This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Using data versioning can make it possible to have the snapshot of the training data and experimentation results to make the implementation easier at each iteration. The above challenges can be tackled by using the following eight data version control tools.
Best MLOps Tools & Platforms for 2024 In this section, you will learn about the top MLOps tools and platforms that are commonly used across organizations for managing machine learning pipelines. Data storage and versioning Some of the most popular data storage and versioning tools are Git and DVC.
Effective data governance enhances quality and security throughout the data lifecycle. What is Data Engineering? Data Engineering is designing, constructing, and managing systems that enable data collection, storage, and analysis. The global data warehouse as a service market was valued at USD 9.06
While we may be done with events for 2023, 2024 is looking to be packed full of conferences, meetups, and virtual events. On the horizon is ODSC East 2024, which is shaping up to be just as packed with content as ODSC West was, but with its own spin on things. What’s next? Right now, tickets are 75% off for a limited time!
Apache Kafka For data engineers dealing with real-time data, Apache Kafka is a game-changer. This open-source streaming platform enables the handling of high-throughput data feeds, ensuring that datapipelines are efficient, reliable, and capable of handling massive volumes of data in real-time.
Data engineers will also work with data scientists to design and implement datapipelines; ensuring steady flows and minimal issues for data teams. They’ll also work with software engineers to ensure that the data infrastructure is scalable and reliable. Learn more about the cloud.
Wearable devices (such as fitness trackers, smart watches and smart rings) alone generated roughly 28 petabytes (28 billion megabytes) of data daily in 2020. And in 2024, global daily data generation surpassed 402 million terabytes (or 402 quintillion bytes). Massive, in fact.
This article was co-written by Mayank Singh & Ayush Kumar Singh Your organization’s datapipelines will inevitably run into issues, ranging from simple permission errors to significant network or infrastructure incidents. Failed Webhooks If webhooks are configured and the webhook event fails, a notification will be sent out.
Matillion’s Data Productivity Cloud is a versatile platform designed to increase the productivity of data teams. It provides a unified platform for creating and managing datapipelines that are effective for both coders and non-coders. Check out the API documentation for our sample.
This blog will delve into ETL Tools, exploring the top contenders and their roles in modern data integration. Let’s unlock the power of ETL Tools for seamless data handling. Also Read: Top 10 Data Science tools for 2024. It is a process for moving and managing data from various sources to a central data warehouse.
This blog was originally written by Erik Hyrkas and updated for 2024 by Justin Delisi This isn’t meant to be a technical how-to guide — most of those details are readily available via a quick Google search — but rather an opinionated review of key processes and potential approaches. authorization server.
Developers can seamlessly build datapipelines, ML models, and data applications with User-Defined Functions and Stored Procedures. If your datapipeline requirements are quite straightforward—i.e., You have different developers working on building datapipelines/UDFs/stored procedures in the same environment.
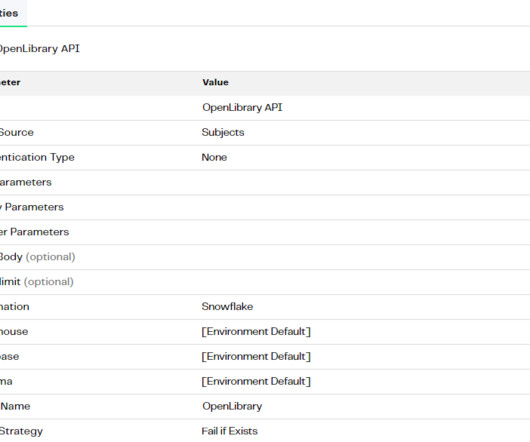
At the time of writing this blog, the year is 2024, and companies that have not yet adopted Gen AI may be feeling the pressure of being left behind. The generative AI solutions from GCP Vertex AI, AWS Bedrock, Azure AI, and Snowflake Cortex all provide access to a variety of industry-leading foundational models.
In March 2024, AWS announced it will offer the new NVIDIA Blackwell platform, featuring the new GB200 Grace Blackwell chip. High demand has risen from a range of sectors, including crypto mining, gaming, generic data processing, and AI. An important part of the datapipeline is the production of features, both online and offline.
However, if the tool supposes an option where we can write our custom programming code to implement features that cannot be achieved using the drag-and-drop components, it broadens the horizon of what we can do with our datapipelines. The default value is 360 seconds.
But the allure of tackling large-scale projects, building robust models for complex problems, and orchestrating datapipelines might be pushing you to transition into Data Science architecture. So if you are looking forward to a Data Science career , this blog will work as a guiding light.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





















Let's personalize your content