This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Now all you need is some guidance on generative AI and machine learning (ML) sessions to attend at this twelfth edition of re:Invent. In addition to several exciting announcements during keynotes, most of the sessions in our track will feature generative AI in one form or another, so we can truly call our track “Generative AI and ML.”
Some projects may necessitate a comprehensive LLMOps approach, spanning tasks from datapreparation to pipeline production. Exploratory Data Analysis (EDA) Data collection: The first step in LLMOps is to collect the data that will be used to train the LLM.
As you delve into the landscape of MLOps in 2023, you will find a plethora of tools and platforms that have gained traction and are shaping the way models are developed, deployed, and monitored. For example, if your team is proficient in Python and R, you may want an MLOps tool that supports open data formats like Parquet, JSON, CSV, etc.,
Datapreparation is a critical step in any data-driven project, and having the right tools can greatly enhance operational efficiency. Amazon SageMaker Data Wrangler reduces the time it takes to aggregate and prepare tabular and image data for machine learning (ML) from weeks to minutes.
Last Updated on June 27, 2023 by Editorial Team Source: Unsplash This piece dives into the top machine learning developer tools being used by developers — start building! Scikit Learn Scikit Learn is a comprehensive machine learning tool designed for data mining and large-scale unstructured data analysis.
Last Updated on August 26, 2023 by Editorial Team Author(s): Jeff Holmes MS MSCS Originally published on Towards AI. Many Discord users are high school and undergraduate college students with no AI/ML or software engineering experience. Describe the problem, including the category of ML problem. Describe the problem.
Inspired by user feedback, the 2023.R3 Large teams collaborating on Snorkel Flow will also enjoy our new comment-based filtering making it easier to communicate with teammates and more easily address outliers to ensure the highest quality data possible. Revamped Snorkel Flow SDK Also included in the 2023.R3 Book a demo today.
Last Updated on August 17, 2023 by Editorial Team Author(s): Jeff Holmes MS MSCS Originally published on Towards AI. Pietro Jeng on Unsplash MLOps is a set of methods and techniques to deploy and maintain machine learning (ML) models in production reliably and efficiently. Projects: a standard format for packaging reusable ML code.
Inspired by user feedback, the 2023.R3 Large teams collaborating on Snorkel Flow will also enjoy our new comment-based filtering making it easier to communicate with teammates and more easily address outliers to ensure the highest quality data possible. Revamped Snorkel Flow SDK Also included in the 2023.R3
Hands-on Data-Centric AI: DataPreparation Tuning — Why and How? Going into developing machine learning models with a hands-on, data-centric AI approach has its benefits and requires a few extra steps to achieve. Final ODSC East 2023 Schedule Released! Learn more here.
Last Updated on August 25, 2023 by Editorial Team Author(s): Jeff Holmes MS MSCS Originally published on Towards AI. I also have a GitHub repo with lots of notes and links to AI/ML articles on various topics LearnAI. Trying to code ML algorithms from scratch. Trying to learn AI from research papers.
The ZMP analyzes billions of structured and unstructured data points to predict consumer intent by using sophisticated artificial intelligence (AI) to personalize experiences at scale. Hosted on Amazon ECS with tasks run on Fargate, this platform streamlines the end-to-end ML workflow, from data ingestion to model deployment.
MLOps is a key discipline that often oversees the path to productionizing machine learning (ML) models. MLOps tooling helps you repeatably and reliably build and simplify these processes into a workflow that is tailored for ML. It’s natural to focus on a single model that you want to train and deploy.
Inspired by user feedback, the 2023.R3 Large teams collaborating on Snorkel Flow will also enjoy our new comment-based filtering making it easier to communicate with teammates and more easily address outliers to ensure the highest quality data possible. Revamped Snorkel Flow SDK Also included in the 2023.R3 Book a demo today.
ML operationalization summary As defined in the post MLOps foundation roadmap for enterprises with Amazon SageMaker , ML and operations (MLOps) is the combination of people, processes, and technology to productionize machine learning (ML) solutions efficiently.
Last Updated on May 2, 2023 by Editorial Team Author(s): Puneet Jindal Originally published on Towards AI. 80% of the time goes in datapreparation ……blah blah…. Nothing in the world motivates a team of ML engineers and scientists to spend the required amount of time in data annotation and labeling. blah blah…….
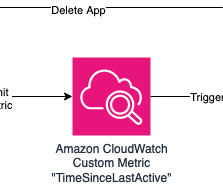
Amazon SageMaker Canvas is a rich, no-code Machine Learning (ML) and Generative AI workspace that has allowed customers all over the world to more easily adopt ML technologies to solve old and new challenges thanks to its visual, no-code interface. For example, using the AWS SDK for Python ( boto3 ): import boto3, datetime cw = boto3.client('cloudwatch')
Last Updated on August 17, 2023 by Editorial Team Author(s): Jeff Holmes MS MSCS Originally published on Towards AI. In fact, AI/ML graduate textbooks do not provide a clear and consistent description of the AI software engineering process. When the agent is a computer, the learning process is called machine learning (ML) [6, p.
Note : Now write some articles or blogs on the things you have learned because this thing will help you to develop soft skills as well if you want to publish some research paper on AI/ML so this writing habit will help you there for sure. It provides end-to-end pipeline components for building scalable and reliable ML production systems.
In the following sections, we provide a detailed, step-by-step guide on implementing these new capabilities, covering everything from datapreparation to job submission and output analysis. This use case serves to illustrate the broader potential of the feature for handling diverse data processing tasks.
On December 6 th -8 th 2023, the non-profit organization, Tech to the Rescue , in collaboration with AWS, organized the world’s largest Air Quality Hackathon – aimed at tackling one of the world’s most pressing health and environmental challenges, air pollution. She holds 30+ patents and has co-authored 100+ journal/conference papers.
Automate and streamline our ML inference pipeline with SageMaker and Airflow Building an inference data pipeline on large datasets is a challenge many companies face. SageMaker Batch Job Allows you to run batch inference on large datasets and generate predictions in a batch mode using machine learning (ML) models hosted in SageMaker.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
PyCaret allows data professionals to build and deploy machine learning models easily and efficiently. What makes this the low-code library of choice is the range of functionaries that include datapreparation, model training, and evaluation. This means everything from datapreparation to model deployment.
Last Updated on August 17, 2023 by Editorial Team Author(s): Jeff Holmes MS MSCS Originally published on Towards AI. The MLOps Process We can see some of the differences with MLOps which is a set of methods and techniques to deploy and maintain machine learning (ML) models in production reliably and efficiently.
Machine learning practitioners are often working with data at the beginning and during the full stack of things, so they see a lot of workflow/pipeline development, data wrangling, and datapreparation. What percentage of machine learning models developed in your organization get deployed to a production environment?
To simplify infrastructure setup and accelerate distributed training, AWS introduced Amazon SageMaker HyperPod in late 2023. Fine tuning Now that your SageMaker HyperPod cluster is deployed, you can start preparing to execute your fine tuning job. After a few minutes, its status should change from Creating to InService.
Generative AI , AI, and machine learning (ML) are playing a vital role for capital markets firms to speed up revenue generation, deliver new products, mitigate risk, and innovate on behalf of their customers. About SageMaker JumpStart Amazon SageMaker JumpStart is an ML hub that can help you accelerate your ML journey.
Drawing from their extensive experience in the field, the authors share their strategies, methodologies, tools and best practices for designing and building a continuous, automated and scalable ML pipeline that delivers business value. The book is poised to address these exact challenges.
At AWS re:Invent 2023, we announced the general availability of Knowledge Bases for Amazon Bedrock. With Knowledge Bases for Amazon Bedrock, you can securely connect foundation models (FMs) in Amazon Bedrock to your company data for fully managed Retrieval Augmented Generation (RAG).
Last Updated on July 19, 2023 by Editorial Team Author(s): Yashashri Shiral Originally published on Towards AI. DataPreparation — Collect data, Understand features 2. Visualize Data — Rolling mean/ Standard Deviation— helps in understanding short-term trends in data and outliers.
Redefining cloud database innovation: IBM and AWS In late 2023, IBM and AWS jointly announced the general availability of Amazon relational database service (RDS) for Db2. This service streamlines data management for AI workloads across hybrid cloud environments and facilitates the scaling of Db2 databases on AWS with minimal effort.
These activities cover disparate fields such as basic data processing, analytics, and machine learning (ML). ML is often associated with PBAs, so we start this post with an illustrative figure. The ML paradigm is learning followed by inference. The union of advances in hardware and ML has led us to the current day.
After some impressive advances over the past decade, largely thanks to the techniques of Machine Learning (ML) and Deep Learning , the technology seems to have taken a sudden leap forward. It helps facilitate the entire data and AI lifecycle, from datapreparation to model development, deployment and monitoring.
Understanding Machine Learning algorithms and effective data handling are also critical for success in the field. Introduction Machine Learning ( ML ) is revolutionising industries, from healthcare and finance to retail and manufacturing. Fundamental Programming Skills Strong programming skills are essential for success in ML.
They are characterized by their enormous size, complexity, and the vast amount of data they process. These elements need to be taken into consideration when managing, streamlining and deploying LLMs in ML pipelines, hence the specialized discipline of LLMOps. Data Pipeline - Manages and processes various data sources.
Semi-structured input Starting in 2023, Amazon Comprehend now supports training models using semi-structured documents. The training data for semi-structure input is comprised of a set of labeled documents, which can be pre-identified documents from a document repository that you already have access to.
is our enterprise-ready next-generation studio for AI builders, bringing together traditional machine learning (ML) and new generative AI capabilities powered by foundation models. Automated development: Automates datapreparation, model development, feature engineering and hyperparameter optimization using AutoAI. .”
Today’s data management and analytics products have infused artificial intelligence (AI) and machine learning (ML) algorithms into their core capabilities. These modern tools will auto-profile the data, detect joins and overlaps, and offer recommendations. 2) Line of business is taking a more active role in data projects.
A cordial greeting to all data science enthusiasts! I consider myself fortunate to have the opportunity to speak at the upcoming ODSC APAC conference slated for the 22nd of August 2023. The inferSchema parameter is set to True to infer the data types of the columns, and header is set to True to use the first row as headers.
Last Updated on July 7, 2023 by Editorial Team Author(s): Anirudh Mehta Originally published on Towards AI. This article is part of the AWS SageMaker series for exploration of ’31 Questions that Shape Fortune 500 ML Strategy’. This section will focus on running transformations on our transaction data.
Training/Validation datapreparation: Preparing training and validation data is critical to ensure the quality of the trained model and we did not have a representative validation set for any given tag. This will help subject matter experts realize value without the bottleneck of our ML teams’ bandwidth.
Training/Validation datapreparation: Preparing training and validation data is critical to ensure the quality of the trained model and we did not have a representative validation set for any given tag. This will help subject matter experts realize value without the bottleneck of our ML teams’ bandwidth.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content