This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data engineering tools offer a range of features and functionalities, including data integration, data transformation, data quality management, workflow orchestration, and data visualization. Essential data engineering tools for 2023 Top 10 data engineering tools to watch out for in 2023 1.
Yes, the AWS re:Invent season is upon us and as always, the place to be is Las Vegas! are the sessions dedicated to AWS DeepRacer ! Generative AI is at the heart of the AWS Village this year. You marked your calendars, you booked your hotel, and you even purchased the airfare. And last but not least (and always fun!)
Prerequisites Before you dive into the integration process, make sure you have the following prerequisites in place: AWS account – You’ll need an AWS account to access and use Amazon Bedrock. You can interact with Amazon Bedrock using AWS SDKs available in Python, Java, Node.js, and more.
At AWS, we are transforming our seller and customer journeys by using generative artificial intelligence (AI) across the sales lifecycle. It will be able to answer questions, generate content, and facilitate bidirectional interactions, all while continuously using internal AWS and external data to deliver timely, personalized insights.
In November 2023, Broadcom finalized its acquisition (link resides outside ibm.com) of VMware for USD 69 billion, with an aim to enhance its multicloud strategy. Further to the acquisition, Broadcom decided to discontinue (link resides outside ibm.com) its AWS authorization to resell VMware Cloud on AWS as of 30 April 2024.
They are processing data across channels, including recorded contact center interactions, emails, chat and other digital channels. Solution requirements Principal provides investment services through Genesys Cloud CX, a cloud-based contact center that provides powerful, native integrations with AWS.
To make your data management processes easier, here’s a primer on datalakes, and our picks for a few datalake vendors worth considering. What is a datalake? First, a datalake is a centralized repository that allows users or an organization to store and analyze large volumes of data.
The solution: IBM databases on AWS To solve for these challenges, IBM’s portfolio of SaaS database solutions on Amazon Web Services (AWS), enables enterprises to scale applications, analytics and AI across the hybrid cloud landscape. Let’s delve into the database portfolio from IBM available on AWS.
As you delve into the landscape of MLOps in 2023, you will find a plethora of tools and platforms that have gained traction and are shaping the way models are developed, deployed, and monitored. For example, if you use AWS, you may prefer Amazon SageMaker as an MLOps platform that integrates with other AWS services.
Amazon Bedrock offers a serverless experience, so you can get started quickly, privately customize FMs with your own data, and quickly integrate and deploy them into your applications using the AWS tools without having to manage the infrastructure. The Lambda function invokes an AWS Glue job and monitors for completion.
The role of a data scientist is in demand and 2023 will be no exception. To get a better grip on those changes we reviewed over 25,000 data scientist job descriptions from that past year to find out what employers are looking for in 2023. However, each year the skills and certainly the platforms change somewhat.
In 2023, eSentire was looking for ways to deliver differentiated customer experiences by continuing to improve the quality of its security investigations and customer communications. eSentire has over 2 TB of signal data stored in their Amazon Simple Storage Service (Amazon S3) datalake. Solutions Architect in AWS.
Note : Cloud Data warehouses like Snowflake and Big Query already have a default time travel feature. However, this feature becomes an absolute must-have if you are operating your analytics on top of your datalake or lakehouse. It can also be integrated into major data platforms like Snowflake. Contact phData Today!
On December 6 th -8 th 2023, the non-profit organization, Tech to the Rescue , in collaboration with AWS, organized the world’s largest Air Quality Hackathon – aimed at tackling one of the world’s most pressing health and environmental challenges, air pollution. As always, AWS welcomes your feedback.
In 2023 and beyond, we expect the open source trend to continue, with steady growth in the adoption of tools like Feilong, Tessla, Consolez, and Zowe. With the emergence of cloud hyperscalers like AWS, Google, and Microsoft, the shift to the cloud has accelerated significantly.
Explore VMware Modernization Assessment In this blog, we will share how IBM Consulting can help organizations with a preference for AWS-based cloud-native technologies, leveraging the contemporary tools and modern cloud services that AWS has to offer.
These teams are as follows: Advanced analytics team (datalake and data mesh) – Data engineers are responsible for preparing and ingesting data from multiple sources, building ETL (extract, transform, and load) pipelines to curate and catalog the data, and prepare the necessary historical data for the ML use cases.
Companies have plenty of data at their disposal and are looking for people who can make sense of it and make deductions quickly and efficiently. We looked at over 25,000 job descriptions, and these are the data analytics platforms, tools, and skills that employers are looking for in 2023. Sign up now, start learning today !
Overall, implementing a modern data architecture and generative AI techniques with AWS is a promising approach for gleaning and disseminating key insights from diverse, expansive data at an enterprise scale. AWS also offers foundation models through Amazon SageMaker JumpStart as Amazon SageMaker endpoints.
Choosing a DataLake Format: What to Actually Look For The differences between many datalake products today might not matter as much as you think. When choosing a datalake, here’s something else to consider. When choosing a datalake, here’s something else to consider.
It includes sensor devices to capture vibration and temperature data, a gateway device to securely transfer data to the AWS Cloud, the Amazon Monitron service that analyzes the data for anomalies with ML, and a companion mobile app to track potential failures in your machinery.
In fact, in a 2023 BMC survey , 92% of respondents said they see the mainframe as a platform for long-term growth and new workloads. With the emergence of cloud hyperscalers like AWS, Google, and Microsoft, the shift to the cloud has accelerated significantly. The mainframe is alive and well, and it’s not going anywhere anytime soon.
Watsonx.data is built on 3 core integrated components: multiple query engines, a catalog that keeps track of metadata, and storage and relational data sources which the query engines directly access. Integrations between watsonx.data and AWS solutions include Amazon S3, EMR Spark, and later this year AWS Glue, as well as many more to come.
These tools may have their own versioning system, which can be difficult to integrate with a broader data version control system. For instance, our datalake could contain a variety of relational and non-relational databases, files in different formats, and data stored using different cloud providers. DVC Git LFS neptune.ai
Role of Data Engineers in the Data Ecosystem Data Engineers play a crucial role in the data ecosystem by bridging the gap between raw data and actionable insights. They are responsible for building and maintaining data architectures, which include databases, data warehouses, and datalakes.
Allison (Ally) Witherspoon Johnston Senior Vice President, Product Marketing, Tableau Bronwen Boyd December 7, 2022 - 11:16pm February 14, 2023 In the quest to become a customer-focused company, the ability to quickly act on insights and deliver personalized customer experiences has never been more important.
The use of separate data warehouses and lakes has created data silos, leading to problems such as lack of interoperability, duplicate governance efforts, complex architectures, and slower time to value. You can use Amazon SageMaker Lakehouse to achieve unified access to data in both data warehouses and datalakes.
If you answer “yes” to any of these questions, you will need cloud storage, such as Amazon AWS’s S3, Azure DataLake Storage or GCP’s Google Storage. That’s why it’s so valuable to have experienced data engineers on your side, like the ones here at phData.
But it has been sunset by its original creator in April 2023, who recommends switching to JupySQL , which is an actively maintained fork. This typically involves dealing with complexities such as ensuring secure and simple access to internal data warehouses, datalakes, and databases.
3 Quickly build and deploy an end-to-end ML pipeline with Kubeflow Pipelines on AWS. The pipelines are interoperable to build a working system: Data (input) pipeline (data acquisition and feature management steps) This pipeline transports raw data from one location to another. What is a machine learning pipeline?
Customers use Amazon Redshift as a key component of their data architecture to drive use cases from typical dashboarding to self-service analytics, real-time analytics, machine learning (ML), data sharing and monetization, and more.
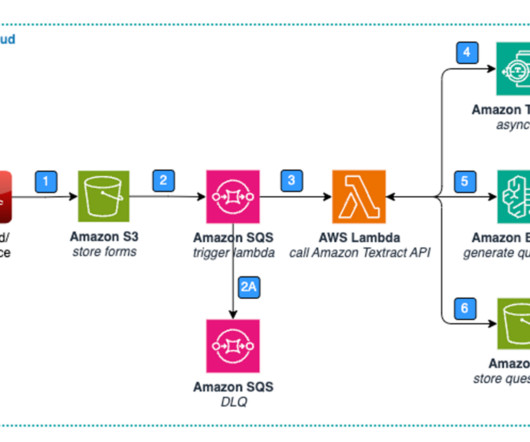
The AWS Glue job calls Amazon Textract , an ML service that automatically extracts text, handwriting, layout elements, and data from scanned documents, to process the input PDF documents. After data is extracted, the job performs document chunking, data cleanup, and postprocessing.
If your organization runs its workloads on AWS , it might be worth it to leverage AWS SageMaker. Solution Datalakes and warehouses are the two key components of any data pipeline. The datalake is a platform where any kind or amount of data can be stored, processed, and analyzed.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content