) using patterns it has learned by training on extensive (public) data with machine learning (ML) techniques.” These include unsupervised or semi-supervisedlearning.
U-Net , U-Net++ ], whereas unsupervised learning eliminates this requirement [see this r eview paper ]. Semi-supervisedlearning lies in between supervised and unsupervised learning, which we will learn in detail in the following sections. What is Semi-supervisedLearning (SSL)?
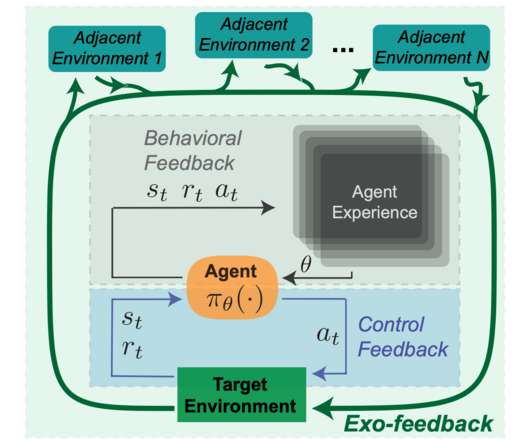
At the same time as the emergence of powerful RL systems in the real world, the public and researchers are expressing an increased appetite for fair, aligned, and safe machine learning systems. However the unique ability of RL systems to leverage temporal feedback in learning complicates the types of risks and safety concerns that can arise.
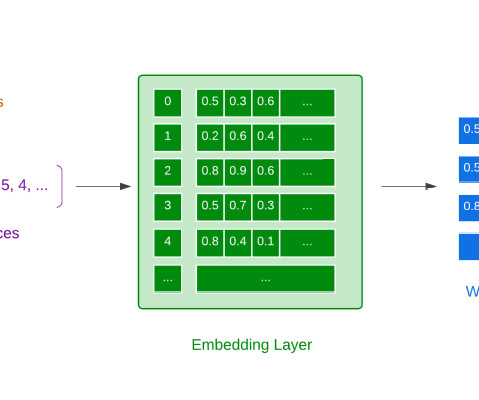
Data2Vec: A General Framework For Self-SupervisedLearning in Speech, Vision and Language. Check out my introductory article here that acts as a roadmap through the architecture. References Baevski, A., and Auli, M., Available from: [link]. Bojanowski, P., and Mikolov, T., Enriching Word Vectors with Subword Information. arXiv.org.
The process involves supervisedlearning (SL) and reinforcement learning (RL) phases. Editorially independent, Heartbeat is sponsored and published by Comet, an MLOps platform that enables data scientists & ML teams to track, compare, explain, & optimize their experiments.
Before we discuss the above related to kernels in machine learning, let’s first go over a few basic concepts: Support Vector Machine , S upport Vectors and Linearly vs. Non-linearly Separable Data. Support Vector Machine Support Vector Machine ( SVM ) is a supervisedlearning algorithm used for classification and regression analysis.
Curtis Northcutt, CEO and co-founder of Cleanlab, presented the tools his company developed for cleansing data sets prior to model training at the 2022 Future of Data-Centric AI conference. First I’ll chat a bit about millions of label errors and the 10 most common machine learning benchmark data sets. What would we get?
Curtis Northcutt, CEO and co-founder of Cleanlab, presented the tools his company developed for cleansing data sets prior to model training at the 2022 Future of Data-Centric AI conference. First I’ll chat a bit about millions of label errors and the 10 most common machine learning benchmark data sets. What would we get?
Chip Huyen, co-founder and CEO of Claypot AI gave a presentation entitled “Platform for Real-Time Machine Learning” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. I’m a co-founder of Claypot AI, and I assist with machine learning AI systems designed at Stanford. Hello, my name is Chip.
Chip Huyen, co-founder and CEO of Claypot AI gave a presentation entitled “Platform for Real-Time Machine Learning” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. I’m a co-founder of Claypot AI, and I assist with machine learning AI systems designed at Stanford. Hello, my name is Chip.
International Conference on Learning Representations. [20] 20] Once you have your instruction data, you split it into training, validation, and test sets, like in standard supervisedlearning. The researchers adopt the style from Jordan Hoffmann et al. “An An empirical analysis of compute-optimal large language model training.”
As the number of ML-powered apps and services grows, it gets overwhelming for data scientists and ML engineers to build and deploy models at scale. Supporting the operations of data scientists and ML engineers requires you to reduce—or eliminate—the engineering overhead of building, deploying, and maintaining high-performance models.
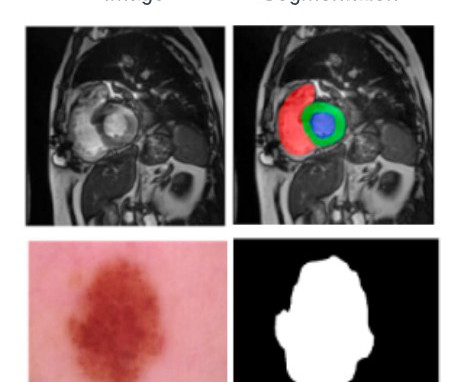
The ability to automate this process using machine learning (ML) techniques allows healthcare professionals to more quickly diagnose certain cancers, coronary diseases, and ophthalmologic conditions. This user-friendly approach eliminates the steep learning curve associated with ML, which frees up clinicians to focus on their patients.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content