This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The excitement is building for the fourteenth edition of AWS re:Invent, and as always, Las Vegas is set to host this spectacular event. Third, we’ll explore the robust infrastructure services from AWS powering AI innovation, featuring Amazon SageMaker , AWS Trainium , and AWS Inferentia under AI/ML, as well as Compute topics.
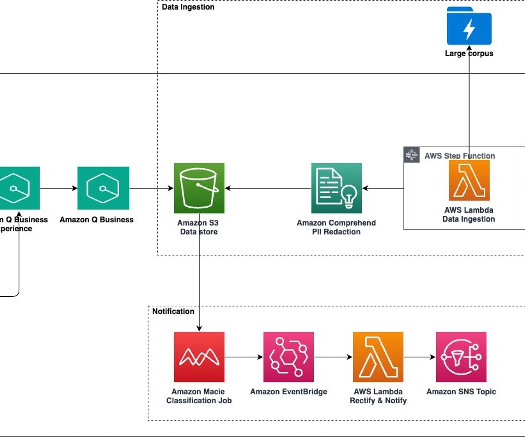
In business for 145 years, Principal is helping approximately 64 million customers (as of Q2, 2024) plan, protect, invest, and retire, while working to support the communities where it does business and build a diverse, inclusive workforce. The following diagram illustrates the Principal generative AI chatbot architecture with AWS services.
Enhancing AWS Support Engineering efficiency The AWS Support Engineering team faced the daunting task of manually sifting through numerous tools, internal sources, and AWS public documentation to find solutions for customer inquiries. Then we introduce the solution deployment using three AWS CloudFormation templates.
Today at AWS re:Invent 2024, we are excited to announce a new feature for Amazon SageMaker inference endpoints: the ability to scale SageMaker inference endpoints to zero instances. This long-awaited capability is a game changer for our customers using the power of AI and machine learning (ML) inference in the cloud.
Yes, the AWS re:Invent season is upon us and as always, the place to be is Las Vegas! Now all you need is some guidance on generative AI and machine learning (ML) sessions to attend at this twelfth edition of re:Invent. are the sessions dedicated to AWS DeepRacer ! are the sessions dedicated to AWS DeepRacer !
You can try out the models with SageMaker JumpStart, a machine learning (ML) hub that provides access to algorithms, models, and ML solutions so you can quickly get started with ML. The model is deployed in an AWS secure environment and under your virtual private cloud (VPC) controls, helping provide data security.
Lets assume that the question What date will AWS re:invent 2024 occur? The corresponding answer is also input as AWS re:Invent 2024 takes place on December 26, 2024. If the question was Whats the schedule for AWS events in December?, is within the verified semantic cache. Query processing: a.
The AWS DeepRacer League is the world’s first autonomous racing league, open to everyone and powered by machine learning (ML). AWS DeepRacer brings builders together from around the world, creating a community where you learn ML hands-on through friendly autonomous racing competitions.
Amazon Lookout for Vision , the AWS service designed to create customized artificial intelligence and machine learning (AI/ML) computer vision models for automated quality inspection, will be discontinuing on October 31, 2025. For an out-of-the-box solution, the AWS Partner Network offers solutions from multiple partners.
Since our founding nearly two decades ago, machine learning (ML) and artificial intelligence (AI) have been at the heart of building data-driven products that better match job seekers with the right roles and get people hired. Within weeks, we fine-tuned our best-performing model to-date and released it.
At re:Invent 2024, we are excited to announce new capabilities to speed up your AI inference workloads with NVIDIA accelerated computing and software offerings on Amazon SageMaker. We’ll walk through the process of deploying NVIDIA NIM microservices from AWS Marketplace for SageMaker Inference.
Virginia) AWS Region. Prerequisites To try the Llama 4 models in SageMaker JumpStart, you need the following prerequisites: An AWS account that will contain all your AWS resources. An AWS Identity and Access Management (IAM) role to access SageMaker AI. The example extracts and contextualizes the buildspec-1-10-2.yml
AWS Field Experience (AFX) empowers Amazon Web Services (AWS) sales teams with generative AI solutions built on Amazon Bedrock , improving how AWS sellers and customers interact. Last year, AFX introduced Account Summaries as the first in a forthcoming lineup of tools designed to support and streamline sales workflows.
We recommend referring to the Submit a model distillation job in Amazon Bedrock in the official AWS documentation for the most up-to-date and comprehensive information. You can track these job status details in both the AWS Management Console and AWS SDK. You are given a question and a set of possible functions.
You can try this model with SageMaker JumpStart, a machine learning (ML) hub that provides access to algorithms and models that can be deployed with one click for running inference. Prerequisites To try out Pixtral 12B in SageMaker JumpStart, you need the following prerequisites: An AWS account that will contain all your AWS resources.
Amazon Rekognition people pathing is a machine learning (ML)–based capability of Amazon Rekognition Video that users can use to understand where, when, and how each person is moving in a video. Example code The following code example is a Python script that can be used as an AWS Lambda function or as part of your processing pipeline.
At AWS, we believe the long-term success of AI depends on the ability to inspire trust among users, customers, and society. Achieving ISO/IEC 42001 certification means that an independent third party has validated that AWS is taking proactive steps to manage risks and opportunities associated with AI development, deployment, and operation.
At AWS re:Invent 2024, we are excited to introduce Amazon Bedrock Marketplace. Through Bedrock Marketplace, organizations can use Nemotron’s advanced capabilities while benefiting from the scalable infrastructure of AWS and NVIDIA’s robust technologies. Marc Karp is an ML Architect with the Amazon SageMaker Service team.
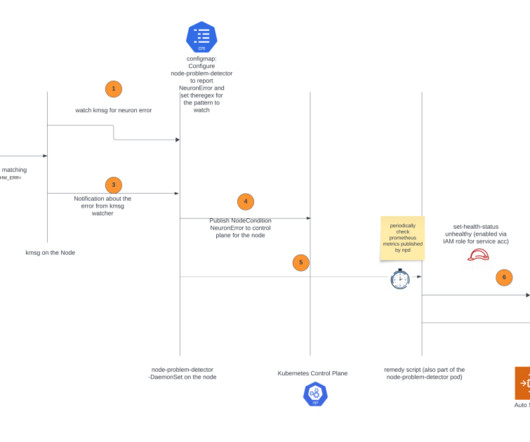
In the post, we introduce the AWS Neuron node problem detector and recovery DaemonSet for AWS Trainium and AWS Inferentia on Amazon Elastic Kubernetes Service (Amazon EKS). eks-5e0fdde Install the required AWS Identity and Access Management (IAM) role for the service account and the node problem detector plugin.
To solve this problem, this post shows you how to apply AWS services such as Amazon Bedrock , AWS Step Functions , and Amazon Simple Email Service (Amazon SES) to build a fully-automated multilingual calendar artificial intelligence (AI) assistant. It lets you orchestrate multiple steps in the pipeline.
In 2024, however, organizations are using large language models (LLMs), which require relatively little focus on NLP, shifting research and development from modeling to the infrastructure needed to support LLM workflows. Metaflow’s coherent APIs simplify the process of building real-world ML/AI systems in teams.
Over the last 18 months, AWS has announced more than twice as many machine learning (ML) and generative artificial intelligence (AI) features into general availability than the other major cloud providers combined. The following figure highlights where AWS lands in the DSML Magic Quadrant.
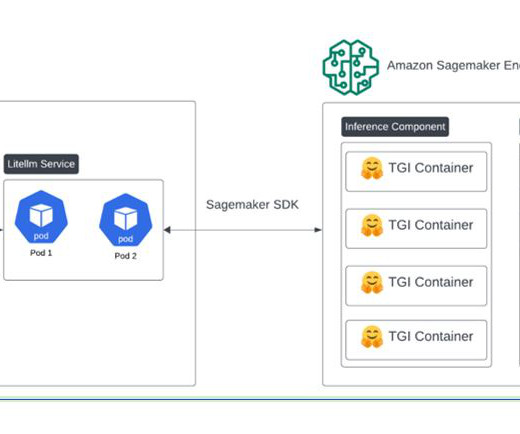
Today at AWS re:Invent 2024, we are excited to announce the new Container Caching capability in Amazon SageMaker, which significantly reduces the time required to scale generative AI models for inference. This feature is only supported when using inference components.
This post is part of an ongoing series on governing the machine learning (ML) lifecycle at scale. To start from the beginning, refer to Governing the ML lifecycle at scale, Part 1: A framework for architecting ML workloads using Amazon SageMaker.
Since launching in June 2023, the AWS Generative AI Innovation Center team of strategists, data scientists, machine learning (ML) engineers, and solutions architects have worked with hundreds of customers worldwide, and helped them ideate, prioritize, and build bespoke solutions that harness the power of generative AI.
According to New Relic’s 2024 Observability Forecast , businesses face a median annual downtime of 77 hours from high-impact outages. To get started on training, enroll for free Amazon Q training from AWS Training and Certification. Customer Solutions Manager at AWS. Solutions Architect at AWS. million per hour.
Amazon SageMaker HyperPod recipes At re:Invent 2024, we announced the general availability of Amazon SageMaker HyperPod recipes. This design simplifies the complexity of distributed training while maintaining the flexibility needed for diverse machine learning (ML) workloads, making it an ideal solution for enterprise AI development.
At AWS, we are transforming our seller and customer journeys by using generative artificial intelligence (AI) across the sales lifecycle. It will be able to answer questions, generate content, and facilitate bidirectional interactions, all while continuously using internal AWS and external data to deliver timely, personalized insights.
The number of companies launching generative AI applications on AWS is substantial and building quickly, including adidas, Booking.com, Bridgewater Associates, Clariant, Cox Automotive, GoDaddy, and LexisNexis Legal & Professional, to name just a few. Innovative startups like Perplexity AI are going all in on AWS for generative AI.
When we launched LLM-as-a-judge (LLMaJ) and Retrieval Augmented Generation (RAG) evaluation capabilities in public preview at AWS re:Invent 2024 , customers used them to assess their foundation models (FMs) and generative AI applications, but asked for more flexibility beyond Amazon Bedrock models and knowledge bases.
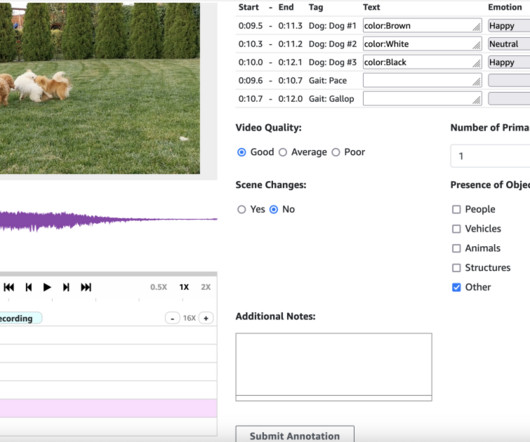
We guide you through deploying the necessary infrastructure using AWS CloudFormation , creating an internal labeling workforce, and setting up your first labeling job. Solution overview This audio/video segmentation solution combines several AWS services to create a robust annotation workflow. We demonstrate how to use Wavesurfer.js
OpenAI launched GPT-4o in May 2024, and Amazon introduced Amazon Nova models at AWS re:Invent in December 2024. The open source version works on a customers AWS account so you can experiment on your AWS account with your proprietary data. For more information, contact us at info@flotorch.ai.
During the last 18 months, we’ve launched more than twice as many machine learning (ML) and generative AI features into general availability than the other major cloud providers combined. Each application can be immediately scaled to thousands of users and is secure and fully managed by AWS, eliminating the need for any operational expertise.
Get ready to dive into the latest advancements in artificial intelligence as we unpack everything unveiled at GTC 2024, the premier AI conference for developers, business leaders, and AI researchers. Integration of the new NVIDIA Blackwell GPU platform into AWS infrastructure is announced, enhancing generative AI capabilities.
Prerequisites To build the solution yourself, there are the following prerequisites: You need an AWS account with an AWS Identity and Access Management (IAM) role that has permissions to manage resources created as part of the solution (for example AmazonSageMakerFullAccess and AmazonS3FullAccess ).
Amazon Elastic Compute Cloud (Amazon EC2) accelerated computing portfolio offers the broadest choice of accelerators to power your artificial intelligence (AI), machine learning (ML), graphics, and high performance computing (HPC) workloads. times larger and 1.4 times faster than H100 GPUs.
Based on a survey conducted by American Express in 2023, 41% of business meetings are expected to take place in hybrid or virtual format by 2024. Hugging Face is an open-source machine learning (ML) platform that provides tools and resources for the development of AI projects.
In 2024, several technologies are set to revolutionize the way we develop mobile apps, enhancing performance, security, and user experience. Machine learning frameworks Frameworks like TensorFlow Lite and Core ML allow developers to integrate machine learning models into mobile apps.
Amazon Lookout for Equipment , the AWS machine learning (ML) service designed for industrial equipment predictive maintenance, will no longer be open to new customers effective October 17, 2024. For an out-of-the-box solution, the AWS Partner Network offers solutions from multiple partners.
Amazon Monitron , the Amazon Web Services (AWS) machine learning (ML) service for industrial equipment condition monitoring, will no longer be available to new customers effective October 31, 2024. More details can be found in the following resources at AWS Partner Network. Product Manager for Monitron, at AWS.
Our solution aims to address those challenges using Amazon Bedrock and AWS Analytics Services. To address the challenges, our solution first incorporates the metadata of the data sources within the AWS Glue Data Catalog to increase the accuracy of the generated SQL query. Install the AWS Command Line Interface (AWS CLI).
SnapLogic uses Amazon Bedrock to build its platform, capitalizing on the proximity to data already stored in Amazon Web Services (AWS). At its core, Amazon Bedrock provides the foundational infrastructure for robust performance, security, and scalability for deploying machine learning (ML) models.
This is a joint blog with AWS and Philips. Since 2014, the company has been offering customers its Philips HealthSuite Platform, which orchestrates dozens of AWS services that healthcare and life sciences companies use to improve patient care.
The compute clusters used in these scenarios are composed of more than thousands of AI accelerators such as GPUs or AWS Trainium and AWS Inferentia , custom machine learning (ML) chips designed by Amazon Web Services (AWS) to accelerate deep learning workloads in the cloud. at a minimum).
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content