This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Last Updated on July 24, 2023 by Editorial Team Author(s): Cristian Originally published on Towards AI. This is similar to how machine learning (ML) can seem at first. In the context of Machine Learning, data can be anything from images, text, numbers, to anything else that the computer can process and learn from.
Be sure to check out his session, “ Improving ML Datasets with Cleanlab, a Standard Framework for Data-Centric AI ,” there! Anybody who has worked on a real-world ML project knows how messy data can be. Everybody knows you need to clean your data to get good ML performance. A common gripe I hear is: “Garbage in, garbage out.
Posted by Catherine Armato, Program Manager, Google The Eleventh International Conference on Learning Representations (ICLR 2023) is being held this week as a hybrid event in Kigali, Rwanda. We are proud to be a Diamond Sponsor of ICLR 2023, a premier conference on deep learning, where Google researchers contribute at all levels.
Posted by Shaina Mehta, Program Manager, Google This week marks the beginning of the premier annual Computer Vision and Pattern Recognition conference (CVPR 2023), held in-person in Vancouver, BC (with additional virtual content).
Rapid, model-guided iteration with New Studio for all core ML tasks. Enhanced studio experience for all core ML tasks. Prompt LF Builder: Explore and label data through natural language prompts using FM knowledge and translate it into labeling functions for your weakly supervisedlearning use cases. Advanced SDK tools.
2022 was a big year for AI, and we’ve seen significant advancements in various areas – including natural language processing (NLP), machine learning (ML), and deep learning. Unsupervised and self-supervisedlearning are making ML more accessible by lowering the training data requirements.
We’re excited to announce that many CDS faculty, researchers, and students will present at the upcoming thirty-seventh 2023 NeurIPS (Neural Information Processing Systems) Conference , taking place Sunday, December 10 through Saturday, December 16. The conference will take place in-person at the New Orleans Ernest N.
Posted by Cat Armato, Program Manager, Google Groups across Google actively pursue research in the field of machine learning (ML), ranging from theory and application. We build ML systems to solve deep scientific and engineering challenges in areas of language, music, visual processing, algorithm development, and more.
Last Updated on March 4, 2023 by Editorial Team Author(s): Harshit Sharma Originally published on Towards AI. Fully-SupervisedLearning (Non-Neural Network) — powered by — Feature Engineering Supervisedlearning required input-output examples to train the model. Let’s get started !!
Chirp is able to cover such a wide variety of languages by leveraging self-supervisedlearning on unlabeled multilingual dataset with fine-tuning on a smaller set of labeled data. Chirp is now available in the Google Cloud Speech-to-Text API , allowing users to perform inference on the model through a simple interface.
As part of its goal to help people live longer, healthier lives, Genomics England is interested in facilitating more accurate identification of cancer subtypes and severity, using machine learning (ML). 2022 ) is a multi-modal ML framework that consists of three sub-network components (see Figure 1 at Chen et al.,
Between December 2022 and April 2023, 404 participants from 59 countries signed up to solve the problems posed by the two tracks, and 82 went on to submit solutions. Self-supervisedlearning allows for effective use of unlabeled data for training models for representation learning tasks.
Note : Now write some articles or blogs on the things you have learned because this thing will help you to develop soft skills as well if you want to publish some research paper on AI/ML so this writing habit will help you there for sure.
Data labeling remains a core requirement for any organization looking to use machine learning to solve tangible business problems, especially with the increased development and adoption of LLMs. That makes data labeling a foundational requirement for any supervised machine learning application—which describes the vast majority of ML projects.
How to Implement a Successful AI Strategy for Your Company Dominick Rocco July 17, 2023 AI is revolutionizing the world’s business landscape by enabling enterprises to automate tasks, create new products & services, and elevate customer experiences. Solutions Looking for Problems Many ML projects are spawned based on external inspiration.
Since the advent of deep learning in the 2000s, AI applications in healthcare have expanded. Machine Learning Machine learning (ML) focuses on training computer algorithms to learn from data and improve their performance, without being explicitly programmed. Originally published at [link] on January 27, 2023.
Last Updated on March 4, 2023 by Editorial Team Author(s): Towards AI Editorial Team Originally published on Towards AI. MIT course on Introduction to Data-Centric AI This is a practical course on Data-Centric AI, focusing on the impactful aspects of real-world ML applications.
Understanding Machine Learning algorithms and effective data handling are also critical for success in the field. Introduction Machine Learning ( ML ) is revolutionising industries, from healthcare and finance to retail and manufacturing. Fundamental Programming Skills Strong programming skills are essential for success in ML.
Summary: This article compares Artificial Intelligence (AI) vs Machine Learning (ML), clarifying their definitions, applications, and key differences. While AI aims to replicate human intelligence across various domains, ML focuses on learning from data to improve performance. What is Machine Learning?
Nature Reviews Drug Discovery 22, 260–260 (2023). Similarly, pLMs are pre-trained on large protein sequence databases using unlabeled, self-supervisedlearning. For example, in 2023, a research team described training a 100 billion-parameter pLM on 768 A100 GPUs for 164 days! COVID-19 Spikevax Moderna $21.8
Foundation models are large AI models trained on enormous quantities of unlabeled data—usually through self-supervisedlearning. What is self-supervisedlearning? Self-supervisedlearning is a kind of machine learning that creates labels directly from the input data. Find out in the guide below.
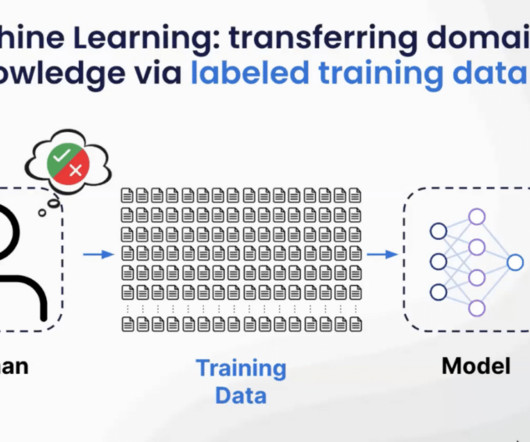
Reminder : Training data refers to the data used to train an AI model, and commonly there are three techniques for it: Supervisedlearning: The AI model learns from labeled data, which means that each data point has a known output or target value. Best AI models can be used in healthcare to improve diagnosis and treatment.
Reminder : Training data refers to the data used to train an AI model, and commonly there are three techniques for it: Supervisedlearning: The AI model learns from labeled data, which means that each data point has a known output or target value. Best AI models can be used in healthcare to improve diagnosis and treatment.
Abhishek Ratna, in AI ML marketing, and TensorFlow developer engineer Robert Crowe, both from Google, spoke as part of a panel entitled “Practical Paths to Data-Centricity in Applied AI” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. And in supervisedlearning, it has to be labeled data.
Abhishek Ratna, in AI ML marketing, and TensorFlow developer engineer Robert Crowe, both from Google, spoke as part of a panel entitled “Practical Paths to Data-Centricity in Applied AI” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. And in supervisedlearning, it has to be labeled data.
With this post, I am kicking off a series in which researchers across Google will highlight some exciting progress we've made in 2022 and present our vision for 2023 and beyond. I will begin with a discussion of language, computer vision, multi-modal models, and generative machine learning models.
Available at: [link] (Accessed: 8 February 2023). 2019) Applied SupervisedLearning with Python. Available at: [link] (Accessed: 19 February 2023). Johnston, B. and Mathur, I. Packt Publishing. Submission Suggestions How to Make GridSearchCV Work Smarter, Not Harder was originally published in MLearning.ai
The event was part of the chapter’s technical talk series 2023. The Technical Talk Series focuses on Technical Skills, bringing awareness about a technical topic, sharing knowledge, and ways to learn/enhance required skills, thus linking it to career development. We are hearing about NLP, LLMs, ChatGPT and Generative AI a lot !
Typically, you let the experts read some articles, label them, and then use them as training data and train the supervisedlearning model. To address all these problems, we looked into weak supervisedlearning. Once we label a fraction of documents, we use that as training data to train the supervisedlearning model.
Typically, you let the experts read some articles, label them, and then use them as training data and train the supervisedlearning model. To address all these problems, we looked into weak supervisedlearning. Once we label a fraction of documents, we use that as training data to train the supervisedlearning model.
There’s a twist; the approach frames supervisedlearning with rationales as a multi-task problem. The supervision not only predicts the task labels but also generates the corresponding rationales given the text input (and the ground truth). SOTA 3D 2023 // Your AI Mlearning.ai was originally published in MLearning.ai
dollars in 2024, a leap of nearly 50 billion compared to 2023. This rapid growth highlights the importance of learning AI in 2024, as the market is expected to exceed 826 billion U.S. This guide will help beginners understand how to learn Artificial Intelligence from scratch. Deep Learning is a subset of ML.
I consider myself fortunate to have the opportunity to speak at the upcoming ODSC APAC conference slated for the 22nd of August 2023. Our focus will be hands-on, with an emphasis on the practical application and understanding of essential machine learning concepts. A cordial greeting to all data science enthusiasts! from pyspark.ml
Background Many of the new exciting AI breakthroughs have come from two recent innovations: self-supervisedlearning and Transformers. Grounding DINO is a self-supervisedlearning algorithm that combines DINO with grounded pre-training. The model can identify and detect any object simply by providing a text prompt.
Conclusion This article described regression which is a supervisinglearning approach. We discussed the statistical method of fitting a line in Skicit Learn. Available at: [link] (Accessed: 15 April 2023). Available at: [link] (Accessed: 10 April 2023). 2020) Pragmatic Machine Learning with Python.
The 2023 Global Trends in AI Report by S&P Global reveals that 69% of respondents pushed at least one AI deployment into production. These include unsupervised or semi-supervisedlearning. It relies on machine learning algorithms. ML allows the processing of large volumes of data, often collected from the internet.
Available at: [link] (Accessed: 25 March 2023). 2019) Applied SupervisedLearning with Python. Available at: [link] (Accessed: 18 April 2023). 2019) Python Machine Learning. Available at: [link] (Accessed: 25 March 2023). Johnston, B. and Mathur, I. Packt Publishing. Raschka, S. and Mirjalili, V.
2023) [15] The term “Chinchilla optimal” refers to having a set number of FLOPS (floating point operations per second) or a fixed compute budget and asks what the most suitable model and data size is to minimize loss or optimize accuracy. International Conference on Learning Representations. [20] 12] Figure 1: Rishi Bommasani et al. “Do
A foundation model is a model trained on broad data, generally using self-supervision at scale, that can be adapted to a wide range of downstream tasks. The first key ingredient is self-supervisedlearning. So in classical ML, we have training data from, say, North America, and we want to train a model on it.
A foundation model is a model trained on broad data, generally using self-supervision at scale, that can be adapted to a wide range of downstream tasks. The first key ingredient is self-supervisedlearning. So in classical ML, we have training data from, say, North America, and we want to train a model on it.
And then of course, if you do supervisedlearning, we need labels for the model. So you might have some data in a data warehouse, you might have some data in real-time transport, or you might have third-party data. So in some use cases, we have natural labels. Thank you so much and have a nice day. Catch the sessions you missed!
And then of course, if you do supervisedlearning, we need labels for the model. So you might have some data in a data warehouse, you might have some data in real-time transport, or you might have third-party data. So in some use cases, we have natural labels. Thank you so much and have a nice day. Catch the sessions you missed!
As the number of ML-powered apps and services grows, it gets overwhelming for data scientists and ML engineers to build and deploy models at scale. Supporting the operations of data scientists and ML engineers requires you to reduce—or eliminate—the engineering overhead of building, deploying, and maintaining high-performance models.
The ability to automate this process using machine learning (ML) techniques allows healthcare professionals to more quickly diagnose certain cancers, coronary diseases, and ophthalmologic conditions. This user-friendly approach eliminates the steep learning curve associated with ML, which frees up clinicians to focus on their patients.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content