This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Datapipelines play a critical role in the processing and management of data in modern organizations. A well-designed datapipeline can help organizations extract valuable insights from their data, automate tedious manual processes, and ensure the accuracy of data processing.
As you delve into the landscape of MLOps in 2023, you will find a plethora of tools and platforms that have gained traction and are shaping the way models are developed, deployed, and monitored. Open-source tools have gained significant traction due to their flexibility, community support, and adaptability to various workflows.
There are many well-known libraries and platforms for data analysis such as Pandas and Tableau, in addition to analytical databases like ClickHouse, MariaDB, Apache Druid, Apache Pinot, Google BigQuery, Amazon RedShift, etc. VisiData works with CSV files, Excel spreadsheets, SQL databases, and many other data sources.
As today’s world keeps progressing towards data-driven decisions, organizations must have quality data created from efficient and effective datapipelines. For customers in Snowflake, Snowpark is a powerful tool for building these effective and scalable datapipelines.
Last Updated on March 21, 2023 by Editorial Team Author(s): Data Science meets Cyber Security Originally published on Towards AI. Navigating the World of Data Engineering: A Beginner’s Guide. A GLIMPSE OF DATA ENGINEERING ❤ IMAGE SOURCE: BY AUTHOR Data or data? What are ETL and datapipelines?
This orchestration process encompasses interactions with external APIs, retrieval of contextual data from vector databases, and maintaining memory across multiple LLM calls. This makes it easy to connect your datapipeline to the data sources that you need. It is known for its extensibility and modularity.
Hidden Technical Debt in Machine Learning Systems More money, more problems — Rise of too many ML tools 2012 vs 2023 — Source: Matt Turck People often believe that money is the solution to a problem. A feature platform should automatically process the datapipelines to calculate that feature. Spark, Flink, etc.)
Image Source — Pixel Production Inc In the previous article, you were introduced to the intricacies of datapipelines, including the two major types of existing datapipelines. You might be curious how a simple tool like Apache Airflow can be powerful for managing complex datapipelines.
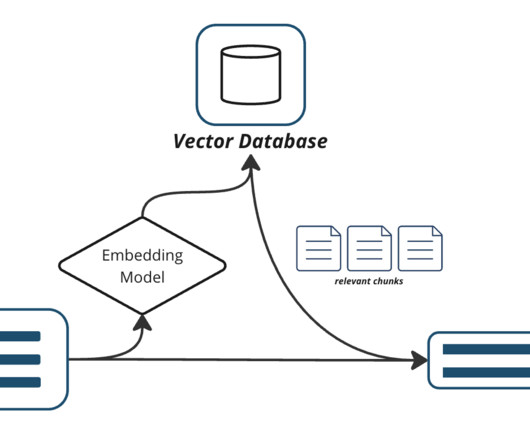
Y Combinator Photo) Seattle-area startups that just graduated from Y Combinator’s summer 2023 batch are tackling a wide range of problems — with plenty of help from artificial intelligence. Neum AI at its core is an enabler for generative AI applications by helping connect data into vector databases and making it accessible for RAG.
In 2023 and beyond, we expect the open source trend to continue, with steady growth in the adoption of tools like Feilong, Tessla, Consolez, and Zowe. In 2023, expect to see broader adoption of streaming datapipelines that bring mainframe data to the cloud, offering a powerful tool for “modernizing in place.”
billion in 2023 to USD 1,266.4 Defining Cloud Computing in Data Science Cloud computing provides on-demand access to computing resources such as servers, storage, databases, and software over the Internet. Key Features Tailored for Data Science These platforms offer specialised features to enhance productivity.
Operational Risks identify operational risks such as data loss or failures in the event of an unforeseen outage or disaster. Performance Optimization identify and fix bottlenecks in your datapipelines so that you can get the most out of your Snowflake investment.
Last Updated on March 1, 2023 by Editorial Team Author(s): Samuel Van Ackere Originally published on Towards AI. This article shows how to effortlessly insert sensor data in the form of an LDES into a TimescaleDB database. First, a data flow must be configured to ingest a Linked Data Event Stream into PostgreSQL.
Please spend a few minutes browsing the apps and tools available in the phData Toolkit today to set yourself up for success in 2023. Explore the phData Toolkit The post phData Toolkit December 2023 Update appeared first on phData. The tool now runs on 8 threads as opposed to the original single thread!
This allows you to perform tasks such as ensuring data quality against data sources (once or over time), compare data metrics and metadata across environments, and create/manage datapipelines for all your tables and views. Fixed an issue showing invalid timestamp/precision issues when scanning an Impala database.
ODSC West 2023 is just a couple of months away, and we couldn’t be more excited to be able to share our Preliminary Schedule with you! Day 1: Monday, October 30th (Bootcamp, VIP, Platinum) Day 1 of ODSC West 2023 will feature our hands-on training sessions, workshops, and tutorials and will be open to Platinum, Bootcamp, and VIP pass holders.
For the Data Source Tool, we’ve addressed the following: Fixed an issue where view filters wouldn’t be disabled when using enabled = false. Fixed an issue when filtering tables in a database where only the first table listed would be scanned.
This is commonly handled in code that pulls data from databases, but you can also do this within the SQL query itself. We encourage you to spend a few minutes browsing the apps and tools available in the phData Toolkit today to set yourself up for success in 2023.
Translate CATALOG_COLLATION in CREATE DATABASE Add BOM-aware file reading so that files with a BOM are read with the encoding specified. We encourage you to spend a few minutes browsing the apps and tools available in the phData Toolkit today to set yourself up for success in 2023.
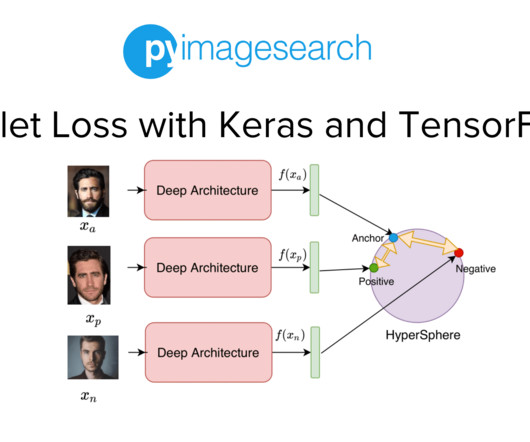
Project Structure Creating Our Configuration File Creating Our DataPipeline Preprocessing Faces: Detection and Cropping Summary Citation Information Building a Dataset for Triplet Loss with Keras and TensorFlow In today’s tutorial, we will take the first step toward building our real-time face recognition application. The dataset.py
Effective data governance enhances quality and security throughout the data lifecycle. What is Data Engineering? Data Engineering is designing, constructing, and managing systems that enable data collection, storage, and analysis. This section explores essential aspects of Data Engineering.
On December 6 th -8 th 2023, the non-profit organization, Tech to the Rescue , in collaboration with AWS, organized the world’s largest Air Quality Hackathon – aimed at tackling one of the world’s most pressing health and environmental challenges, air pollution. This allows for data to be aggregated for further manufacturer-agnostic analysis.
A complete overview revealing a diverse range of strengths and weaknesses for each data versioning tool. It does not support the ‘dvc repro’ command to reproduce its datapipeline. DVC Released in 2017, Data Version Control ( DVC for short) is an open-source tool created by iterative.
In the previous tutorial of this series, we built the dataset and datapipeline for our Siamese Network based Face Recognition application. Specifically, we looked at an overview of triplet loss and discussed what kind of data samples are required to train our model with the triplet loss. What's next? Raha, and A. Thanki, eds.,
More on this topic later; but for now, keep in mind that the simplest method is to create a naming convention for database objects that allows you to identify the owner and associated budget. The extended period will allow you to perform Time Travel activities, such as undropping tables or comparing new data against historical values.
This is enforced with the `more` excerpt separator. --> AI caught everyone’s attention in 2023 with Large Language Models (LLMs) that can be instructed to perform general tasks, such as translation or coding, just by prompting. AI applications have always required careful monitoring of both model outputs and datapipelines to run reliably.
Modin empowers practitioners to use pandas on data at scale, without requiring them to change a single line of code. Modin leverages our cutting-edge academic research on dataframes — the abstraction underlying pandas to bring the best of databases and distributed systems to dataframes. Run operations in pandas - all in Snowflake!
Context In early 2023, Zeta’s machine learning (ML) teams shifted from traditional vertical teams to a more dynamic horizontal structure, introducing the concept of pods comprising diverse skill sets. Additionally, Feast promotes feature reuse, so the time spent on data preparation is reduced greatly.
This article was co-written by Lawrence Liu & Safwan Islam While the title ‘ Machine Learning Engineer ’ may sound more prestigious than ‘Data Engineer’ to some, the reality is that these roles share a significant overlap. Generative AI has unlocked the value of unstructured text-based data.
What is Apache Kafka, and How is it Used in Building Real-time DataPipelines? It is capable of handling high-volume and high-velocity data. Apache Kafka is an open-source event distribution platform. It is highly scalable, has high availability, and has low latency. Example: openssl rsa -in C:tmpnew_rsa_key_v1.p8
Managing datapipelines efficiently is paramount for any organization. The Snowflake Data Cloud has introduced a groundbreaking feature that promises to simplify and supercharge this process: Snowflake Dynamic Tables. What are Snowflake Dynamic Tables?
Data observability is a key element of data operations (DataOps). It enables a big-picture understanding of the health of your organization’s data through continuous AI/ML-enabled monitoring – detecting anomalies throughout the datapipeline and preventing data downtime.
In a survey conducted in 2023 , over three-quarters of the executives surveyed believed that artificial intelligence would disrupt their business strategy. In theory, if two vector embeddings are close to one another in vector space, then the underlying data the vectors represent are semantically similar.
Data Modeling, dbt has gradually emerged as a powerful tool that largely simplifies the process of building and handling datapipelines. dbt is an open-source command-line tool that allows data engineers to transform, test, and document the data into one single hub which follows the best practices of software engineering.
You can watch the full talk this blog post is based on, which took place at ODSC West 2023, here. Feedback - Collect production data, metadata, and metrics to tune the model and application further, and to enable governance and explainability. The importance of datapipelines lies in the fact that datapipelines improve quality.
However, there are some key differences that we need to consider: Size and complexity of the data In machine learning, we are often working with much larger data. Basically, every machine learning project needs data. First of all, machine learning engineers and data scientists often use data from different data vendors.
To configure Salesforce and Snowflake using the Sync Out connector, follow these steps: Step 1: Create Snowflake Objects To use Sync Out with Snowflake, you need to configure the following Snowflake objects appropriately in your Snowflake account: Database and schema that will be used for the Salesforce data.
We hope you’ve had a fantastic holiday season, filled up on delicious food, and are as excited as us to kick off the 2023 calendar year. Traditionally, database administrators (DBAs) would run scripts that were manually generated through each environment to make changes to the database. But what does this actually mean?
In this blog, we’ll explore how Matillion Jobs can simplify the data transformation process by allowing users to visualize the data flow of a job from start to finish. Step 1 - Source Inputs For our example, our data will come from two table inputs for “cities” and “orders”. Database : Source Database of the table.
In this blog, we’ll explore how Matillion Jobs can simplify the data transformation process by allowing users to visualize the data flow of a job from start to finish. Step 1 – Source Inputs For our example, our data will come from two table inputs for “cities” and “orders”. Database: Source Database of the table.
A feature store is a data platform that supports the creation and use of feature data throughout the lifecycle of an ML model, from creating features that can be reused across many models to model training to model inference (making predictions). It can also transform incoming data on the fly.
According to the 2023Data Integrity Trends and Insights Report , data quality is the #1 barrier to achieving data integrity. And poor address quality is the top challenge preventing business leaders from effectively using location data to add context and multidimensional value to their decision-making processes.
We launched Predictoor and its Data Farming incentives in September & November 2023, respectively. Flows We released pdr-backend when we launched Predictoor in September 2023, and have been continually improving it since then: fixing bugs, reducing onboarding friction, and adding more capabilities (eg simulation flow).
Top Use Cases of Snowpark With Snowpark, bringing business logic to data in the cloud couldn’t be easier. Transitioning work to Snowpark allows for faster ML deployment, easier scaling, and robust datapipeline development. ML Applications For data scientists, models can be developed in Python with common machine learning tools.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content