This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Improve Cluster Balance with the CPD Scheduler — Part 1 The default Kubernetes (“k8s”) scheduler can be thought of as a sort of “greedy” scheduler, in that it always tries to place pods on the nodes that have the most free resources. It became apparent that the default Kubernetes scheduler algorithm was the culprit.
Hash joins and sort-merge joins have been considered the algorithms of choice for analytical relational queries in most parallel database systems because of their performance robustness and ease of parallelization. In this paper, we revisit the potential of nested loop joins in a cluster environment.
Editor’s note: Ali Rossi is a speaker for ODSC East 2023 this May 9th-11th. One of the simplest and most popular methods for creating audience segments is through K-means clustering, which uses a simple algorithm to group consumers based on their similarities in areas such as actions, demographics, attitudes, etc.
Posted by Vincent Cohen-Addad and Alessandro Epasto, Research Scientists, Google Research, Graph Mining team Clustering is a central problem in unsupervised machine learning (ML) with many applications across domains in both industry and academic research more broadly. When clustering is applied to personal data (e.g.,
Solving this problem requires a robust and high-speed network infrastructure as well as efficient data transfer protocols and algorithms. This includes developing new algorithms and techniques for efficient large-scale training and integrating new software tools and frameworks into our infrastructure.
This involves collecting and analyzing data to identify insights and develop solutions, such as predictive models, visualizations, or machine learning algorithms. Volunteer for ODSC East 2023 ODSC volunteers are an integral part of the success of each ODSC conference and a perfect extension of our core team and ambassadors to our community!
The game-changing technological marvels have got everyone talking and has to be topping the charts in 2023. A large language model, referred to as an LLM, is an advanced machine learning algorithm capable of identifying, condensing, translating, predicting, and generating various forms of text and content using extensive datasets.
Hype Cycle for Emerging Technologies 2023 (source: Gartner) Despite AI’s potential, the quality of input data remains crucial. Algorithms can automatically clean and preprocess data using techniques like outlier and anomaly detection. GenAI can now assist in direct data mapping and cleaning by identifying and fixing inconsistencies.
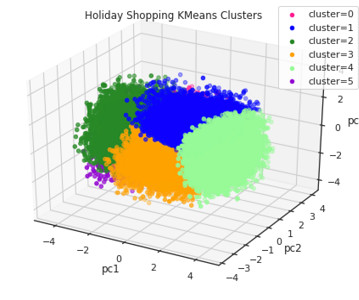
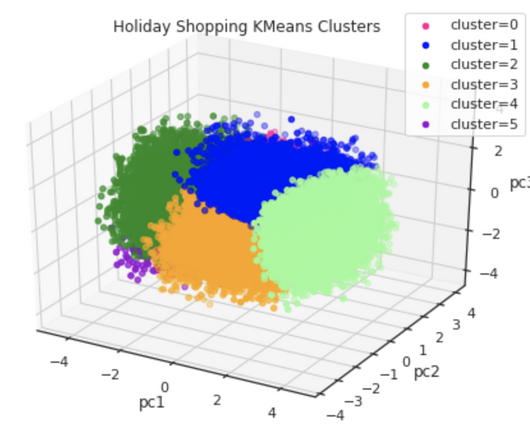
Last Updated on October 21, 2023 by Editorial Team Author(s): Flo Originally published on Towards AI. Using n_init and K-Means++ image by Flo K-Means is a widely-used clusteringalgorithm in Machine Learning, boasting numerous benefits but also presenting significant challenges. Each cluster is represented by a color.
Intelligent data classification Intelligent data classification is a process where artificial intelligence (AI) algorithms are used to automatically categorize and classify data based on its content, relevance, and importance; getting data ready for archiving. There are several ways to use AI for data archiving.
We’re excited to announce some of the incredible and totally new sessions we have coming to ODSC East May 9th — 11th, 2023 in Boston and online. You’ll also explore centrality metrics, networking density, various layout algorithms, and strategies for interpreting and communicating graph data. Register for ODSC East 2023 now.
As you delve into the landscape of MLOps in 2023, you will find a plethora of tools and platforms that have gained traction and are shaping the way models are developed, deployed, and monitored. Open-source tools have gained significant traction due to their flexibility, community support, and adaptability to various workflows.
Computer vision with Python and OpenCV Computer vision is a field of artificial intelligence that focuses on the development of algorithms and models that can interpret and understand visual information. One project idea in this area could be to build a facial recognition system using Python and OpenCV.
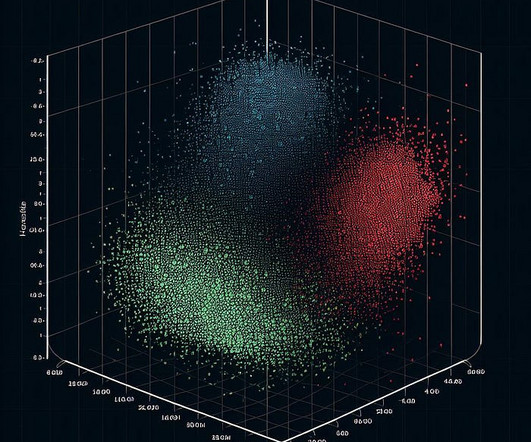
How this machine learning model has become a sustainable and reliable solution for edge devices in an industrial network An Introduction Clustering (cluster analysis - CA) and classification are two important tasks that occur in our daily lives. 3 feature visual representation of a K-means Algorithm.
Last Updated on September 11, 2023 by Editorial Team Author(s): Magdalena Kortas Originally published on Towards AI. As the El Niño phenomenon approaches in the summer of 2023, there is a dual concern of record-breaking warmth and extreme aridity. You can also read this article on Kablamo Engineering Blog.
2023’s event, held in New Orleans in December, was no exception, showcasing groundbreaking research from around the globe. In the world of data science, few events garner as much attention and excitement as the annual Neural Information Processing Systems (NeurIPS) conference.
Posted by Catherine Armato, Program Manager, Google The Eleventh International Conference on Learning Representations (ICLR 2023) is being held this week as a hybrid event in Kigali, Rwanda. We are proud to be a Diamond Sponsor of ICLR 2023, a premier conference on deep learning, where Google researchers contribute at all levels.
NLP Skills for 2023 These skills are platform agnostic, meaning that employers are looking for specific skillsets, expertise, and workflows. TensorFlow is desired for its flexibility for ML and neural networks, PyTorch for its ease of use and innate design for NLP, and scikit-learn for classification and clustering.
Botnets Detection at Scale — Lesson Learned from Clustering Billions of Web Attacks into Botnets. In this session, you will learn how explainability can help you identify poor model performance or bias, as well as discuss the most commonly used algorithms, how they work, and how to get started using them.
Adaptive AI has risen as a transformational technological concept over the years, leading Gartner to name it as a top strategic tech trend for 2023. Unlike traditional AI, which follows set rules and algorithms and tends to fall apart when faced with obstacles, adaptive AI systems can modify their behavior based on their experiences.
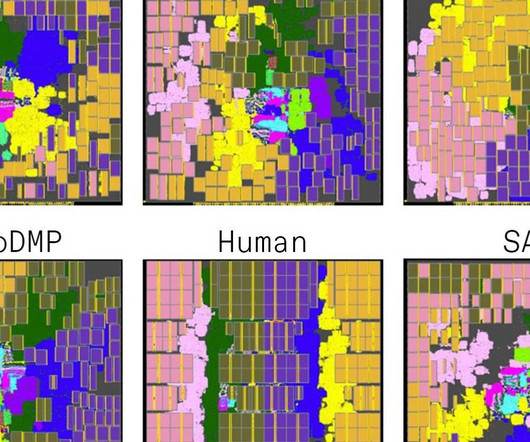
The crux of the clash was whether Google’s AI solution to one of chip design’s thornier problems was really better than humans or state-of-the-art algorithms. In Circuit Training and Morpheus, a separate algorithm fills in the gaps with the smaller parts, called standard cells. The agent places one block at a time on the chip canvas.
During the iterative research and development phase, data scientists and researchers need to run multiple experiments with different versions of algorithms and scale to larger models. However, building large distributed training clusters is a complex and time-intensive process that requires in-depth expertise.
Last Updated on April 17, 2023 by Editorial Team Author(s): Kevin Berlemont, PhD Originally published on Towards AI. In the second part, I will present and explain the four main categories of XML algorithms along with some of their limitations. Thus tail labels have an inflated score in the metric.
Last Updated on April 6, 2023 by Editorial Team Author(s): Ulrik Thyge Pedersen Originally published on Towards AI. The articles cover a range of topics, from the basics of Rust to more advanced machine learning concepts, and provide practical examples to help readers get started with implementing ML algorithms in Rust.
Last Updated on June 27, 2023 by Editorial Team Source: Unsplash This piece dives into the top machine learning developer tools being used by developers — start building! With an impressive collection of efficient tools and a user-friendly interface, it is ideal for tackling complex classification, regression, and cluster-based problems.
We build ML systems to solve deep scientific and engineering challenges in areas of language, music, visual processing, algorithm development, and more. Google is proud to be a Diamond Sponsor of the 40th International Conference on Machine Learning (ICML 2023), a premier annual conference, which is being held this week in Honolulu, Hawaii.
Mn in 2023, with an estimated CAGR of 11.8%, the importance of such techniques continues to rise. For instance, a classification algorithm could predict whether a transaction is fraudulent or not based on various features. As the data mining tools market grows, valued at US$ 1014.05
Python machine learning packages have emerged as the go-to choice for implementing and working with machine learning algorithms. The field of machine learning, known for its algorithmic complexity, has undergone a significant transformation in recent years. Why do you need Python machine learning packages?
We’re excited to announce that many CDS faculty, researchers, and students will present at the upcoming thirty-seventh 2023 NeurIPS (Neural Information Processing Systems) Conference , taking place Sunday, December 10 through Saturday, December 16. The conference will take place in-person at the New Orleans Ernest N.
Last Updated on July 18, 2023 by Editorial Team Author(s): Muttineni Sai Rohith Originally published on Towards AI. Later on, we will train a classifier for Car Evaluation data, by Encoding the data, Feature extraction and Developing classifier model using various algorithms and evaluate the results.
To find out, we’ve taken some of the upcoming tutorials and workshops from ODSC West 2023 and let the experts via their topics guide us toward building better machine learning. The process begins with a careful observation of customer data and an assessment of whether there are naturally formed clusters in the data.
The two most common types of supervised learning are classification , where the algorithm predicts a categorical label, and regression , where the algorithm predicts a numerical value. Unsupervised Learning In this type of learning, the algorithm is trained on an unlabeled dataset, where no correct output is provided.
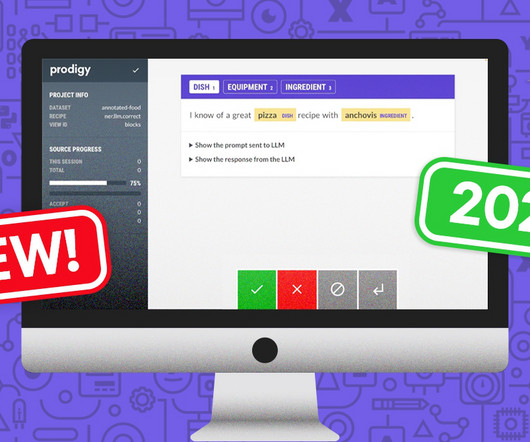
Throughout 2023, we have introduced support for Large Language Models (LLMs) through spacy-llm, added customizable task routing, expanded our QA features with inter-annotator agreement metrics, infused more interactivity into the UI, and shared several open-source Prodigy plug-ins with the community. are our biggest in almost two years.
People don’t even need the in-depth knowledge of the various machine learning algorithms as it contains pre-built libraries. PyTorch PyTorch is a popular, open-source, and lightweight machine learning and deep learning framework built on the Lua-based scientific computing framework for machine learning and deep learning algorithms.
Their expertise lies in designing algorithms, optimizing models, and integrating them into real-world applications. They possess a deep understanding of machine learning algorithms, data structures, and programming languages.
Computer Hardware At the core of any Generative AI system lies the computer hardware, which provides the necessary computational power to process large datasets and execute complex algorithms. The demand for advanced hardware continues to grow as organisations seek to develop more sophisticated Generative AI applications.
We can analyze activities by identifying stops made by the user or mobile device by clustering pings using ML models in Amazon SageMaker. A cluster of pings represents popular spots where devices gathered or stopped, such as stores or restaurants. Manually managing a DIY compute cluster is slow and expensive.
You’ll get hands-on practice with unsupervised learning techniques, such as K-Means clustering, and classification algorithms like decision trees and random forest. Finally, you’ll explore how to handle missing values and training and validating your models using PySpark.
Last Updated on May 9, 2023 by Editorial Team Author(s): Sriram Parthasarathy Originally published on Towards AI. This code can cover a diverse array of tasks, such as creating a KMeans cluster, in which users input their data and ask ChatGPT to generate the relevant code.
Some machine learning algorithms, such as clustering and self-supervised learning , do not require data labels, but their direct business applications are limited. By combining signals and learning where they agree and disagree, the weak supervision algorithm learns when, where, and how much to trust each one.
Last Updated on July 24, 2023 by Editorial Team Author(s): Cristian Originally published on Towards AI. The algorithm learns from this data, understanding the relationship between the input and the output. This way, it might end up clustering spam emails together, not because it knew they were spam, but because it found patterns.
With a few taps on a mobile device, riders request a ride; then, Uber’s algorithms work to match them with the nearest available driver and calculate the optimal price. Automation enabled Uber to grow to their current state with more than 256 petabytes of data, 3,000 nodes and 12 clusters. But the simplicity ends there.
At Google, it was his responsibility to maintain and improve the quality of our core web search algorithms during a time of twenty-fold growth. After that, he worked as a quant at a hedge fund on a 600 GPU cluster. Taylor is a frequent speaker and writer on AI topics.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content