This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The excitement is building for the fourteenth edition of AWS re:Invent, and as always, Las Vegas is set to host this spectacular event. The sessions showcase how Amazon Q can help you streamline coding, testing, and troubleshooting, as well as enable you to make the most of your data to optimize business operations.
We recommend referring to the Submit a model distillation job in Amazon Bedrock in the official AWS documentation for the most up-to-date and comprehensive information. Preparing your data Effective datapreparation is crucial for successful distillation of agent function calling capabilities.
Yes, the AWS re:Invent season is upon us and as always, the place to be is Las Vegas! are the sessions dedicated to AWS DeepRacer ! Generative AI is at the heart of the AWS Village this year. You marked your calendars, you booked your hotel, and you even purchased the airfare. And last but not least (and always fun!)
The number of companies launching generative AI applications on AWS is substantial and building quickly, including adidas, Booking.com, Bridgewater Associates, Clariant, Cox Automotive, GoDaddy, and LexisNexis Legal & Professional, to name just a few. Innovative startups like Perplexity AI are going all in on AWS for generative AI.
We made this process much easier through Snorkel Flow’s integration with Amazon SageMaker and other tools and services from Amazon Web Services (AWS). At its core, Snorkel Flow empowers data scientists and domain experts to encode their knowledge into labeling functions, which are then used to generate high-quality training datasets.
This is a joint blog with AWS and Philips. Since 2014, the company has been offering customers its Philips HealthSuite Platform, which orchestrates dozens of AWS services that healthcare and life sciences companies use to improve patient care.
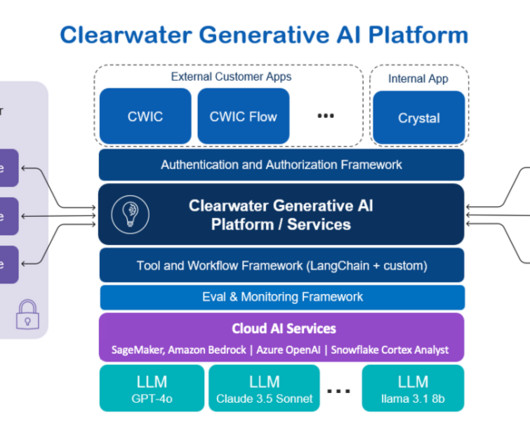
The explosion of data creation and utilization, paired with the increasing need for rapid decision-making, has intensified competition and unlocked opportunities within the industry. As of September 2024, the AI solution supports three core applications: Clearwater Intelligent Console (CWIC) Clearwaters customer-facing AI application.
Examples of other PBAs now available include AWS Inferentia and AWS Trainium , Google TPU, and Graphcore IPU. Around this time, industry observers reported NVIDIA’s strategy pivoting from its traditional gaming and graphics focus to moving into scientific computing and data analytics.
Top 10 Deep Learning Platforms The top ten deep-learning platforms that will be driving the market in 2024 are examined in this section. Launched by Microsoft, Azure ML provides a comprehensive suite of tools and services to support the entire machine learning lifecycle, from datapreparation to model deployment and management.
Using skills such as statistical analysis and data visualization techniques, prompt engineers can assess the effectiveness of different prompts and understand patterns in the responses. You may be expected to use other cloud platforms like AWS, GCP, and others, so don’t neglect them and at least be vaguely familiar with how they work.
A traditional machine learning (ML) pipeline is a collection of various stages that include data collection, datapreparation, model training and evaluation, hyperparameter tuning (if needed), model deployment and scaling, monitoring, security and compliance, and CI/CD.
Wearable devices (such as fitness trackers, smart watches and smart rings) alone generated roughly 28 petabytes (28 billion megabytes) of data daily in 2020. And in 2024, global daily data generation surpassed 402 million terabytes (or 402 quintillion bytes). Massive, in fact.
The global data warehouse as a service market was valued at USD 9.06 billion by 2031, growing at a CAGR of 25.55% during the forecast period from 2024 to 2031. This rapid growth highlights the increasing reliance on data warehouses for informed decision-making and strategic planning. billion in 2024 to USD 774.00
billion in 2024, at a CAGR of 10.7%. R and Other Languages While Python dominates, R is also an important tool, especially for statistical modelling and data visualisation. Data Transformation Transforming dataprepares it for Machine Learning models. billion in 2023 to $181.15
This blog was originally written by Erik Hyrkas and updated for 2024 by Justin Delisi This isn’t meant to be a technical how-to guide — most of those details are readily available via a quick Google search — but rather an opinionated review of key processes and potential approaches.
RAG applications on AWS RAG models have proven useful for grounding language generation in external knowledge sources. This configuration might need to change depending on the RAG solution you are working with and the amount of data you will have on the file system itself. For IAM role , choose Create a new role.
Recognizing this challenge as an opportunity for innovation, F1 partnered with Amazon Web Services (AWS) to develop an AI-driven solution using Amazon Bedrock to streamline issue resolution. The objective was to use AWS to replicate and automate the current manual troubleshooting process for two candidate systems.
Prerequisites To use the model distillation feature, make sure that you have satisfied the following requirements: An active AWS account. Confirm the AWS Regions where the model is available and quotas. Selected teacher and student models enabled in Amazon Bedrock.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
























Let's personalize your content