This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Using the “Top Spotify songs from 2010-2019” dataset on Kaggle ( [link] ), we read it into a Python – Pandas Data Frame. This is a default index created by python for this dataset, while considering the first column present in the csv file as an “unnamed” column. You may only build a single Primary or Clustered index on a table.
The process of setting up and configuring a distributed training environment can be complex, requiring expertise in server management, cluster configuration, networking and distributed computing. To simplify infrastructure setup and accelerate distributed training, AWS introduced Amazon SageMaker HyperPod in late 2023.
In this blog post, we’ll explore five project ideas that can help you build expertise in computer vision, natural language processing (NLP), sales forecasting, cancer detection, and predictive maintenance using Python. One project idea in this area could be to build a facial recognition system using Python and OpenCV.
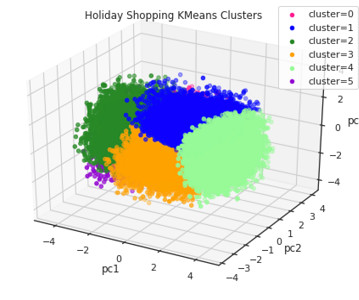
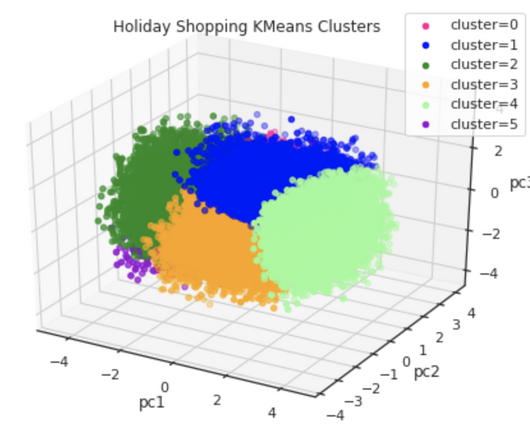
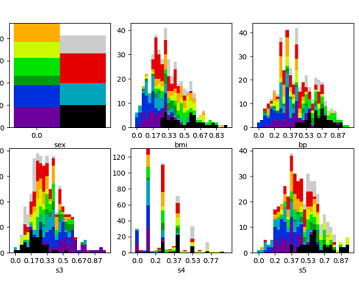
Editor’s note: Ali Rossi is a speaker for ODSC East 2023 this May 9th-11th. One of the simplest and most popular methods for creating audience segments is through K-means clustering, which uses a simple algorithm to group consumers based on their similarities in areas such as actions, demographics, attitudes, etc.
In 2023, data analysts will be expected to have a wide range of skills and knowledge to be effective in their roles. Skills for data analysts 2023 10 essential skills for data analysts to have in 2023 Here are 10 essential skills for data analysts to have in 2023: 1.
Essential data engineering tools for 2023 Top 10 data engineering tools to watch out for in 2023 1. It supports various data types and offers advanced features like data sharing and multi-cluster warehouses. It allows data engineers to store, manage, and analyze large datasets efficiently.
Volunteer for ODSC East 2023 ODSC volunteers are an integral part of the success of each ODSC conference and a perfect extension of our core team and ambassadors to our community! The final step is to implement and monitor the solution, refining it over time to ensure it delivers the desired outcomes.
The game-changing technological marvels have got everyone talking and has to be topping the charts in 2023. Code generation : LLMs can generate code, such as Python or Java code. The buzz surrounding large language models is wreaking havoc and for all the good reason! What are large language models?
Working on community projects improved my skills in Python, Jupyter, numpy, pandas, and ROS. Within a year, we built a world-class inference platform processing over 2 billion video frames daily using dynamically scaled Amazon Elastic Kubernetes Service (Amazon EKS) clusters.
Visualization for Clustering Methods Clustering methods are a big part of data science, and here’s a primer on how you can visualize them. ODSC APAC 2023 Now Available to Watch On-Demand ODSC APAC 2023 is now in the history books, and here’s how you can watch it all now and on-demand! Professor Mark A.
As you delve into the landscape of MLOps in 2023, you will find a plethora of tools and platforms that have gained traction and are shaping the way models are developed, deployed, and monitored. For example, if your team is proficient in Python and R, you may want an MLOps tool that supports open data formats like Parquet, JSON, CSV, etc.,
NLP Skills for 2023 These skills are platform agnostic, meaning that employers are looking for specific skillsets, expertise, and workflows. TensorFlow is desired for its flexibility for ML and neural networks, PyTorch for its ease of use and innate design for NLP, and scikit-learn for classification and clustering.
How this machine learning model has become a sustainable and reliable solution for edge devices in an industrial network An Introduction Clustering (cluster analysis - CA) and classification are two important tasks that occur in our daily lives. Industrial Internet of Things (IIoT) The Constraints Within the area of Industry 4.0,
Modern model pre-training often calls for larger cluster deployment to reduce time and cost. As part of a single cluster run, you can spin up a cluster of Trn1 instances with Trainium accelerators. Trn1 UltraClusters can host up to 30,000 Trainium devices and deliver up to 6 exaflops of compute in a single cluster.
Last Updated on June 27, 2023 by Editorial Team Source: Unsplash This piece dives into the top machine learning developer tools being used by developers — start building! With an impressive collection of efficient tools and a user-friendly interface, it is ideal for tackling complex classification, regression, and cluster-based problems.
Python machine learning packages have emerged as the go-to choice for implementing and working with machine learning algorithms. Acquiring proficiency in Python has become essential for individuals aiming to excel in these domains. Why do you need Python machine learning packages?
Facebook AI similarity search (FAISS) FAISS is used for similarity search and clustering dense vectors. Haystack It is a Python framework that is built on Elasticsearch. IBM used this mechanism during the US Open 2023 for live commentary. It plays a crucial role in building retrieval components of a system.
However, building large distributed training clusters is a complex and time-intensive process that requires in-depth expertise. Amazon SageMaker HyperPod, introduced during re:Invent 2023, is a purpose-built infrastructure designed to address the challenges of large-scale training.
Last Updated on May 9, 2023 by Editorial Team Author(s): Sriram Parthasarathy Originally published on Towards AI. Here is an example plot we will create by just asking in plain English to create 3 clusters (using kmeans) using income and spending variables, and present the breakdown of spending for each cluster without writing any code.
In today’s blog, we will see some very interesting Python Machine Learning projects with source code. This is one of the best Machine learning projects in Python. Doctor-Patient Appointment System in Python using Flask Hey guys, in this blog we will see a Doctor-Patient Appointment System for Hospitals built in Python using Flask.
Last Updated on April 6, 2023 by Editorial Team Author(s): Ulrik Thyge Pedersen Originally published on Towards AI. SmartCore SmartCore is a machine learning library written in Rust that provides a variety of algorithms for regression, classification, clustering, and more.
Engineers must manually write custom data preprocessing and aggregation logic in Python or Spark for each use case. For this post, we refer to the following notebook , which demonstrates how to get started with Feature Processor using the SageMaker Python SDK. 50195| 1686627154| | 6| Acura TLX A-Spec| 2023| New| NA|50195.00|50195|
One is a scripting language such as Python, and the other is a Query language like SQL (Structured Query Language) for SQL Databases. Python is a High-level, Procedural, and object-oriented language; it is also a vast language itself, and covering the whole of Python is one the worst mistakes we can make in the data science journey.
Using a clustering method, want to determine the greatest number of speakers that could reasonably be heard in the audio. Finally, Speaker Diarization models take the utterance embeddings (produced above), and cluster them into as many clusters as there are speakers. Note that pyAnnote.audio only supports Python 3.7,
Throughout 2023, we have introduced support for Large Language Models (LLMs) through spacy-llm, added customizable task routing, expanded our QA features with inter-annotator agreement metrics, infused more interactivity into the UI, and shared several open-source Prodigy plug-ins with the community. support (dropping Python 3.7
The GPU-powered interactive visualizer and Python notebooks provide a seamless way to explore millions of data points in a single window and share insights and results. We can analyze activities by identifying stops made by the user or mobile device by clustering pings using ML models in Amazon SageMaker.
Libraries The programming language used in this code is Python, complemented by the LangChain module, which is specifically designed to facilitate the integration and use of LLMs. For the classfier, we employed a classic ML algorithm, k-NN, using the scikit-learn Python module. This method takes a parameter, which we set to 3.
It supports languages like Python and R and processes the data with the help of data flow graphs. It is an open-source framework that is written in Python and can efficiently operate on both GPUs and CPUs. Keras supports a high-level neural network API written in Python. It is an open source framework.
Mn in 2023, with an estimated CAGR of 11.8%, the importance of such techniques continues to rise. Popular tools for implementing it include WEKA, RapidMiner, and Python libraries like mlxtend. RapidMiner supports various data mining operations, including classification, clustering, and association rule mining.
You’ll get hands-on practice with unsupervised learning techniques, such as K-Means clustering, and classification algorithms like decision trees and random forest. Finally, you’ll explore how to handle missing values and training and validating your models using PySpark.
Thrive in the Data Tooling Tornado Adam Breindel | Independent Consultant In this talk, Adam Breindel, a leading Apache Spark instructor and authority on neural-net fraud detection, streaming analytics and cluster management code, will help you navigate the data tooling landscape.
This blog was originally written by Keith Smith and updated for 2023 by Nick Goble & Dominick Rocco. Snowpark is the set of libraries and runtimes in Snowflake that securely deploy and process non-SQL code, including Python , Java, and Scala. But some workloads are particularly well-suited for Snowflake.
Python The code has been tested with Python version 3.13. For clarity of purpose and reading, weve encapsulated each of seven steps in its own Python script. Return to the command line, and execute the script: python create_invoke_role.py Return to the command line and execute the script: python create_connector_role.py
Last Updated on July 18, 2023 by Editorial Team Author(s): Muttineni Sai Rohith Originally published on Towards AI. For a detailed tutorial about Pyspark, Pyspark RDD, and DataFrame concepts, Handling missing values, refer to the link below: Pyspark For Beginners PySpark is a Python API for Apache Spark.
You can also access JumpStart models using the SageMaker Python SDK. In April 2023, AWS unveiled Amazon Bedrock , which provides a way to build generative AI-powered apps via pre-trained models from startups including AI21 Labs , Anthropic , and Stability AI. On the Amazon ECS console, you can see the clusters on the Clusters page.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
The year 2023 brings forth a multitude of trends that will shape the BI. Utilizing BI tools, Python scripts, and visualization techniques such as bar charts and tables, multiple sectors find a robust solution for financial analysis. The BI landscape continues to evolve, with innovative projects taking center stage.
Last Updated on July 19, 2023 by Editorial Team Author(s): Yashashri Shiral Originally published on Towards AI. Sales Prediction| Using Time Series| End-to-End Understanding| Part -2 Sales Forecasting determines how the company invests and grows to create a massive impact on company valuation.
Top 15 Data Analytics Projects in 2023 for Beginners to Experienced Levels: Data Analytics Projects allow aspirants in the field to display their proficiency to employers and acquire job roles. Following is a guide that can help you understand the types of projects and the projects involved with Python and Business Analytics.
When storing a vector index for your knowledge base in an Aurora database cluster, make sure that the table for your index contains a column for each metadata property in your metadata files before starting data ingestion. The response only cites sources that are relevant to the query.
Editor’s note: Dillon Bostwick and Avinash Sooriyarachchi are speakers for ODSC Europe 2023 this June 14th-15th. This function makes it easy to define custom aggregation functions in Python. Here, the Pandas UDF simplifies the hand-off between complex distributed event streaming and locally scoped Python functions.
SQL Primer Thursday, September 7th, 2023, 2 PM EST This SQL coding course teaches students the basics of Structured Query Language, which is a standard programming language used for managing and manipulating data and an essential tool in learning AI.
One of the hottest announcements at Snowflake Summit 2023 was the launch of Hex on Snowpark Container Services. Users can write SQL, Python, or R code to explore, transform, and visualize data. It’s incredibly simple to connect Hex to Snowflake and get to work with SQL or Python using Snowpark. What is Hex?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content