This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Lets assume that the question What date will AWS re:invent 2024 occur? The corresponding answer is also input as AWS re:Invent 2024 takes place on December 26, 2024. If the question was Whats the schedule for AWS events in December?, is within the verified semantic cache. Query processing: a.
SnapLogic uses Amazon Bedrock to build its platform, capitalizing on the proximity to data already stored in Amazon Web Services (AWS). Control plane and data plane implementation SnapLogic’s Agent Creator platform follows a decoupled architecture, separating the control plane and data plane for enhanced security and scalability.
Our 2024 mainframe trends recap focuses on modernization and the technologies and trends that can impact your own initiatives. With the emergence of cloud hyperscalers like AWS, Google, and Microsoft, the shift to the cloud has accelerated significantly. Let’s dive in.
Working with the AWS Generative AI Innovation Center , DoorDash built a solution to provide Dashers with a low-latency self-service voice experience to answer frequently asked questions, reducing the need for live agent assistance, in just 2 months. “We You can deploy the solution in your own AWS account and try the example solution.
But the allure of tackling large-scale projects, building robust models for complex problems, and orchestrating datapipelines might be pushing you to transition into Data Science architecture. So if you are looking forward to a Data Science career , this blog will work as a guiding light.
Examples of other PBAs now available include AWS Inferentia and AWS Trainium , Google TPU, and Graphcore IPU. Around this time, industry observers reported NVIDIA’s strategy pivoting from its traditional gaming and graphics focus to moving into scientific computing and data analytics.
Last Updated on June 3, 2024 by Editorial Team Author(s): Towards AI Editorial Team Originally published on Towards AI. Sagemaker is a fully managed AWS service comprising a suite of tools and services to facilitate an end-to-end machine learning (ML) lifecycle. Good morning, fellow learners.
Image generated with Midjourney In today’s fast-paced world of data science, building impactful machine learning models relies on much more than selecting the best algorithm for the job. Data scientists and machine learning engineers need to collaborate to make sure that together with the model, they develop robust datapipelines.
Effective data governance enhances quality and security throughout the data lifecycle. What is Data Engineering? Data Engineering is designing, constructing, and managing systems that enable data collection, storage, and analysis. The global data warehouse as a service market was valued at USD 9.06
Apache Kafka For data engineers dealing with real-time data, Apache Kafka is a game-changer. This open-source streaming platform enables the handling of high-throughput data feeds, ensuring that datapipelines are efficient, reliable, and capable of handling massive volumes of data in real-time.
Best MLOps Tools & Platforms for 2024 In this section, you will learn about the top MLOps tools and platforms that are commonly used across organizations for managing machine learning pipelines. Data storage and versioning Some of the most popular data storage and versioning tools are Git and DVC.
Wearable devices (such as fitness trackers, smart watches and smart rings) alone generated roughly 28 petabytes (28 billion megabytes) of data daily in 2020. And in 2024, global daily data generation surpassed 402 million terabytes (or 402 quintillion bytes). Massive, in fact.
Summary: Choosing the right ETL tool is crucial for seamless data integration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high data quality, and informed decision-making capabilities. Let’s unlock the power of ETL Tools for seamless data handling.
Data engineers will also work with data scientists to design and implement datapipelines; ensuring steady flows and minimal issues for data teams. They’ll also work with software engineers to ensure that the data infrastructure is scalable and reliable. Learn more about the cloud.
Developers can seamlessly build datapipelines, ML models, and data applications with User-Defined Functions and Stored Procedures. If your datapipeline requirements are quite straightforward—i.e., You have different developers working on building datapipelines/UDFs/stored procedures in the same environment.
By versioning datasets in the same way we version code, data teams can experiment, roll back changes, and merge datapipelines safely, all without duplicating data or slowing down operations.
At the time of writing this blog, the year is 2024, and companies that have not yet adopted Gen AI may be feeling the pressure of being left behind. The generative AI solutions from GCP Vertex AI, AWS Bedrock, Azure AI, and Snowflake Cortex all provide access to a variety of industry-leading foundational models.
This blog was originally written by Erik Hyrkas and updated for 2024 by Justin Delisi This isn’t meant to be a technical how-to guide — most of those details are readily available via a quick Google search — but rather an opinionated review of key processes and potential approaches. Use with caution, and test before committing to using them.
However, if the tool supposes an option where we can write our custom programming code to implement features that cannot be achieved using the drag-and-drop components, it broadens the horizon of what we can do with our datapipelines. In this example, the secret is an API key, which will be used later on in the pipeline.
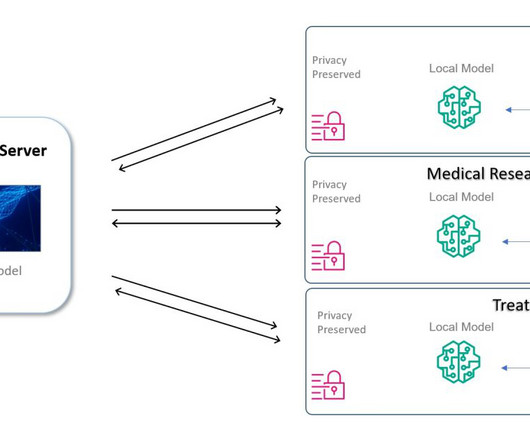
This approach can help heart stroke patients, doctors, and researchers with faster diagnosis, enriched decision-making, and more informed, inclusive research work on stroke-related health issues, using a cloud-native approach with AWS services for lightweight lift and straightforward adoption. Stroke victims can lose around 1.9
Summary: Data engineering tools streamline data collection, storage, and processing. Learning these tools is crucial for building scalable datapipelines. offers Data Science courses covering these tools with a job guarantee for career growth. Below are 20 essential tools every data engineer should know.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



























Let's personalize your content