This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The excitement is building for the fourteenth edition of AWS re:Invent, and as always, Las Vegas is set to host this spectacular event. Third, we’ll explore the robust infrastructure services from AWS powering AI innovation, featuring Amazon SageMaker , AWS Trainium , and AWS Inferentia under AI/ML, as well as Compute topics.
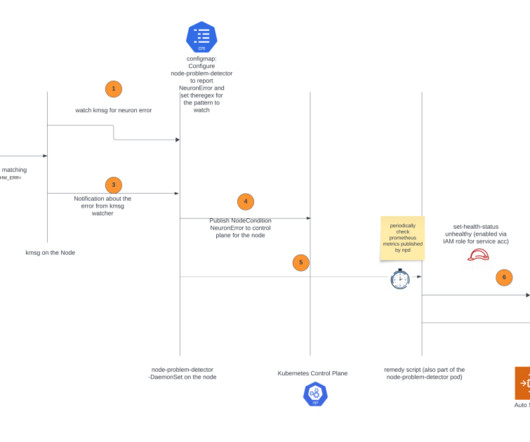
In the post, we introduce the AWS Neuron node problem detector and recovery DaemonSet for AWS Trainium and AWS Inferentia on Amazon Elastic Kubernetes Service (Amazon EKS). eks-5e0fdde Install the required AWS Identity and Access Management (IAM) role for the service account and the node problem detector plugin.
AWS was delighted to present to and connect with over 18,000 in-person and 267,000 virtual attendees at NVIDIA GTC, a global artificial intelligence (AI) conference that took place March 2024 in San Jose, California, returning to a hybrid, in-person experience for the first time since 2019.
Amazon SageMaker HyperPod recipes At re:Invent 2024, we announced the general availability of Amazon SageMaker HyperPod recipes. The launcher interfaces with underlying cluster management systems such as SageMaker HyperPod (Slurm or Kubernetes) or training jobs, which handle resource allocation and scheduling. recipes=recipe-name.
The compute clusters used in these scenarios are composed of more than thousands of AI accelerators such as GPUs or AWS Trainium and AWS Inferentia , custom machine learning (ML) chips designed by Amazon Web Services (AWS) to accelerate deep learning workloads in the cloud.
In 2024, however, organizations are using large language models (LLMs), which require relatively little focus on NLP, shifting research and development from modeling to the infrastructure needed to support LLM workflows. Historically, natural language processing (NLP) would be a primary research and development expense.
OpenAI launched GPT-4o in May 2024, and Amazon introduced Amazon Nova models at AWS re:Invent in December 2024. The implementation included a provisioned three-node sharded OpenSearch Service cluster. Interested users are invited to try out FloTorch from AWS Marketplace or from GitHub.
The number of companies launching generative AI applications on AWS is substantial and building quickly, including adidas, Booking.com, Bridgewater Associates, Clariant, Cox Automotive, GoDaddy, and LexisNexis Legal & Professional, to name just a few. Innovative startups like Perplexity AI are going all in on AWS for generative AI.
Distributed model training requires a cluster of worker nodes that can scale. In this blog post, AWS collaborates with Meta’s PyTorch team to discuss how to use the PyTorch FSDP library to achieve linear scaling of deep learning models on AWS seamlessly using Amazon EKS and AWS Deep Learning Containers (DLCs).
This capability allows for the seamless addition of SageMaker HyperPod managed compute to EKS clusters, using automated node and job resiliency features for foundation model (FM) development. FMs are typically trained on large-scale compute clusters with hundreds or thousands of accelerators.
SnapLogic uses Amazon Bedrock to build its platform, capitalizing on the proximity to data already stored in Amazon Web Services (AWS). To address customers’ requirements about data privacy and sovereignty, SnapLogic deploys the data plane within the customer’s VPC on AWS.
By early 2024, we are beginning to see the start of “Act 2,” in which many POCs are evolving into production, delivering significant business value. Introducing Amazon Elastic Kubernetes Service (Amazon EKS) in Amazon SageMaker HyperPod Recognizing these challenges, AWS launched Amazon SageMaker HyperPod last year.
The following figure illustrates the idea of a large cluster of GPUs being used for learning, followed by a smaller number for inference. Examples of other PBAs now available include AWS Inferentia and AWS Trainium , Google TPU, and Graphcore IPU. Suppliers of data center GPUs include NVIDIA, AMD, Intel, and others.
This is a joint blog with AWS and Philips. Since 2014, the company has been offering customers its Philips HealthSuite Platform, which orchestrates dozens of AWS services that healthcare and life sciences companies use to improve patient care.
Let’s look at some examples from the current season (2023–2024) The following videos show examples of measured shots that achieved top-speed values. To process match metadata, we use an AWS Lambda function called MetaDataIngestion , while positional data is brought in using an AWS Fargate container known as MatchLink.
Artificial intelligence has been adopted by over 72% of companies so far (McKinsey Survey 2024). Adding to the numbers, PwCs 2024 AI Jobs Barometer confirms that jobs requiring AI specialist skills have grown over 3 times faster than all other jobs. Generative AI with LLMs course by AWS AND DEEPLEARNING.AI
We are proud to announce the latest generation of enterprise readiness features for Snorkel Flow introduced in our 2024.R3 In future releases, Snorkel will provide integrations with cloud-native services like AWS Secrets Manager or equivalents on GCP and Azure. Although unavailable in 2024.R3 R3 release.
billion by the end of 2024 , reflecting a remarkable increase from $29 billion in 2022. High-Performance Computing (HPC) Clusters These clusters combine multiple GPUs or TPUs to handle extensive computations required for training large generative models. The global Generative AI market is projected to exceed $66.62
The Insights This comprehensive guide, updated for 2024, delves into the challenges and strategies associated with scaling Data Science careers. Embrace Distributed Processing Frameworks Frameworks like Apache Spark and Spark Streaming enable distributed processing of large datasets across clusters of machines.
In this post, AWS collaborates with Meta’s PyTorch team to showcase how you can use Meta’s torchtune library to fine-tune Meta Llama-like architectures while using a fully-managed environment provided by Amazon SageMaker Training. Refer to the installation instructions and PyTorch documentation to learn more about torchtune and its concepts.
EVENT — ODSC East 2024 In-Person and Virtual Conference April 23rd to 25th, 2024 Join us for a deep dive into the latest data science and AI trends, tools, and techniques, from LLMs to data analytics and from machine learning to responsible AI.
Cloud-agnostic and can run on any Kubernetes cluster. Integration: It can work alongside other workflow orchestration tools (Airflow cluster or AWS SageMaker Pipelines, etc.) The Metaflow stack can be easily deployed to any of the leading cloud providers or an on-premise Kubernetes cluster.
Best MLOps Tools & Platforms for 2024 In this section, you will learn about the top MLOps tools and platforms that are commonly used across organizations for managing machine learning pipelines. Data storage and versioning Some of the most popular data storage and versioning tools are Git and DVC.
Deployment Server Tools: Kubernetes, Docker Swarm, AWS CodeDeploy Purpose: Automates the deployment of applications to staging or production environments. Orchestration Tools: Kubernetes, Docker Swarm Purpose: Manages the deployment, scaling, and operation of application containers across clusters of hosts. What's next? Sharma, eds.,
Thrive in the Data Tooling Tornado Adam Breindel | Independent Consultant In this talk, Adam Breindel, a leading Apache Spark instructor and authority on neural-net fraud detection, streaming analytics and cluster management code, will help you navigate the data tooling landscape. NET, and AWS.
This blog was originally written by Erik Hyrkas and updated for 2024 by Justin Delisi This isn’t meant to be a technical how-to guide — most of those details are readily available via a quick Google search — but rather an opinionated review of key processes and potential approaches. In this case, the max cluster count should also be two.
Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high data quality, and informed decision-making capabilities. Also Read: Top 10 Data Science tools for 2024. Scalability: It offers scalability to handle large volumes of data across distributed computing clusters.
from 2024 to 2030. By clustering identical keys, the Shuffle and Sort phase minimises the complexity of downstream tasks and paves the way for more efficient data reduction. You can easily create and manage your cluster without worrying about on-premises hardware. billion in 2023 and will likely expand at a CAGR of 14.9%
billion by 2031, growing at a CAGR of 25.55% during the forecast period from 2024 to 2031. million in 2024 and is projected to grow at a CAGR of 26.8% billion in 2024 to USD 774.00 during the forecast period from 2024 to 2032. The global data warehouse as a service market was valued at USD 9.06 from 2025 to 2030.
billion in 2024, at a CAGR of 10.7%. Key techniques in unsupervised learning include: Clustering (K-means) K-means is a clustering algorithm that groups data points into clusters based on their similarities. This growth signifies Python’s increasing role in ML and related fields. billion in 2023 to $181.15
Therefore, in 2024, you will very much run into apps driven by computer vision. Tesla, for instance, relies on a cluster of NVIDIA A100 GPUs to train their vision-based autonomous driving algorithms. It helped build applications around image classification, object detection, face recognition and so much more!
Understanding Matillion and Snowflake, the Python Component, and Why it is Used Matillion is a SaaS-based data integration platform that can be hosted in AWS, Azure, or GCP and supports multiple cloud data warehouses. This is a Custom Filewatcher using Python and AWS S3. If the file is present, it will exit successfully. 30 minutes).
In this post, we demonstrate how you can address this requirement by using Amazon SageMaker HyperPod training plans , which can bring down your training cluster procurement wait time. We further guide you through using the training plan to submit SageMaker training jobs or create SageMaker HyperPod clusters.
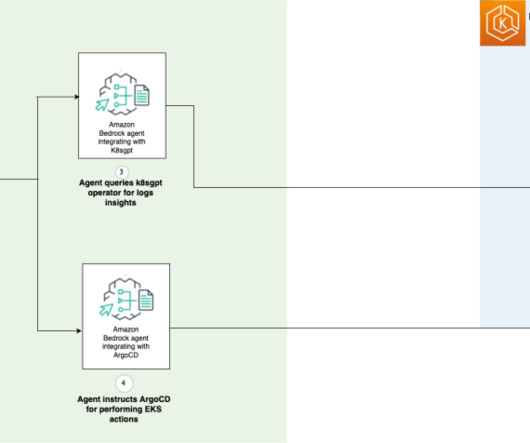
As organizations scale their Amazon Elastic Kubernetes Service (Amazon EKS) deployments, platform administrators face increasing challenges in efficiently managing multi-tenant clusters. At AWS re:Invent 2024, we announced the multi-agent collaboration capability for Amazon Bedrock (preview). An EKS cluster.
Although QLoRA helps optimize memory during fine-tuning, we will use Amazon SageMaker Training to spin up a resilient training cluster, manage orchestration, and monitor the cluster for failures. To take complete advantage of this multi-GPU cluster, we use the recent support of QLoRA and PyTorch FSDP. 24xlarge compute instance.
It now demands deep expertise, access to vast datasets, and the management of extensive compute clusters. To simplify this process, AWS introduced Amazon SageMaker HyperPod during AWS re:Invent 2023 , and it has emerged as a pioneering solution, revolutionizing how companies approach AI development and deployment.
At AWS re:Invent 2024, we launched a new innovation in Amazon SageMaker HyperPod on Amazon Elastic Kubernetes Service (Amazon EKS) that enables you to run generative AI development tasks on shared accelerated compute resources efficiently and reduce costs by up to 40%.
The solution was built in a recent collaboration between AWS Professional Services , under which Well-Architected machine learning design principles were followed. SageMaker Processing integrates seamlessly with AWS Identity and Access Management (IAM), Amazon Simple Storage Service (Amazon S3), AWS Step Functions , and other AWS services.
Transcribe audio with Amazon Transcribe In this case, we use an AWS re:Invent 2023 technical talk as a sample. Transcribe audio with Amazon Transcribe In this use case, we use an Amazon 2024 Q1 earnings call as a sample. Good day, everyone and welcome to the amazon.com first quarter, 2024 financial results teleconference.
Popular cloud load balancers like AWS ELB, Google Cloud Load Balancer, and Azure Load Balancer enhance cloud performance. billion in 2024 and is expected to reach USD 24.58 Dispatcher-Based Load Balancing Cluster A dispatcher module efficiently distributes incoming requests based on server availability, workload, and capacity.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content