This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction In the era of Data storehouse, the need for assimilating the data from contrasting sources into a single consolidated database requires you to Extract the data from its parent source, Transform and amalgamate it, and thus, Load it into the consolidated database (ETL).
They require strong programming skills, expertise in data processing, and knowledge of database management. They require strong database management skills, expertise in data modeling, and knowledge of database design. They require strong database management skills, expertise in data modeling, and knowledge of database design.
Learn more about the AWS zero-ETL future with newly launched AWS databases integrations with Amazon Redshift. In this session, learn about Amazon Redshift’s technical innovations including serverless, AI/ML-powered autonomics, and zero-ETL data integrations.
JDBC, for Java-specific environments, offers efficient Java-based database connectivity, while ODBC provides a versatile, language-independent solution. Introduction Database connectivity is a crucial link between applications and databases , allowing seamless data exchange. million in 2023 and is projected to reach $9,049.24
Summary: Open Database Connectivity (ODBC) is a standard interface that simplifies communication between applications and database systems. It enhances flexibility and interoperability, allowing developers to create database-agnostic code. billion in 2023, is projected to grow at a remarkable CAGR of 19.50% from 2024 to 2032.
Also, traditional database management tasks, including backups, upgrades and routine maintenance drain valuable time and resources, hindering innovation. By using fit-for-purpose databases, customers can efficiently run workloads, using the appropriate engine at the optimal cost to optimize analytics for the best price-performance.
Last Updated on March 21, 2023 by Editorial Team Author(s): Data Science meets Cyber Security Originally published on Towards AI. What are ETL and data pipelines? The source of extraction of data can be files like text files, excel sheets, word documents, databases like relational as well as non-relational, and also the APIs.
It’s a foundational skill for working with relational databases Just about every data scientist or analyst will have to work with relational databases in their careers. Another boon for efficient work that SQL provides is its simple and consistent syntax that allows for collaboration across multiple databases.
We looked at over 25,000 job descriptions, and these are the data analytics platforms, tools, and skills that employers are looking for in 2023. Data Wrangling: Data Quality, ETL, Databases, Big Data The modern data analyst is expected to be able to source and retrieve their own data for analysis.
On December 6 th -8 th 2023, the non-profit organization, Tech to the Rescue , in collaboration with AWS, organized the world’s largest Air Quality Hackathon – aimed at tackling one of the world’s most pressing health and environmental challenges, air pollution. This allows for data to be aggregated for further manufacturer-agnostic analysis.
Embeddings generation – An embeddings model is used to encode the semantic information of each chunk into an embeddings vector, which is stored in a vector database, enabling similarity search of user queries. Based on the query embeddings, the relevant documents are retrieved from the embeddings database using similarity search.
Kuber Sharma Director, Product Marketing, Tableau Kristin Adderson August 22, 2023 - 12:11am August 22, 2023 Whether you're a novice data analyst exploring the possibilities of Tableau or a leader with years of experience using VizQL to gain advanced insights—this is your list of key Tableau features you should know, from A to Z.
What is Matillion ETL? Matillion ETL is a platform designed to help you speed up your data pipeline development by connecting it to many different data sources, enabling teams to rapidly integrate and build sophisticated data transformations in a cloud environment with a very intuitive low-code/no-code GUI. With that, let’s dive in!
With that, let’s dive in What is Matillion ETL? Matillion ETL is a platform designed to help you speed up your data pipeline development by connecting it to many different data sources, enabling teams to rapidly integrate and build sophisticated data transformations in a cloud environment with a very intuitive low-code/no-code GUI.
Context In early 2023, Zeta’s machine learning (ML) teams shifted from traditional vertical teams to a more dynamic horizontal structure, introducing the concept of pods comprising diverse skill sets. Though it’s worth mentioning that Airflow isn’t used at runtime as is usual for extract, transform, and load (ETL) tasks.
The evolution of Presto at Uber Beginning of a data analytics journey Uber began their analytical journey with a traditional analytical database platform at the core of their analytics. They stood up a file-based data lake alongside their analytical database. Uber has made the Presto query engine connect to real-time databases.
Its use cases range from real-time analytics, fraud detection, messaging, and ETL pipelines. It can deliver a high volume of data with latency as low as two milliseconds. It is heavily used in various industries like finance, retail, healthcare, and social media. Example: openssl rsa -in C:tmpnew_rsa_key_v1.p8
These could include other databases, data lakes, SaaS applications (e.g. Salesforce), Access databases, SharePoint, or Excel spreadsheets. Database Objects These include tables, schemas, databases, stored procedures , and jobs (e.g. Oftentimes inventorizing database objects will uncover schemas, tables, etc.,
billion in 2029 , reflecting a compound annual growth rate (CAGR) of 5.35% from 2023 to 2029. The primary functions of BI tools include: Data Collection: Gathering data from multiple sources including internal databases, external APIs, and cloud services. Data Processing: Cleaning and organizing data for analysis.
They are responsible for building and maintaining data architectures, which include databases, data warehouses, and data lakes. Data Modelling Data modelling is creating a visual representation of a system or database. Physical Models: These models specify how data will be physically stored in databases.
This solution was implemented at a Fortune 500 media customer in H1 2023 and can be reused for other customers interested in building news recommenders. AWS Glue performs extract, transform, and load (ETL) operations to align the data with the Amazon Personalize datasets schema.
What are the best data preprocessing tools of 2023? In 2023, several data preprocessing tools have emerged as top choices for data scientists and analysts. It is known for its ability to connect to almost any database and offers features like reusable data flows, automating repetitive work.
The feature repository is essentially a database storing pre-computed and versioned features. There are ML systems, such as embedded systems in self-driving cars, that do not use feature stores as they require real-time safety-critical decisions and cannot wait for a response from an external database.
You also learned how to build an Extract Transform Load (ETL) pipeline and discovered the automation capabilities of Apache Airflow for ETL pipelines. To understand this, imagine you have a pipeline that extracts weather information from an API, cleans the weather information, and loads it into a database.
As Netezza creeps closer to its end-of-life date in early 2023, you may be looking for options to migrate to, this post will provide valuable insights into why Snowflake may be the best choice. Complete SQL Database No need to learn new tools as Snowflake supports the tools millions of business users already know how to use today.
But, it is not rare that data engineers and database administrators process, control, and store terabytes of data in projects that are not related to machine learning. Data from different formats, databases, and sources are combined together for modeling. Basically, every machine learning project needs data. DVC Git LFS neptune.ai
From reading CSV files to accessing databases, we will get you covered about anything and everything. Here’s what you’ll discover: Diverse Data Sources: Learn to import not just plain text files but also data from a variety of other software formats, including Excel spreadsheets, SQL, and relational databases.
These teams are as follows: Advanced analytics team (data lake and data mesh) – Data engineers are responsible for preparing and ingesting data from multiple sources, building ETL (extract, transform, and load) pipelines to curate and catalog the data, and prepare the necessary historical data for the ML use cases.
Reading & executing from.sql scripts We can use.sql files that are opened and executed from the notebook through a database connector library. connection_params: A dictionary containing PostgreSQL connection parameters, such as 'host', 'port', 'database', 'user', and 'password'.
Data management problems can also lead to data silos; disparate collections of databases that don’t communicate with each other, leading to flawed analysis based on incomplete or incorrect datasets. One way to address this is to implement a data lake: a large and complex database of diverse datasets all stored in their original format.
1 Watsonx.data offers built-in governance and automation to get to trusted insights within minutes, and integrations with existing databases and tools to simplify setup and user experience. 1 When comparing published 2023 list prices normalized for VPC hours of watsonx.data to several major cloud data warehouse vendors.
In a 2023 survey conducted by Gartner , customer service and support leaders cited customer data and analytics as a top priority for achieving their organizational goals. Data enrichment” refers to the merging of third-party data from an external, authoritative source with an existing database of customer information you’ve gathered yourself.
As Snowflake’s 2023 Partner of the Year , phData has unmatched experience with Snowflake migrations, platform management, automation needs, and machine learning foundations. Tasks can be used to automate data processing workflows, such as ETL jobs, data ingestion, and data transformation.
Traditionally, answering this question would involve multiple data exports, complex extract, transform, and load (ETL) processes, and careful data synchronization across systems. Users can write data to managed RMS tables using Iceberg APIs, Amazon Redshift, or Zero-ETL ingestion from supported data sources.
11 key differences in 2023 Photo by Jan Tinneberg on Unsplash Working in Data Science and Machine Learning (ML) professions can be a lot different from the expectation of it. You will need to learn to query different databases depending on which ones your company uses. Working as a Data Scientist — Expectation versus Reality!
The Ultimate Modern Data Stack Migration Guide phData Marketing July 18, 2023 This guide was co-written by a team of data experts, including Dakota Kelley, Ahmad Aburia, Sam Hall, and Sunny Yan. This typically results in long-running ETL pipelines that cause decisions to be made on stale or old data.
The Data Warehouse Admin has an IAM admin role and manages databases in Amazon Redshift. The Data Engineer has an IAM ETL role and runs the extract, transform, and load (ETL) pipeline using Spark to populate the Lakehouse catalog on RMS. Select the database that you just created and choose Edit. Choose Register location.
At a high level, we are trying to make machine learning initiatives more human capital efficient by enabling teams to more easily get to production and maintain their model pipelines, ETLs, or workflows. Related post MLOps Landscape in 2023: Top Tools and Platforms Read more Why have a DAG within a DAG? Stefan: Yeah.
database permissions, ETL capability, processing, etc.), So let’s use an example: say your goal is to join the tables order and detail from a database called db , and you’re using the field sku to join the two tables. it has to be done using custom SQL in Tableau?
Introduction MongoDB is a robust NoSQL database, crucial in today’s data-driven tech industry. MongoDB is a NoSQL database that handles large-scale data and modern application requirements. Unlike traditional relational databases, MongoDB stores data in flexible, JSON-like documents, allowing for dynamic schemas.
In transitional modeling, we’d add new atoms: Subject: Customer#1234 Predicate: hasEmailAddress Object: "john.new@example.com" Timestamp: 2023-07-24T10:00:00Z The old email address atoms are still there, giving us a complete history of how to contact John. Extract, Load, and Transform (ELT) using tools like dbt has largely replaced ETL.
To demonstrate, we provide a step-by-step walkthrough using Amazons 2023 letter to shareholders as source data. For example, consider how the following source document chunk from the Amazon 2023 letter to shareholders can be converted to question-answering ground truth. 11% $118B to $131B How much did AWS revenue increase in 2023?
Apache Iceberg flips that model on its head by bringing database-like capabilities to your data lake. Note : The spark.sql.catalog configuration is still required unless the AWS Glue scripts are built using Visual ETL Glue Job. It shows how easy it is to get started with Iceberg in a Glue-native way. impl", "org.apache.iceberg.aws.s3.S3FileIO")
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































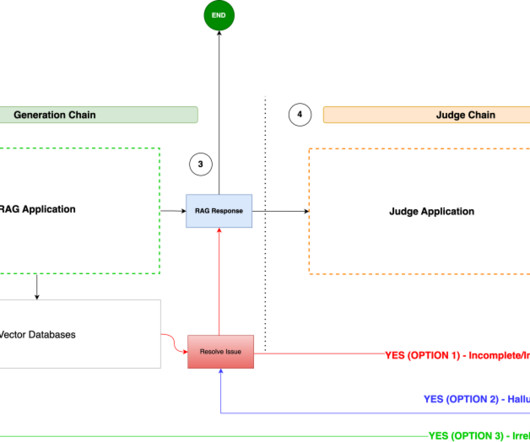







Let's personalize your content