This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction When it comes to datapreparation using Python, the term which comes to our mind is Pandas. Well, a library for prepping up the data for further analysis. No, not the one whom you see happily munching away on bamboo and lazily somersaulting.
While a formal education is a good starting point, there are certain skills essential for any data scientist to possess to be successful in this field. However, certain technical skills are considered essential for a data scientist to possess. However, certain technical skills are considered essential for a data scientist to possess.
Datapreparation is a critical step in any data-driven project, and having the right tools can greatly enhance operational efficiency. Amazon SageMaker Data Wrangler reduces the time it takes to aggregate and prepare tabular and image data for machine learning (ML) from weeks to minutes.
As you delve into the landscape of MLOps in 2023, you will find a plethora of tools and platforms that have gained traction and are shaping the way models are developed, deployed, and monitored. For example, if your team is proficient in Python and R, you may want an MLOps tool that supports open data formats like Parquet, JSON, CSV, etc.,
Last Updated on June 27, 2023 by Editorial Team Source: Unsplash This piece dives into the top machine learning developer tools being used by developers — start building! PyTorch PyTorch, a Python-based machine learning library, stands out among its peers in the machine learning tools ecosystem.
On December 6 th -8 th 2023, the non-profit organization, Tech to the Rescue , in collaboration with AWS, organized the world’s largest Air Quality Hackathon – aimed at tackling one of the world’s most pressing health and environmental challenges, air pollution. Some input data uses a pair of value type and value for a measurement.
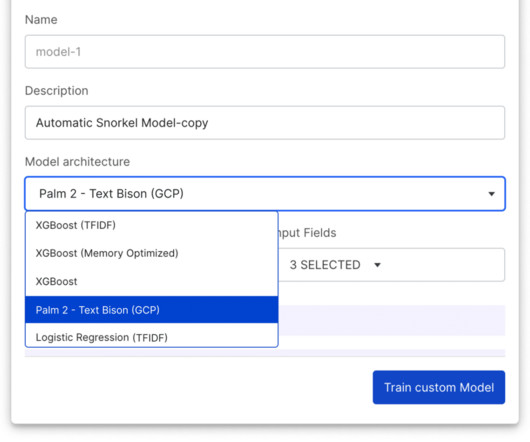
Inspired by user feedback, the 2023.R3 When Vertex Model Monitoring detects data drift, input feature values are submitted to Snorkel Flow, enabling ML teams to adapt labeling functions quickly, retrain the model, and then deploy the new model with Vertex AI. Revamped Snorkel Flow SDK Also included in the 2023.R3
Inspired by user feedback, the 2023.R3 When Vertex Model Monitoring detects data drift, input feature values are submitted to Snorkel Flow, enabling ML teams to adapt labeling functions quickly, retrain the model, and then deploy the new model with Vertex AI. Revamped Snorkel Flow SDK Also included in the 2023.R3
To simplify infrastructure setup and accelerate distributed training, AWS introduced Amazon SageMaker HyperPod in late 2023. Fine tuning Now that your SageMaker HyperPod cluster is deployed, you can start preparing to execute your fine tuning job. The following is the bash script for the Python environment setup.
One is a scripting language such as Python, and the other is a Query language like SQL (Structured Query Language) for SQL Databases. Python is a High-level, Procedural, and object-oriented language; it is also a vast language itself, and covering the whole of Python is one the worst mistakes we can make in the data science journey.
Machine learning practitioners are often working with data at the beginning and during the full stack of things, so they see a lot of workflow/pipeline development, data wrangling, and datapreparation.
It simplifies the development and maintenance of ML models by providing a centralized platform to orchestrate tasks such as datapreparation, model training, tuning and validation. You can run the following command from your notebook or terminal to install or upgrade the SageMaker Python SDK version to 2.162.0
Inspired by user feedback, the 2023.R3 When Vertex Model Monitoring detects data drift, input feature values are submitted to Snorkel Flow, enabling ML teams to adapt labeling functions quickly, retrain the model, and then deploy the new model with Vertex AI. Revamped Snorkel Flow SDK Also included in the 2023.R3
Low-Code PyCaret: Let’s start off with a low-code open-source machine learning library in Python. PyCaret allows data professionals to build and deploy machine learning models easily and efficiently. This means everything from datapreparation to model deployment.
In the following sections, we provide a detailed, step-by-step guide on implementing these new capabilities, covering everything from datapreparation to job submission and output analysis. This use case serves to illustrate the broader potential of the feature for handling diverse data processing tasks.
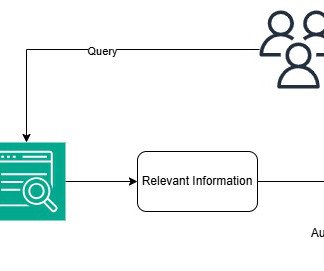
At AWS re:Invent 2023, we announced the general availability of Knowledge Bases for Amazon Bedrock. With Knowledge Bases for Amazon Bedrock, you can securely connect foundation models (FMs) in Amazon Bedrock to your company data for fully managed Retrieval Augmented Generation (RAG).
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
Last Updated on August 17, 2023 by Editorial Team Author(s): Jeff Holmes MS MSCS Originally published on Towards AI. MLOps is the intersection of Machine Learning, DevOps, and Data Engineering. Zero, “ How to write better scientific code in Python,” Towards Data Science, Feb. 15, 2022. [4]
Last Updated on July 19, 2023 by Editorial Team Author(s): Yashashri Shiral Originally published on Towards AI. DataPreparation — Collect data, Understand features 2. Visualize Data — Rolling mean/ Standard Deviation— helps in understanding short-term trends in data and outliers.
It does so by covering the ML workflow end-to-end: whether you’re looking for powerful datapreparation and AutoML, managed endpoint deployment, simplified MLOps capabilities, and ready-to-use models powered by AWS AI services and Generative AI, SageMaker Canvas can help you to achieve your goals.
Context In early 2023, Zeta’s machine learning (ML) teams shifted from traditional vertical teams to a more dynamic horizontal structure, introducing the concept of pods comprising diverse skill sets. Airflow for workflow orchestration Airflow schedules and manages complex workflows, defining tasks and dependencies in Python code.
Semi-structured input Starting in 2023, Amazon Comprehend now supports training models using semi-structured documents. The training data for semi-structure input is comprised of a set of labeled documents, which can be pre-identified documents from a document repository that you already have access to.
Last Updated on January 31, 2023 by Editorial Team Last Updated on January 31, 2023 by Editorial Team Author(s): Oluwatimilehin Ogidan Originally published on Towards AI. Datapreparation The first thing I did was import the necessary libraries. I need to mount the data since the dataset is on my Google Drive.
Key programming languages include Python and R, while mathematical concepts like linear algebra and calculus are crucial for model optimisation. Understanding Machine Learning algorithms and effective data handling are also critical for success in the field. This growth signifies Python’s increasing role in ML and related fields.
Within watsonx.ai, users can take advantage of open-source frameworks like PyTorch, TensorFlow and scikit-learn alongside IBM’s entire machine learning and data science toolkit and its ecosystem tools for code-based and visual data science capabilities. Savings may vary depending on configurations, workloads and vendor.
Airflow allows you to configure, schedule, and monitor data pipelines programmatically in Python to define all the stages of the lifecycle of typical workflow management. We use DAG (Directed Acyclic Graph) in Airflow, DAGs describe how to run a workflow by defining the pipeline in Python, that is configuration as code.
The latter will map the model’s outputs to final labels and significantly ease the datapreparation process. Our examples use Python, but the concepts apply equally well to other coding languages. Other writers have composed thorough and robust tutorials on using the OpenAI Python library or using LangChain.
The latter will map the model’s outputs to final labels and significantly ease the datapreparation process. Our examples use Python, but the concepts apply equally well to other coding languages. Other writers have composed thorough and robust tutorials on using the OpenAI Python library or using LangChain.
A cordial greeting to all data science enthusiasts! I consider myself fortunate to have the opportunity to speak at the upcoming ODSC APAC conference slated for the 22nd of August 2023. The inferSchema parameter is set to True to infer the data types of the columns, and header is set to True to use the first row as headers.
My tips for working with code in notebooks are the following: Move auxiliary functions to plain Python modules Generally, importing functions defined in Python modules is better than defining them in the notebook. If a reviewer wants more detail, they can always look at the Python module directly. For one, Git diffs within.py
Fine-tuning is important for applying domain-specific knowledge to an existing LLM which provides better performance and prompt results Inference Efficiency An emergent skill in late 2023, its inclusion speaks to its importance. PythonPython’s prominence is expected. Kubernetes: A long-established tool for containerized apps.
Continuous learning and adaptation will be essential for data professionals. Introduction Data Science has transformed the way businesses operate, enabling them to make data-driven decisions that enhance efficiency and innovation. As of 2023, the global Data Science market is projected to reach approximately USD 322.9
In terms of resulting speedups, the approximate order is programming hardware, then programming against PBA APIs, then programming in an unmanaged language such as C++, then a managed language such as Python. In November 2023, AWS announced the next generation Trainium2 chip. GPU PBAs, 4% other PBAs, 4% FPGA, and 0.5%
They facilitate complex calculations, trend analysis, and data modelling, making them essential for generating insights from the stored data. The global data warehouse as a service market was valued at USD 9.06 billion in 2023 and is projected to reach USD 55.96 The global data storage market was valued at USD 186.75
The latter will map the model’s outputs to final labels and significantly ease the datapreparation process. Our examples use Python, but the concepts apply equally well to other coding languages. Other writers have composed thorough and robust tutorials on using the OpenAI Python library or using LangChain.
Knowing this, you want to have dataprepared in a way to optimize your load. Snowflake Connectors For accessing data, you’ll find a slew of Snowflake connectors on the Snowflake website. For example: ODBC JDBC Python Snowflake Connector And, generally, things will be okay. Be sure to test your scenarios, though.
We also import the Image class from the PIL (Python Imaging Library) to handle image operations on Line 8. Lastly, on Line 10 , the tqdm library is incorporated to display progress bars during data processing and model training. Key steps encompass: Datapreparation and splitting into training and validation sets.
Again, what goes on in this component is subjective to the data scientist’s initial (manual) datapreparation process, the problem, and the data used. Metaflow differs from other pipelining frameworks because it can load and store artifacts (such as data and models) as regular Python instance variables.
Last Updated on July 19, 2023 by Editorial Team Author(s): Abhishek Annamraju Originally published on Towards AI. Installation Installation is quite simple* Clone the library* Run installation script Support available for▹ Python — 3.6▹ With Monk, it is easier to do the same using simple pythonic syntax. Cuda — 9.0,
An end-to-end Machine Learning Project has the following steps: Problem statement Data Collection Data Visualisation DataPreparation Building a Model Deployment of the Model Figure 1: Process of an End-to-End Machine Learning Project Problem Statement Let’s say you are working as a Data Scientist at a hospital.
Solution overview To implement our RAG workflow on SageMaker JumpStart, we use a popular open source Python library known as LangChain. SageMaker JumpStart simplifies this process because the model artifacts, data, and container specifications are all pre-packaged for optimal inference.
RAG retrieves data from a preexisting knowledge base (your data), combines it with the LLMs knowledge, and generates responses with more human-like language. However, in order for generative AI to understand your data, some amount of datapreparation is required, which involves a big learning curve.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content