This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
These tools provide data engineers with the necessary capabilities to efficiently extract, transform, and load (ETL) data, build datapipelines, and prepare data for analysis and consumption by other applications. Essential data engineering tools for 2023 Top 10 data engineering tools to watch out for in 2023 1.
In marketing, for example, AI helps organizations extract actionable insights from vast data sets, leading to targeted campaigns and better customer engagement. Hype Cycle for Emerging Technologies 2023 (source: Gartner) Despite AI’s potential, the quality of input data remains crucial.
NLP Skills for 2023 These skills are platform agnostic, meaning that employers are looking for specific skillsets, expertise, and workflows. The chart below shows 20 in-demand skills that encompass both NLP fundamentals and broader data science expertise. Google Cloud is starting to make a name for itself as well.
As you delve into the landscape of MLOps in 2023, you will find a plethora of tools and platforms that have gained traction and are shaping the way models are developed, deployed, and monitored. It provides tools and components to facilitate end-to-end ML workflows, including data preprocessing, training, serving, and monitoring.
The US nationwide fraud losses topped $10 billion in 2023, a 14% increase from 2022. It seems straightforward at first for batch data, but the engineering gets even more complicated when you need to go from batch data to incorporating real-time and streaming data sources, and from batch inference to real-time serving.
Image Source — Pixel Production Inc In the previous article, you were introduced to the intricacies of datapipelines, including the two major types of existing datapipelines. You might be curious how a simple tool like Apache Airflow can be powerful for managing complex datapipelines.
This is enforced with the `more` excerpt separator. --> AI caught everyone’s attention in 2023 with Large Language Models (LLMs) that can be instructed to perform general tasks, such as translation or coding, just by prompting. AI applications have always required careful monitoring of both model outputs and datapipelines to run reliably.
Thirty seconds is a good default for human users; if you find that queries are regularly queueing, consider making your warehouse a multi-cluster that scales on-demand. Cluster Count If your warehouse has to serve many concurrent requests, you may need to increase the cluster count to meet demand.
Key skills and qualifications for machine learning engineers include: Strong programming skills: Proficiency in programming languages such as Python, R, or Java is essential for implementing machine learning algorithms and building datapipelines.
Effective data governance enhances quality and security throughout the data lifecycle. What is Data Engineering? Data Engineering is designing, constructing, and managing systems that enable data collection, storage, and analysis. The global data warehouse as a service market was valued at USD 9.06
HPCC Systems and Spark also differ in that they work with distinct parts of the big datapipeline. Spark is more focused on data science, ingestion, and ETL, while HPCC Systems focuses on ETL and data delivery and governance. You describe HPCC Systems as a complete data lake platform. Can you get more granular?
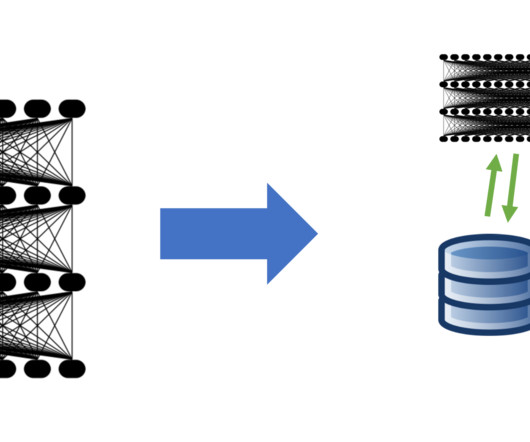
Learning means identifying and capturing historical patterns from the data, and inference means mapping a current value to the historical pattern. The following figure illustrates the idea of a large cluster of GPUs being used for learning, followed by a smaller number for inference.
Context In early 2023, Zeta’s machine learning (ML) teams shifted from traditional vertical teams to a more dynamic horizontal structure, introducing the concept of pods comprising diverse skill sets. Additionally, Feast promotes feature reuse, so the time spent on data preparation is reduced greatly.
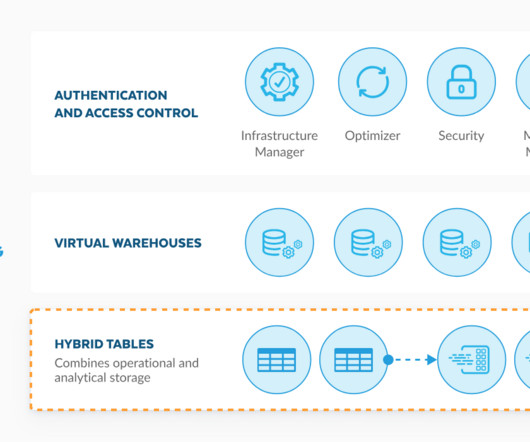
As an Elite consulting partner of Snowflake and their 2023 Partner of the Year , phData gets early access to new Snowflake features. Hybrid tables can streamline datapipelines, reduce costs, and unlock deeper insights from data. The post What are Snowflake Hybrid Tables, and What Workloads Do They Support?
How Snowflake Helps Achieve Real-Time Analytics Snowflake is the ideal platform to achieve real-time analytics for several reasons, but two of the biggest are its ability to manage concurrency due to the multi-cluster architecture of Snowflake and its robust connections to 3rd party tools like Kafka.
Introduction Big Data continues transforming industries, making it a vital asset in 2025. The global Big Data Analytics market, valued at $307.51 billion in 2023, is projected to grow to $348.21 DataNodes store the actual data blocks and respond to requests from the NameNode. What are Some Popular Big Data tools?
Thus, the solution allows for scaling data workloads independently from one another and seamlessly handling data warehousing, data lakes , data sharing, and engineering. With the help of Snowflake clusters, organizations can effectively deal with both rush times and slowdowns since they ensure scalability upon demand.
To establish trust between the data producers and data consumers, SageMaker Catalog also integrates the data quality metrics and data lineage events to track and drive transparency in datapipelines.
from 2023 to 2030. Solution Design Creating a high-level architectural design that encompasses datapipelines, model training, deployment strategies, and integration with existing systems. Explore topics such as regression, classification, clustering, neural networks, and natural language processing. Lakhs to ₹ 56.7
This is enforced with the `more` excerpt separator. --> AI caught everyone’s attention in 2023 with Large Language Models (LLMs) that can be instructed to perform general tasks, such as translation or coding, just by prompting. AI applications have always required careful monitoring of both model outputs and datapipelines to run reliably.
What’s really important in the before part is having production-grade machine learning datapipelines that can feed your model training and inference processes. And that’s really key for taking data science experiments into production. Registration is now open for The Future of Data-Centric AI 2023.
What’s really important in the before part is having production-grade machine learning datapipelines that can feed your model training and inference processes. And that’s really key for taking data science experiments into production. Registration is now open for The Future of Data-Centric AI 2023.
Orchestrators are concerned with lower-level abstractions like machines, instances, clusters, service-level grouping, replication, and so on. Along with the schedulers, they are integral to managing the regular workflows your data scientists run and how the tasks in those workflows communicate with the ML platform.
Kedro Kedro is a Python library for building modular data science pipelines. Kedro assists you in creating data science workflows composed of reusable components, each with a “single responsibility,” to speed up datapipelining, improve data science prototyping, and promote pipeline reproducibility.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





























Let's personalize your content