This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
These tools provide data engineers with the necessary capabilities to efficiently extract, transform, and load (ETL) data, build datapipelines, and prepare data for analysis and consumption by other applications. Essential data engineering tools for 2023 Top 10 data engineering tools to watch out for in 2023 1.
As you delve into the landscape of MLOps in 2023, you will find a plethora of tools and platforms that have gained traction and are shaping the way models are developed, deployed, and monitored. For example, if your team is proficient in Python and R, you may want an MLOps tool that supports open data formats like Parquet, JSON, CSV, etc.,
NLP Skills for 2023 These skills are platform agnostic, meaning that employers are looking for specific skillsets, expertise, and workflows. The chart below shows 20 in-demand skills that encompass both NLP fundamentals and broader data science expertise. Knowing some SQL is also essential.
As today’s world keeps progressing towards data-driven decisions, organizations must have quality data created from efficient and effective datapipelines. For customers in Snowflake, Snowpark is a powerful tool for building these effective and scalable datapipelines.
These tools will help make your initial data exploration process easy. ydata-profiling GitHub | Website The primary goal of ydata-profiling is to provide a one-line Exploratory Data Analysis (EDA) experience in a consistent and fast solution. Output is a fully self-contained HTML application. You can watch it on demand here.
The role of a data scientist is in demand and 2023 will be no exception. To get a better grip on those changes we reviewed over 25,000 data scientist job descriptions from that past year to find out what employers are looking for in 2023. While knowing Python, R, and SQL are expected, you’ll need to go beyond that.
Provide connectors for data sources: Orchestration frameworks typically provide connectors for a variety of data sources, such as databases, cloud storage, and APIs. This makes it easy to connect your datapipeline to the data sources that you need. It is known for its ease of use and flexibility.
A new event to ODSC West 2023 were the Lightning talks, which saw a small group of victims (speakers) describe slides picked at random. While we may be done with events for 2023, 2024 is looking to be packed full of conferences, meetups, and virtual events. What’s next?
Automate and streamline our ML inference pipeline with SageMaker and Airflow Building an inference datapipeline on large datasets is a challenge many companies face. Airflow setup Apache Airflow is an open-source tool for orchestrating workflows and data processing pipelines.
Home Table of Contents Adversarial Learning with Keras and TensorFlow (Part 2): Implementing the Neural Structured Learning (NSL) Framework and Building a DataPipeline Adversarial Learning with NSL CIFAR-10 Dataset Configuring Your Development Environment Need Help Configuring Your Development Environment?
Image Source — Pixel Production Inc In the previous article, you were introduced to the intricacies of datapipelines, including the two major types of existing datapipelines. You might be curious how a simple tool like Apache Airflow can be powerful for managing complex datapipelines.
On December 6 th -8 th 2023, the non-profit organization, Tech to the Rescue , in collaboration with AWS, organized the world’s largest Air Quality Hackathon – aimed at tackling one of the world’s most pressing health and environmental challenges, air pollution. Some input data uses a pair of value type and value for a measurement.
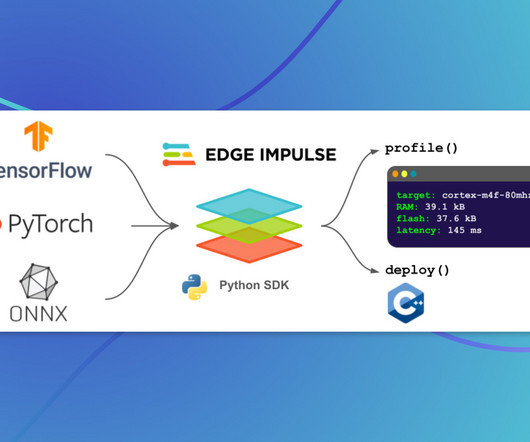
Last Updated on April 4, 2023 by Editorial Team Introducing a Python SDK that allows enterprises to effortlessly optimize their ML models for edge devices. Coupled with BYOM, the new Python SDK streamlines workflows even further, letting ML teams leverage Edge Impulse directly from their own development environments.
Last Updated on March 21, 2023 by Editorial Team Author(s): Data Science meets Cyber Security Originally published on Towards AI. Navigating the World of Data Engineering: A Beginner’s Guide. A GLIMPSE OF DATA ENGINEERING ❤ IMAGE SOURCE: BY AUTHOR Data or data? What are ETL and datapipelines?
ODSC West 2023 is just a couple of months away, and we couldn’t be more excited to be able to share our Preliminary Schedule with you! Day 1: Monday, October 30th (Bootcamp, VIP, Platinum) Day 1 of ODSC West 2023 will feature our hands-on training sessions, workshops, and tutorials and will be open to Platinum, Bootcamp, and VIP pass holders.
Python Timestamp: Converting and Formatting Essentials for Beginners In this article, we will explore the different ways to work with timestamps in Python, including generating, converting, and comparing timestamps. Here are 7 AI trends that we think will define the landscape over the next year.
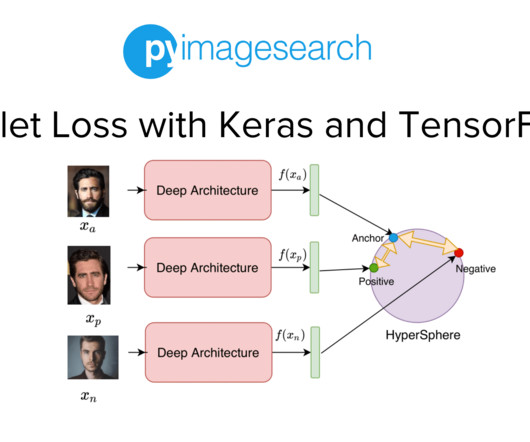
Project Structure Creating Our Configuration File Creating Our DataPipeline Preprocessing Faces: Detection and Cropping Summary Citation Information Building a Dataset for Triplet Loss with Keras and TensorFlow In today’s tutorial, we will take the first step toward building our real-time face recognition application. The dataset.py
Jump Right To The Downloads Section Training and Making Predictions with Siamese Networks and Triplet Loss In the second part of this series, we developed the modules required to build the datapipeline for our face recognition application. Figure 1: Overview of our Face Recognition Pipeline (source: image by the author).
Key skills and qualifications for machine learning engineers include: Strong programming skills: Proficiency in programming languages such as Python, R, or Java is essential for implementing machine learning algorithms and building datapipelines.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
This is enforced with the `more` excerpt separator. --> AI caught everyone’s attention in 2023 with Large Language Models (LLMs) that can be instructed to perform general tasks, such as translation or coding, just by prompting. Python code that calls an LLM), or should it be driven by an AI model (e.g. Operation: LLMOps and DataOps.
In the previous tutorial of this series, we built the dataset and datapipeline for our Siamese Network based Face Recognition application. Specifically, we looked at an overview of triplet loss and discussed what kind of data samples are required to train our model with the triplet loss. What's next? Raha, and A. Thanki, eds.,
Going Beyond with Keras Core The Power of Keras Core: Expanding Your Deep Learning Horizons Show Me Some Code JAX Harnessing model.fit() Imports and Setup DataPipeline Build a Custom Model Build the Image Classification Model Train the Model Evaluation Summary References Citation Information What Is Keras Core? Enter Keras Core!
Effective data governance enhances quality and security throughout the data lifecycle. What is Data Engineering? Data Engineering is designing, constructing, and managing systems that enable data collection, storage, and analysis. The global data warehouse as a service market was valued at USD 9.06
Snowpark , an innovative technology from the Snowflake Data Cloud , promises to meet this demand by allowing data scientists to develop complex data transformation logic using familiar programming languages such as Java, Scala, and Python. Snowpark enables ML teams to deploy with native code running where their data is.
Reference table for which technologies to use for your FTI pipelines for each ML system. Related article How to Build ETL DataPipelines for ML See also MLOps and FTI pipelines testing Once you have built an ML system, you have to operate, maintain, and update it. All of them are written in Python.
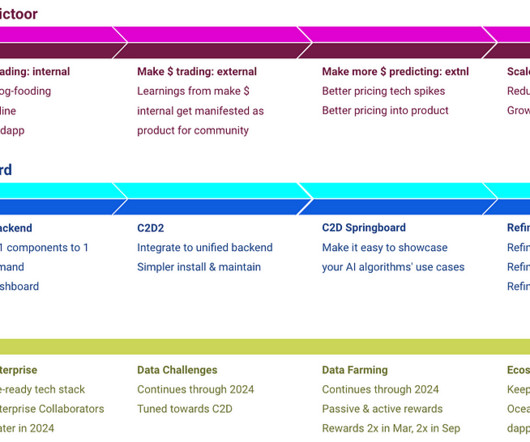
We launched Predictoor and its Data Farming incentives in September & November 2023, respectively. The pdr-backend GitHub repo has the Python code for all bots: Predictoor bots, Trader bots, and support bots (submitting true values, buying on behalf of DF, etc). on November 20, 2023; with subsequent v0.1.x x releases.
The effect is that you get to use your favorite pandas API, but your datapipelines run on one of the most battle-tested and heavily-optimized data infrastructures today — databases. You can start running your Pythondata workflows in your data warehouse today by signing up here ! Doris received her Ph.D.
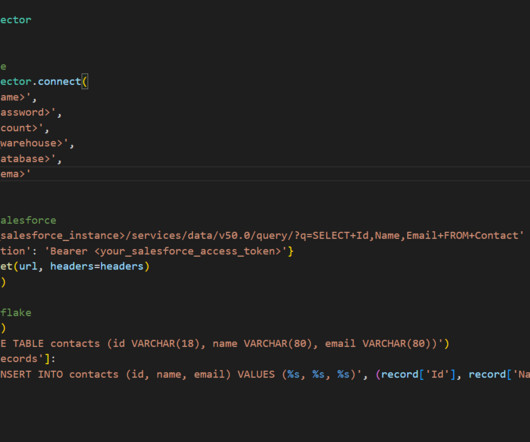
Here’s an example of code that can be used to extract Salesforce data and load it into Snowflake using Python: 2. Third-Party Tools Third-party tools like Matillion or Fivetran can help streamline the process of ingesting Salesforce data into Snowflake. Need help ingesting data into Snowflake? phData can help!
The output files contain not only the processed text, but also observability data and the parameters used for inference. The following is an example in Python: import boto3 import json # Create an S3 client s3 = boto3.client('s3') decode('utf-8') # Initialize a list output_data = [] # Process the JSON data.
You can watch the full talk this blog post is based on, which took place at ODSC West 2023, here. Feedback - Collect production data, metadata, and metrics to tune the model and application further, and to enable governance and explainability. The importance of datapipelines lies in the fact that datapipelines improve quality.
Context In early 2023, Zeta’s machine learning (ML) teams shifted from traditional vertical teams to a more dynamic horizontal structure, introducing the concept of pods comprising diverse skill sets. Airflow for workflow orchestration Airflow schedules and manages complex workflows, defining tasks and dependencies in Python code.
Snowflake Connectors For accessing data, you’ll find a slew of Snowflake connectors on the Snowflake website. For example: ODBC JDBC Python Snowflake Connector And, generally, things will be okay. DataPipelines “Datapipeline” means moving data in a consistent, secure, and reliable way at some frequency that meets your requirements.
Jason Goldfarb, senior data scientist at State Farm , gave a presentation entitled “Reusable Data Cleaning Pipelines in Python” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. It has always amazed me how much time the data cleaning portion of my job takes to complete.
Jason Goldfarb, senior data scientist at State Farm , gave a presentation entitled “Reusable Data Cleaning Pipelines in Python” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. It has always amazed me how much time the data cleaning portion of my job takes to complete.
release has many other improvements: in trader bots, datapipeline, UX, and core bug fixes. Datapipeline: better structure, with DuckDB at the core. UX: There is now proper Python-style logging. release has many other improvements: in trader bots, datapipeline, UX, and core bug fixes.
Introduction Ocean Protocol was founded to level the playing field for AI and data .In In 2023, we tested hypotheses towards growing traction. From that, the three brightest spots are Ocean Predictoor, Ocean Compute-to-Data (C2D), and Ocean Enterprise. Continually improve datapipeline and analytics dapp.
Though scripted languages such as R and Python are at the top of the list of required skills for a data analyst, Excel is still one of the most important tools to be used. Data Engineer Data engineers are the authors of the infrastructure that stores, processes, and manages the large volumes of data an organization has.
Specifically, we will develop our datapipeline, implement the loss functions discussed in Part 1 and write our own code to train the CycleGAN model end-to-end using Keras and TensorFlow. Finally, we combine and consolidate our entire training data (i.e., Let us open the train.py file and get started. We open the inference.py
Introduction Big Data continues transforming industries, making it a vital asset in 2025. The global Big Data Analytics market, valued at $307.51 billion in 2023, is projected to grow to $348.21 Explain the CAP theorem and its relevance in Big Data systems. billion in 2024 and reach a staggering $924.39
In terms of resulting speedups, the approximate order is programming hardware, then programming against PBA APIs, then programming in an unmanaged language such as C++, then a managed language such as Python. In November 2023, AWS announced the next generation Trainium2 chip. GPU PBAs, 4% other PBAs, 4% FPGA, and 0.5%
Consider a datapipeline that detects its own failures, diagnoses the issue, and recommends the fix—all automatically. This is the potential of self-healing pipelines, and this blog explores how to implement them using dbt, Snowflake Cortex , and GitHub Actions. python/requirements.txt - name: Trigger dbt job run: | python -u./python/run_monitor_and_self_heal.py
Furthermore, we’ve developed data encryption and governance solutions for HPCC Systems to help secure data, ensure it is only accessed by appropriate personnel, and to create audit trails to ensure data security SLAs and regulations are met. It truly is an all-in-one data lake solution. Tell me more about ECL.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content