This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Datapipelines play a critical role in the processing and management of data in modern organizations. A well-designed datapipeline can help organizations extract valuable insights from their data, automate tedious manual processes, and ensure the accuracy of data processing.
These tools provide data engineers with the necessary capabilities to efficiently extract, transform, and load (ETL) data, build datapipelines, and prepare data for analysis and consumption by other applications. Essential data engineering tools for 2023 Top 10 data engineering tools to watch out for in 2023 1.
In marketing, for example, AI helps organizations extract actionable insights from vast data sets, leading to targeted campaigns and better customer engagement. Hype Cycle for Emerging Technologies 2023 (source: Gartner) Despite AI’s potential, the quality of input data remains crucial.
As you delve into the landscape of MLOps in 2023, you will find a plethora of tools and platforms that have gained traction and are shaping the way models are developed, deployed, and monitored. Open-source tools have gained significant traction due to their flexibility, community support, and adaptability to various workflows.
NLP Skills for 2023 These skills are platform agnostic, meaning that employers are looking for specific skillsets, expertise, and workflows. The chart below shows 20 in-demand skills that encompass both NLP fundamentals and broader data science expertise. Google Cloud is starting to make a name for itself as well.
As today’s world keeps progressing towards data-driven decisions, organizations must have quality data created from efficient and effective datapipelines. For customers in Snowflake, Snowpark is a powerful tool for building these effective and scalable datapipelines.
A new event to ODSC West 2023 were the Lightning talks, which saw a small group of victims (speakers) describe slides picked at random. While we may be done with events for 2023, 2024 is looking to be packed full of conferences, meetups, and virtual events. What’s next?
So how should companies ensure they are able to make agile, and more confident, decisions in 2023 and beyond? The answer lies in fueling strategic business decisions with trusted data – leveraging high-integrity data that is consistent, accurate, and contextual.
Great Expectations provides support for different data backends such as flat file formats, SQL databases, Pandas dataframes and Sparks, and comes with built-in notification and data documentation functionality. At ODSC East 2023, we have a number of sessions related to data visualization and data exploration tools.
Home Table of Contents Adversarial Learning with Keras and TensorFlow (Part 2): Implementing the Neural Structured Learning (NSL) Framework and Building a DataPipeline Adversarial Learning with NSL CIFAR-10 Dataset Configuring Your Development Environment Need Help Configuring Your Development Environment? We open our config.py
The role of a data scientist is in demand and 2023 will be no exception. To get a better grip on those changes we reviewed over 25,000 data scientist job descriptions from that past year to find out what employers are looking for in 2023. However, each year the skills and certainly the platforms change somewhat.
Automate and streamline our ML inference pipeline with SageMaker and Airflow Building an inference datapipeline on large datasets is a challenge many companies face. Airflow setup Apache Airflow is an open-source tool for orchestrating workflows and data processing pipelines. ", instance_type="ml.m5.xlarge",
If youre like many modern organizations, you may be managing data across an increasingly complex landscape of on-premises platforms, cloud services, and legacy systems and facing challenges in doing so. According to the 2023 Gartner Cloud End-User Behavior Survey, 81% of respondents use multiple cloud providers.
Image Source — Pixel Production Inc In the previous article, you were introduced to the intricacies of datapipelines, including the two major types of existing datapipelines. You might be curious how a simple tool like Apache Airflow can be powerful for managing complex datapipelines.
The Precisely team is excited to be part of Confluent’s Current 2023 conference, September 26 & 27. As a proud member of the Connect with Confluent program , we help organizations going through digital transformation and IT infrastructure modernization break down data silos and power their streaming datapipelines with trusted data.
In 2023 and beyond, we expect the open source trend to continue, with steady growth in the adoption of tools like Feilong, Tessla, Consolez, and Zowe. In 2023, expect to see broader adoption of streaming datapipelines that bring mainframe data to the cloud, offering a powerful tool for “modernizing in place.”
Advanced analytics and AI/ML continue to be hot data trends in 2023. According to a recent IDC study, “executives openly articulate the need for their organizations to be more data-driven, to be ‘data companies,’ and to increase their enterprise intelligence.” The post Data Trends for 2023 appeared first on Precisely.
Provide connectors for data sources: Orchestration frameworks typically provide connectors for a variety of data sources, such as databases, cloud storage, and APIs. This makes it easy to connect your datapipeline to the data sources that you need. It is known for its extensibility and modularity.
Using data from 1990 to 2023, we apply a robust datapipeline comprised of six machine learning models and sequential squeeze feature selection incorporating eleven economic, industrial, and energy consumption variables.
The US nationwide fraud losses topped $10 billion in 2023, a 14% increase from 2022. It seems straightforward at first for batch data, but the engineering gets even more complicated when you need to go from batch data to incorporating real-time and streaming data sources, and from batch inference to real-time serving.
Last Updated on March 21, 2023 by Editorial Team Author(s): Data Science meets Cyber Security Originally published on Towards AI. Navigating the World of Data Engineering: A Beginner’s Guide. A GLIMPSE OF DATA ENGINEERING ❤ IMAGE SOURCE: BY AUTHOR Data or data? What are ETL and datapipelines?
The Intersection of Data Science and Cloud Computing Data Science and cloud computing are revolutionising industries, enabling businesses to derive meaningful insights from vast amounts of data while leveraging the power of scalable, cost-efficient cloud platforms. billion in 2023 to USD 1,266.4
Hidden Technical Debt in Machine Learning Systems More money, more problems — Rise of too many ML tools 2012 vs 2023 — Source: Matt Turck People often believe that money is the solution to a problem. A feature platform should automatically process the datapipelines to calculate that feature. Spark, Flink, etc.)
Y Combinator Photo) Seattle-area startups that just graduated from Y Combinator’s summer 2023 batch are tackling a wide range of problems — with plenty of help from artificial intelligence. Neum AI at its core is an enabler for generative AI applications by helping connect data into vector databases and making it accessible for RAG.
ODSC West 2023 is just a couple of months away, and we couldn’t be more excited to be able to share our Preliminary Schedule with you! Day 1: Monday, October 30th (Bootcamp, VIP, Platinum) Day 1 of ODSC West 2023 will feature our hands-on training sessions, workshops, and tutorials and will be open to Platinum, Bootcamp, and VIP pass holders.
Please spend a few minutes browsing the apps and tools available in the phData Toolkit today to set yourself up for success in 2023. Explore the phData Toolkit The post phData Toolkit December 2023 Update appeared first on phData. Be sure to follow this series for more updates on the phData Toolkit tools and features.
This allows you to perform tasks such as ensuring data quality against data sources (once or over time), compare data metrics and metadata across environments, and create/manage datapipelines for all your tables and views. We look forward to hearing from all of you and to what 2023 brings!
Explore phData Toolkit The post phData Toolkit March 2023 Update appeared first on phData. We encourage you to spend a few minutes browsing the apps and tools available in the phData Toolkit today to set yourself up for success in 2022. Be sure to follow: this series for more updates on the phData Toolkit tools and features.
We encourage you to spend a few minutes browsing the apps and tools available in the phData Toolkit today to set yourself up for success in 2023. Explore the phData Toolkit The post phData Toolkit August 2023 Update appeared first on phData. Be sure to follow this series for more updates on the phData Toolkit tools and features.
Operational Risks identify operational risks such as data loss or failures in the event of an unforeseen outage or disaster. Performance Optimization identify and fix bottlenecks in your datapipelines so that you can get the most out of your Snowflake investment.
We encourage you to spend a few minutes browsing the apps and tools available in the phData Toolkit today to set yourself up for success in 2023. Explore phData Toolkit The post phData Toolkit June 2023 Update appeared first on phData. Be sure to follow: this series for more updates on the phData Toolkit tools and features.
This year’s DGIQ West will host tutorials, workshops, seminars, general conference sessions, and case studies for global data leaders. DGIQ is June 5-9, 2023, at the Catamaran Resort Hotel and Spa in San Diego, just steps away from the Mission Bay beach. You can learn more about the event and register here.
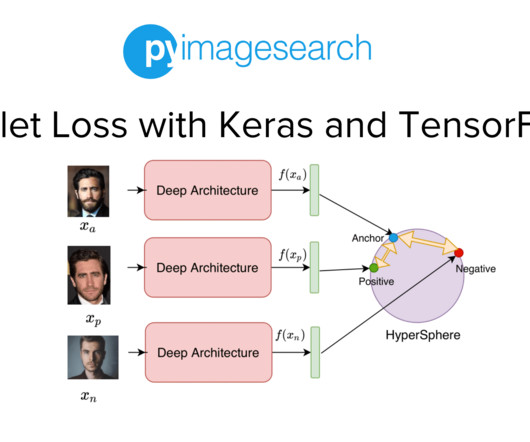
Project Structure Creating Our Configuration File Creating Our DataPipeline Preprocessing Faces: Detection and Cropping Summary Citation Information Building a Dataset for Triplet Loss with Keras and TensorFlow In today’s tutorial, we will take the first step toward building our real-time face recognition application. The dataset.py
Jump Right To The Downloads Section Training and Making Predictions with Siamese Networks and Triplet Loss In the second part of this series, we developed the modules required to build the datapipeline for our face recognition application. Figure 1: Overview of our Face Recognition Pipeline (source: image by the author).
Intermediate DataPipeline : Build datapipelines using DVC for automation and versioning of Open Source Machine Learning projects. For that, DagsHub added Audio capabilities, enabling you to see its spectrogram, wave, and even listen to it!
Data Engineering vs Machine Learning Pipelines This tutorial explores the differences between how machine learning and datapipelines work, as well as what is required for each. Here are 7 AI trends that we think will define the landscape over the next year.
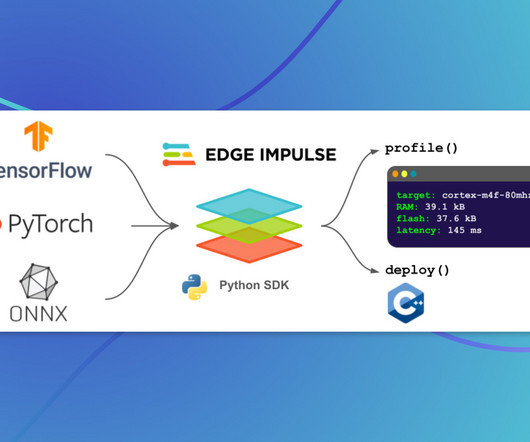
Last Updated on April 4, 2023 by Editorial Team Introducing a Python SDK that allows enterprises to effortlessly optimize their ML models for edge devices. We sketch out ideas in notebooks, build datapipelines and training scripts, and integrate with a vibrant ecosystem of Python tools.
In the previous tutorial of this series, we built the dataset and datapipeline for our Siamese Network based Face Recognition application. Specifically, we looked at an overview of triplet loss and discussed what kind of data samples are required to train our model with the triplet loss. What's next? Raha, and A. Thanki, eds.,
Orchestrating Data Assets instead of Tasks, with Dagster Sandy Ryza | Lead Engineer — Dagster Project | Elementl Asset-based orchestration works well with modern data stack tools like dbt, Meltano, Airbyte, and Fivetran, because those tools already think in terms of assets.
This is enforced with the `more` excerpt separator. --> AI caught everyone’s attention in 2023 with Large Language Models (LLMs) that can be instructed to perform general tasks, such as translation or coding, just by prompting. AI applications have always required careful monitoring of both model outputs and datapipelines to run reliably.
Effective data governance enhances quality and security throughout the data lifecycle. What is Data Engineering? Data Engineering is designing, constructing, and managing systems that enable data collection, storage, and analysis. The global data warehouse as a service market was valued at USD 9.06
Key skills and qualifications for machine learning engineers include: Strong programming skills: Proficiency in programming languages such as Python, R, or Java is essential for implementing machine learning algorithms and building datapipelines.
Going Beyond with Keras Core The Power of Keras Core: Expanding Your Deep Learning Horizons Show Me Some Code JAX Harnessing model.fit() Imports and Setup DataPipeline Build a Custom Model Build the Image Classification Model Train the Model Evaluation Summary References Citation Information What Is Keras Core? Enter Keras Core!
Congratulations to all the winners and kudos to all the participants for the entries — We appreciate your submissions and look forward to seeing many more entries in 2023. Introducing the winners of the ETH price prediction Data Challenge: Edition 2!
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content