This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The process of setting up and configuring a distributed training environment can be complex, requiring expertise in server management, cluster configuration, networking and distributed computing. To simplify infrastructure setup and accelerate distributed training, AWS introduced Amazon SageMaker HyperPod in late 2023.
Deeplearning models are typically highly complex. While many traditional machine learning models make do with just a couple of hundreds of parameters, deeplearning models have millions or billions of parameters. The reasons for this range from wrongly connected model components to misconfigured optimizers.
We pick the first week of December 2023 in this example. By utilizing the search_raster_data_collection function from SageMaker geospatial, we identified 8,581 unique Sentinel-2 images taken in the first week of December 2023. These batches are then evenly distributed across the machines in a cluster. format("/".join(tile_prefix),
Developing NLP tools isn’t so straightforward, and requires a lot of background knowledge in machine & deeplearning, among others. NLP Skills for 2023 These skills are platform agnostic, meaning that employers are looking for specific skillsets, expertise, and workflows.
Over the course of 2023, we rapidly scaled up our training clusters from 1K, 2K, 4K, to eventually 16K GPUs to support our AI workloads. Today, we’re training our models on two 24K-GPU clusters. We don’t expect this upward trajectory for AI clusters to slow down any time soon. But things have rapidly accelerated.
Modern model pre-training often calls for larger cluster deployment to reduce time and cost. In October 2022, we launched Amazon EC2 Trn1 Instances , powered by AWS Trainium , which is the second generation machine learning accelerator designed by AWS. We use Slurm as the cluster management and job scheduling system.
As you delve into the landscape of MLOps in 2023, you will find a plethora of tools and platforms that have gained traction and are shaping the way models are developed, deployed, and monitored. Metaflow Metaflow helps data scientists and machine learning engineers build, manage, and deploy data science projects.
Botnets Detection at Scale — Lesson Learned from Clustering Billions of Web Attacks into Botnets. You will use the same example to explore both approaches utilizing TensorFlow in a Colab notebook.
Posted by Catherine Armato, Program Manager, Google The Eleventh International Conference on Learning Representations (ICLR 2023) is being held this week as a hybrid event in Kigali, Rwanda. We are proud to be a Diamond Sponsor of ICLR 2023, a premier conference on deeplearning, where Google researchers contribute at all levels.
2023’s event, held in New Orleans in December, was no exception, showcasing groundbreaking research from around the globe. In the world of data science, few events garner as much attention and excitement as the annual Neural Information Processing Systems (NeurIPS) conference.
How this machine learning model has become a sustainable and reliable solution for edge devices in an industrial network An Introduction Clustering (cluster analysis - CA) and classification are two important tasks that occur in our daily lives. Industrial Internet of Things (IIoT) The Constraints Within the area of Industry 4.0,
These packages are built to handle various aspects of machine learning, including tasks such as classification, regression, clustering, dimensionality reduction, and more. In addition to machine learning-specific packages, there are also general-purpose scientific computing libraries that are commonly used in machine learning projects.
Facebook AI similarity search (FAISS) FAISS is used for similarity search and clustering dense vectors. PyTorch and TensorFlow These are commonly used deeplearning frameworks that offer immense flexibility in building RAG models. IBM used this mechanism during the US Open 2023 for live commentary.
Recent developments in deeplearning have led to increasingly large models such as GPT-3, BLOOM, and OPT, some of which are already in excess of 100 billion parameters. 32xlarge instance type, launching in early 2023, will increase this bandwidth to 1600 Gbps per instance. trn1.32xlarge 16 512 128 512 800 trn1n.32xlarge
Last Updated on June 27, 2023 by Editorial Team Source: Unsplash This piece dives into the top machine learning developer tools being used by developers — start building! In the rapidly expanding field of artificial intelligence (AI), machine learning tools play an instrumental role.
We’re excited to announce that many CDS faculty, researchers, and students will present at the upcoming thirty-seventh 2023 NeurIPS (Neural Information Processing Systems) Conference , taking place Sunday, December 10 through Saturday, December 16. The conference will take place in-person at the New Orleans Ernest N.
Figure 3: Latent space visualization of the closet (source: Kumar, “Autoencoder vs Variational Autoencoder (VAE): Differences,” Data Analytics , 2023 ). Figure 5: Architecture of Convolutional Autoencoder for Image Segmentation (source: Bandyopadhyay, “Autoencoders in DeepLearning: Tutorial & Use Cases [2023],” V7Labs , 2023 ).
The primary components include: Graphics Processing Units (GPUs) These are specially designed for parallel processing, making them ideal for training deeplearning models. Foundation Models Foundation models are pre-trained deeplearning models that serve as the backbone for various generative applications.
Adaptive AI has risen as a transformational technological concept over the years, leading Gartner to name it as a top strategic tech trend for 2023. Unsupervised Learning : The system learns patterns and structures in unlabeled data, often identifying hidden relationships or clustering similar data points.
We’re a few weeks removed from ODSC Europe 2023 and we couldn’t have left on a better note. Here are some highlights from ODSC Europe 2023, including some pictures of speakers and attendees, popular talks, and a summary of what kept people busy. That’s it for our ODSC Europe 2023 highlights! What’s next?
Today, many modern Speech-to-Text APIs and Speaker Diarization libraries apply advanced DeepLearning models to perform tasks (A) and (B) near human-level accuracy, significantly increasing the utility of Speaker Diarization APIs. An embedding is a DeepLearning model’s low-dimensional representation of an input.
However, building large distributed training clusters is a complex and time-intensive process that requires in-depth expertise. Amazon SageMaker HyperPod, introduced during re:Invent 2023, is a purpose-built infrastructure designed to address the challenges of large-scale training.
Last Updated on April 6, 2023 by Editorial Team Author(s): Ulrik Thyge Pedersen Originally published on Towards AI. The articles cover a range of topics, from the basics of Rust to more advanced machine learning concepts, and provide practical examples to help readers get started with implementing ML algorithms in Rust.
Below you’ll find just a few of the many expert-led sessions at ODSC Europe 2023 that attendees loved — and you can view them for yourself here ! And don’t miss the chance to join us for our upcoming free virtual Generative AI Summit on July 20th and ODSC West 2023 in San Francisco (October 31st-November 3rd). What’s next?
Gözde Gül Şahin | Assistant Professor, KUIS AI Fellow | KOC University Fraud Detection with Machine Learning: Laura Mitchell | Senior Data Science Manager | MoonPay DeepLearning and Comparisons between Large Language Models: Hossam Amer, PhD | Applied Scientist | Microsoft Multimodal Video Representations and Their Extension to Visual Language Navigation: (..)
Unsupervised Learning In this type of learning, the algorithm is trained on an unlabeled dataset, where no correct output is provided. Performance Metrics These are used to evaluate the performance of a machine-learning algorithm. Some popular libraries used for deeplearning are Keras , PyTorch , and TensorFlow.
It is mainly used for deeplearning applications. PyTorch PyTorch is a popular, open-source, and lightweight machine learning and deeplearning framework built on the Lua-based scientific computing framework for machine learning and deeplearning algorithms.
Nevertheless, we are still left with the question: How can we do machine learning better? To find out, we’ve taken some of the upcoming tutorials and workshops from ODSC West 2023 and let the experts via their topics guide us toward building better machine learning.
To learn how to develop Face Recognition applications using Siamese Networks, just keep reading. Jump Right To The Downloads Section Face Recognition with Siamese Networks, Keras, and TensorFlow Deeplearning models tend to develop a bias toward the data distribution on which they have been trained. That’s not the case.
You’ll get hands-on practice with unsupervised learning techniques, such as K-Means clustering, and classification algorithms like decision trees and random forest. Finally, you’ll explore how to handle missing values and training and validating your models using PySpark.
Last Updated on July 21, 2023 by Editorial Team Author(s): Ricky Costa Originally published on Towards AI. To further comment on Fury, for those looking to intern in the short term, we have a position available to work in an NLP deeplearning project in the healthcare domain. Fury What a week. Let’s recap.
Last Updated on April 17, 2023 by Editorial Team Author(s): Kevin Berlemont, PhD Originally published on Towards AI. The feature space reduction is performed by aggregating clusters of features of balanced size. This clustering is usually performed using hierarchical clustering.
Last Updated on July 19, 2023 by Editorial Team Author(s): Yashashri Shiral Originally published on Towards AI. This is part 2, and you will learn how to do sales prediction using Time Series.
The world of multi-view self-supervised learning (SSL) can be loosely grouped into four families of methods: contrastive learning, clustering, distillation/momentum, and redundancy reduction. This behavior appears to contradict the classical bias-variance tradeoff, which traditionally suggests a U-shaped error curve.
ClusteringClustering is a class of algorithms that segregates the data into a set of definite clusters such that similar points lie in the same cluster and dissimilar points lie in different clusters. Several clustering algorithms (e.g., means and spectral clustering) can be used in recommendation engines.
In today’s blog, we will see some very interesting Python Machine Learning projects with source code. This list will consist of Machine learning projects, DeepLearning Projects, Computer Vision Projects , and all other types of interesting projects with source codes also provided. This is a simple project.
Last Updated on May 9, 2023 by Editorial Team Author(s): Sriram Parthasarathy Originally published on Towards AI. This code can cover a diverse array of tasks, such as creating a KMeans cluster, in which users input their data and ask ChatGPT to generate the relevant code.
Jump Right To The Downloads Section A Deep Dive into Variational Autoencoder with PyTorch Introduction Deeplearning has achieved remarkable success in supervised tasks, especially in image recognition. Similar class labels tend to form clusters, as observed with the Convolutional Autoencoder. That’s not the case.
Learning means identifying and capturing historical patterns from the data, and inference means mapping a current value to the historical pattern. The following figure illustrates the idea of a large cluster of GPUs being used for learning, followed by a smaller number for inference.
Traditional AI can recognize, classify, and cluster, but not generate the data it is trained on. al 600+: Key technological concepts of generative AI 300+: DeepLearning — the core of any generative AI model: Deeplearning is a central concept of traditional AI that has been adopted and further developed in generative AI.
Top 15 Data Analytics Projects in 2023 for Beginners to Experienced Levels: Data Analytics Projects allow aspirants in the field to display their proficiency to employers and acquire job roles. Image Recognition with DeepLearning: Use Python with TensorFlow or PyTorch to build an image recognition model (e.g., ImageNet).
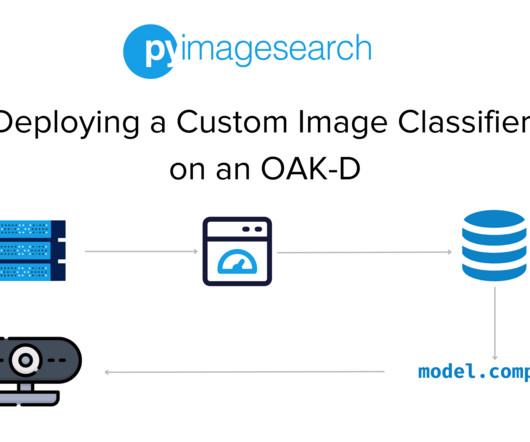
Jump Right To The Downloads Section Deploying a Custom Image Classifier on an OAK-D Introduction As a deeplearning engineer or practitioner, you may be working in a team building a product that requires you to train deeplearning models on a specific data modality (e.g., computer vision) on a daily basis.
I love participating in various competitions involving deeplearning, especially tasks involving natural language processing or LLMs. Issac Chan is a Machine Learning Engineer at Verto where he leverages advanced machine learning techniques to create impactful healthcare solutions. Alejandro A.
Even for basic inference on LLM, multiple accelerators or multi-node computing clusters like multiple Kubernetes pods are required. But the issue we found was that MP is efficient in single-node clusters, but in a multi-node setting, the inference isn’t efficient. For instance, a 1.5B This is because of the low bandwidth networks.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content