This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data analytics has become a key driver of commercial success in recent years. The ability to turn large data sets into actionable insights can mean the difference between a successful campaign and missed opportunities. Flipping the paradigm: Using AI to enhance dataquality What if we could change the way we think about dataquality?
These tools provide data engineers with the necessary capabilities to efficiently extract, transform, and load (ETL) data, build datapipelines, and prepare data for analysis and consumption by other applications. Essential data engineering tools for 2023 Top 10 data engineering tools to watch out for in 2023 1.
As you delve into the landscape of MLOps in 2023, you will find a plethora of tools and platforms that have gained traction and are shaping the way models are developed, deployed, and monitored. Open-source tools have gained significant traction due to their flexibility, community support, and adaptability to various workflows.
So how should companies ensure they are able to make agile, and more confident, decisions in 2023 and beyond? The answer lies in fueling strategic business decisions with trusted data – leveraging high-integrity data that is consistent, accurate, and contextual.
A new event to ODSC West 2023 were the Lightning talks, which saw a small group of victims (speakers) describe slides picked at random. While we may be done with events for 2023, 2024 is looking to be packed full of conferences, meetups, and virtual events. What’s next?
DataQuality Now that you’ve learned more about your data and cleaned it up, it’s time to ensure the quality of your data is up to par. With these data exploration tools, you can determine if your data is accurate, consistent, and reliable. You can watch it on demand here.
The US nationwide fraud losses topped $10 billion in 2023, a 14% increase from 2022. It seems straightforward at first for batch data, but the engineering gets even more complicated when you need to go from batch data to incorporating real-time and streaming data sources, and from batch inference to real-time serving.
The Precisely team is excited to be part of Confluent’s Current 2023 conference, September 26 & 27. As a proud member of the Connect with Confluent program , we help organizations going through digital transformation and IT infrastructure modernization break down data silos and power their streaming datapipelines with trusted data.
Advanced analytics and AI/ML continue to be hot data trends in 2023. According to a recent IDC study, “executives openly articulate the need for their organizations to be more data-driven, to be ‘data companies,’ and to increase their enterprise intelligence.” Anomalous data can occur for a variety of different reasons.
Hidden Technical Debt in Machine Learning Systems More money, more problems — Rise of too many ML tools 2012 vs 2023 — Source: Matt Turck People often believe that money is the solution to a problem. Tools like Git and Jenkins are not suited for managing data. This is where a feature platform comes in handy. Spark, Flink, etc.)
Jacomo Corbo is a Partner and Chief Scientist, and Bryan Richardson is an Associate Partner and Senior Data Scientist, for QuantumBlack AI by McKinsey. They presented “Automating DataQuality Remediation With AI” at Snorkel AI’s The Future of Data-Centric AI Summit in 2022. That is still in flux and being worked out.
Jacomo Corbo is a Partner and Chief Scientist, and Bryan Richardson is an Associate Partner and Senior Data Scientist, for QuantumBlack AI by McKinsey. They presented “Automating DataQuality Remediation With AI” at Snorkel AI’s The Future of Data-Centric AI Summit in 2022. That is still in flux and being worked out.
In 2023 and beyond, we expect the open source trend to continue, with steady growth in the adoption of tools like Feilong, Tessla, Consolez, and Zowe. Data Integration Enterprises are betting big on analytics, and for good reason. The volume, velocity, and variety of data is growing exponentially.
This tool collects, compares, analyzes, and acts on data source metadata and metrics. This allows you to perform tasks such as ensuring dataquality against data sources (once or over time), compare data metrics and metadata across environments, and create/manage datapipelines for all your tables and views.
ODSC West 2023 is just a couple of months away, and we couldn’t be more excited to be able to share our Preliminary Schedule with you! Day 1: Monday, October 30th (Bootcamp, VIP, Platinum) Day 1 of ODSC West 2023 will feature our hands-on training sessions, workshops, and tutorials and will be open to Platinum, Bootcamp, and VIP pass holders.
Effective data governance enhances quality and security throughout the data lifecycle. What is Data Engineering? Data Engineering is designing, constructing, and managing systems that enable data collection, storage, and analysis. ETL is vital for ensuring dataquality and integrity.
The entire generative AI pipeline hinges on the datapipelines that empower it, making it imperative to take the correct precautions. 4 key components to ensure reliable data ingestion Dataquality and governance: Dataquality means ensuring the security of data sources, maintaining holistic data and providing clear metadata.
Data observability is a key element of data operations (DataOps). It enables a big-picture understanding of the health of your organization’s data through continuous AI/ML-enabled monitoring – detecting anomalies throughout the datapipeline and preventing data downtime.
This year’s DGIQ West will host tutorials, workshops, seminars, general conference sessions, and case studies for global data leaders. DGIQ is June 5-9, 2023, at the Catamaran Resort Hotel and Spa in San Diego, just steps away from the Mission Bay beach. You can learn more about the event and register here.
According to the 2023Data Integrity Trends and Insights Report , dataquality is the #1 barrier to achieving data integrity. And poor address quality is the top challenge preventing business leaders from effectively using location data to add context and multidimensional value to their decision-making processes.
A striking revelation from the 2023 Gartner IT Symposium Research Super Focus Group showed that only 4% of businesses considered their data AI-ready. This big wake-up call emphasizes the urgent need for organizations to enhance their data management practices to pave the way for trusted AI applications.
Key skills and qualifications for machine learning engineers include: Strong programming skills: Proficiency in programming languages such as Python, R, or Java is essential for implementing machine learning algorithms and building datapipelines.
It is the preferred operating system for data processing heavy operations for many reasons (more on this below). Around 70 percent of embedded systems use this OS and the RTOS market is expected to grow by 23 percent CAGR within the 2023–2030 forecast period, reaching a market value of over $2.5
Getting into Data Engineering Joe Reis | CEO | Ternary Data Perfect for those interested in getting into data engineering, this talk covers the key questions you should answer when embarking on a data engineering career. Joe Reis addresses the current economic climate in 2023 in particular.
High hopes Back in the spring of 2023—quite a long time in the artificial intelligence (AI) space—Goldman Sachs released a report estimating that the emergence of generative AI could boost global GDP by 7% annually (link resides outside IBM.com), amounting to more than an additional USD 7 trillion each year. .”
Context In early 2023, Zeta’s machine learning (ML) teams shifted from traditional vertical teams to a more dynamic horizontal structure, introducing the concept of pods comprising diverse skill sets. Additionally, Feast promotes feature reuse, so the time spent on data preparation is reduced greatly.
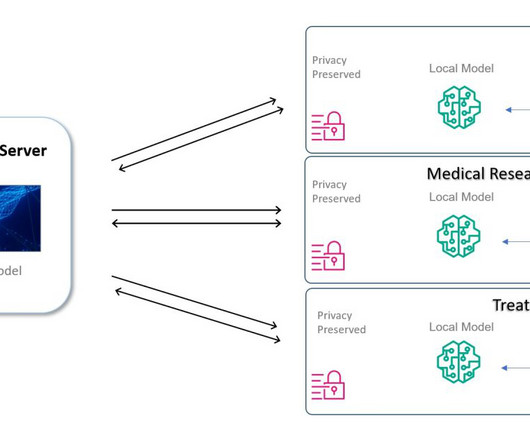
In Dr. Werner Vogels’s own words at AWS re:Invent 2023 , “every second that a person has a stroke counts.” Medical data restrictions You can use machine learning (ML) to assist doctors and researchers in diagnosis tasks, thereby speeding up the process. He has worked with multiple federal agencies to advance their data and AI goals.
A data fabric architecture elevates the value of enterprise data by providing the right data, at the right time, regardless of where it resides. To simplify the process of becoming data-driven with a data fabric, we are focusing on the four most common entry points we see with data fabric journeys.
In Nick Heudecker’s session on Driving Analytics Success with Data Engineering , we learned about the rise of the data engineer role – a jack-of-all-trades data maverick who resides either in the line of business or IT. To achieve organization-wide data literacy, a new information management platform must emerge.
Introduction Big Data continues transforming industries, making it a vital asset in 2025. The global Big Data Analytics market, valued at $307.51 billion in 2023, is projected to grow to $348.21 Key challenges include data storage, processing speed, scalability, and security and compliance. What is Schema-on-read?
Consider a datapipeline that detects its own failures, diagnoses the issue, and recommends the fix—all automatically. This is the potential of self-healing pipelines, and this blog explores how to implement them using dbt, Snowflake Cortex , and GitHub Actions. How well does it do with our dataquality issues?
We hope you’ve had a fantastic holiday season, filled up on delicious food, and are as excited as us to kick off the 2023 calendar year. These tools include things like profiling data sources, validating data migrations, generating datapipelines and dbt sources, and bulk translating SQL.
One of the more common practices when developing a datapipeline is rebuilding your data for testing changes. As one of the leaders in the industry, dbt provides several options on how to execute your pipelines to increase efficiency and specifically execute what you need.
A 2019 survey by McKinsey on global data transformation revealed that 30 percent of total time spent by enterprise IT teams was spent on non-value-added tasks related to poor dataquality and availability. It truly is an all-in-one data lake solution. Roxie then consolidates that data and presents the results.
Continuous monitoring of resources, data, and metrics. DataPipeline - Manages and processes various data sources. ML Pipeline - Focuses on training, validation and deployment. Application Pipeline - Manages requests and data/model validations. Collecting feedback for further tuning.
“You need to find a place to park your data. It needs to be optimized for the type of data and the format of the data you have,” he said. By optimizing every part of the datapipeline, he said, “You will, as a result, get your models to market faster.” Catch the sessions you missed!
“You need to find a place to park your data. It needs to be optimized for the type of data and the format of the data you have,” he said. By optimizing every part of the datapipeline, he said, “You will, as a result, get your models to market faster.” Catch the sessions you missed!
Amazon SageMaker Catalog serves as a central repository hub to store both technical and business catalog information of the data product. To establish trust between the data producers and data consumers, SageMaker Catalog also integrates the dataquality metrics and data lineage events to track and drive transparency in datapipelines.
Data Engineer Data engineers are the authors of the infrastructure that stores, processes, and manages the large volumes of data an organization has. The main aspect of their profession is the building and maintenance of datapipelines, which allow for data to move between sources. Well then, you’re in luck.
The Ultimate Modern Data Stack Migration Guide phData Marketing July 18, 2023 This guide was co-written by a team of data experts, including Dakota Kelley, Ahmad Aburia, Sam Hall, and Sunny Yan. Imagine a world where all of your data is organized, easily accessible, and routinely leveraged to drive impactful outcomes.
In transitional modeling, we’d add new atoms: Subject: Customer#1234 Predicate: hasEmailAddress Object: "john.new@example.com" Timestamp: 2023-07-24T10:00:00Z The old email address atoms are still there, giving us a complete history of how to contact John. Both persistent staging and data lakes involve storing large amounts of raw data.
Kishore will then double click into some of the opportunities we find here at Capital One, and Bayan will finish us off with a lean into one of our open-source solutions that really is an important contribution to our data-centric AI community. The reason is that most teams do not have access to a robust data ecosystem for ML development.
Kishore will then double click into some of the opportunities we find here at Capital One, and Bayan will finish us off with a lean into one of our open-source solutions that really is an important contribution to our data-centric AI community. The reason is that most teams do not have access to a robust data ecosystem for ML development.
Olalekan said that most of the random people they talked to initially wanted a platform to handle dataquality better, but after the survey, he found out that this was the fifth most crucial need. And when the platform automates the entire process, it’ll likely produce and deploy a bad-quality model.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content