

AI Trends for 2023: Sparking Creativity and Bringing Search to the Next Level
Dataversity
DECEMBER 16, 2022
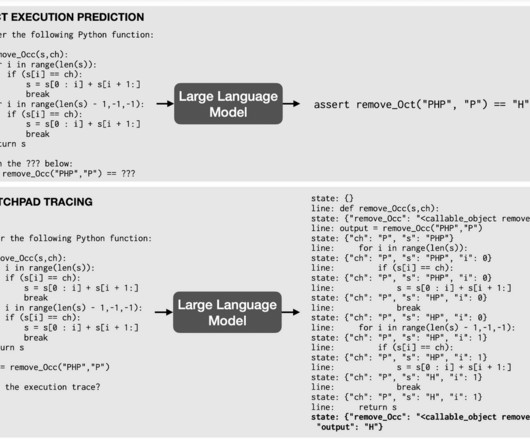
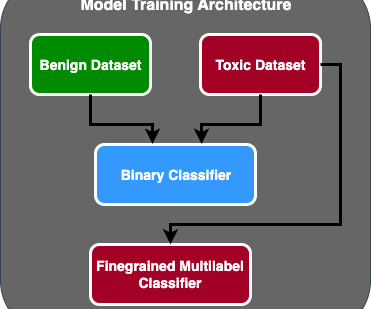
2022 was a big year for AI, and we’ve seen significant advancements in various areas – including natural language processing (NLP), machine learning (ML), and deep learning. Unsupervised and self-supervised learning are making ML more accessible by lowering the training data requirements.
























Let's personalize your content