This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
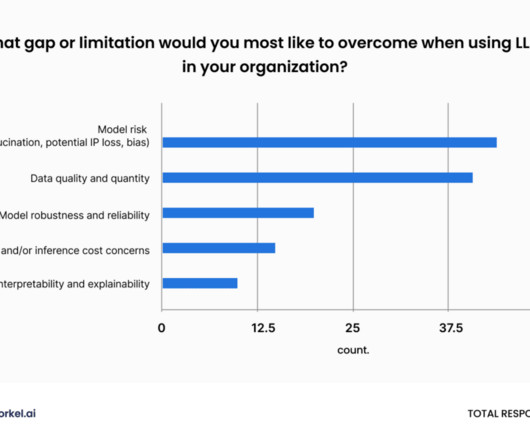
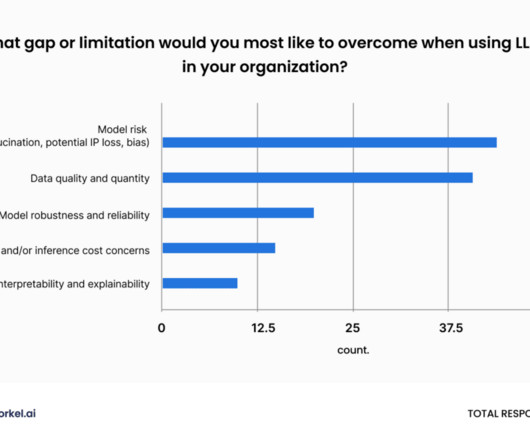
In this blog, we will explore the top 7 LLM, data science, and AI blogs of 2024 that have been instrumental in disseminating detailed and updated information in these dynamic fields. To keep up with these rapid developments, it’s crucial to stay informed through reliable and insightful sources.
Model Fitting and Training: Various ML models trained on sub-patterns in data. DataPreparation (Synthetic Data) Generating a Dataset Synthetic data constituting age, education, income, political alignment, media consumption, and the target variable-party affiliation will be generated in the same way as real-world voting behaviour.
This session covers the technical process, from datapreparation to model customization techniques, training strategies, deployment considerations, and post-customization evaluation. Explore how this powerful tool streamlines the entire ML lifecycle, from datapreparation to model deployment.
And if you purchased the first edition (prior to October 2024), you’re eligible for an additional discount. A major addition to the book is a brand-new chapter titled Indexes, Retrievers, and DataPreparation. Indexes, Retrievers, and DataPreparation are the foundational components of a RAG pipeline. What’s New?
Introduction The Formula 1 Prediction Challenge: 2024 Mexican Grand Prix brought together data scientists to tackle one of the most dynamic aspects of racing — pit stop strategies. This competition emphasized leveraging analytics in one of the world’s fastest and most data-intensive sports.
Figure 1: Example of a 2-dimensional KD-tree (source: Warnasooriya, Medium , 2024 ). We will start by setting up libraries and datapreparation. Setup and DataPreparation For implementing a similar word search, we will use the gensim library for loading pre-trained word embeddings vector. What's next? Thakur, eds.,
Last Updated on November 9, 2024 by Editorial Team Author(s): Houssem Ben Braiek Originally published on Towards AI. Datapreparation isn’t just a part of the ML engineering process — it’s the heart of it. This member-only story is on us. Upgrade to access all of Medium.
Kristin Adderson June 11, 2024 - 4:53pm Noel Carter Senior Product Marketing Manager, Tableau Evan Slotnick Product Management Director, Tableau At the Tableau Conference 2024 keynote , Tableau CEO Ryan Aytay spoke about the new wave of analytics: the consumerization of data. June 18, 2024
At its core, Snorkel Flow empowers data scientists and domain experts to encode their knowledge into labeling functions, which are then used to generate high-quality training datasets. This approach not only enhances the efficiency of datapreparation but also improves the accuracy and relevance of AI models.
Next Generation DataStage on Cloud Pak for Data Ensuring high-quality data A crucial aspect of downstream consumption is data quality. Studies have shown that 80% of time is spent on datapreparation and cleansing, leaving only 20% of time for data analytics. This leaves more time for data analysis.
LLM distillation will become a much more common and important practice for data science teams in 2024, according to a poll of attendees at Snorkel AI’s 2023 Enterprise LLM Virtual Summit. As data science teams reorient around the enduring value of small, deployable models, they’re also learning how LLMs can accelerate data labeling.
The Women in Big Data (WiBD) Spring Hackathon 2024, organized by WiDS and led by WiBD’s Global Hackathon Director Rupa Gangatirkar , sponsored by Gilead Sciences, offered an exciting opportunity to sharpen data science skills while addressing critical social impact challenges.
Preparing your data Effective datapreparation is crucial for successful distillation of agent function calling capabilities. Amazon Bedrock provides two primary methods for preparing your training data: uploading JSONL files to Amazon S3 or using historical invocation logs.
ODSC West 2024 showcased a wide range of talks and workshops from leading data science, AI, and machine learning experts. This blog highlights some of the most impactful AI slides from the world’s best data science instructors, focusing on cutting-edge advancements in AI, data modeling, and deployment strategies.
LLM distillation will become a much more common and important practice for data science teams in 2024, according to a poll of attendees at Snorkel AI’s 2023 Enterprise LLM Virtual Summit. As data science teams reorient around the enduring value of small, deployable models, they’re also learning how LLMs can accelerate data labeling.
Ensuring high-quality data A crucial aspect of downstream consumption is data quality. Studies have shown that 80% of time is spent on datapreparation and cleansing, leaving only 20% of time for data analytics. This leaves more time for data analysis. Let’s use address data as an example.
Optimising Power BI reports for performance ensures efficient data analysis. Power BI proficiency opens doors to lucrative data analytics and business intelligence opportunities, driving organisational success in today’s data-driven landscape. How does Power Query help in datapreparation?
It has versatile data connectivity, real-time data exploration, and plenty of community support that helps users, new to veterans, unleash the program’s full potential. Most of these features also come with AI assistance to help users find the best way to visualize their data.
Top 10 Deep Learning Platforms The top ten deep-learning platforms that will be driving the market in 2024 are examined in this section. Launched by Microsoft, Azure ML provides a comprehensive suite of tools and services to support the entire machine learning lifecycle, from datapreparation to model deployment and management.
You can even use generative AI to supplement your data sets with synthetic data for privacy or accuracy. Most businesses already recognize the need to automate the actual analysis of data, but you can go further. Automating the datapreparation and interpretation phases will take much time and effort out of the equation, too.
Using skills such as statistical analysis and data visualization techniques, prompt engineers can assess the effectiveness of different prompts and understand patterns in the responses. This skill focuses on minimizing the resources and time required for an LLM to generate output based on your prompts.
It now allows users to clean, transform, and integrate data from various sources, streamlining the Data Analysis process. This eliminates the need to rely on separate tools for datapreparation, saving time and resources.
A traditional machine learning (ML) pipeline is a collection of various stages that include data collection, datapreparation, model training and evaluation, hyperparameter tuning (if needed), model deployment and scaling, monitoring, security and compliance, and CI/CD.
Last Updated on January 29, 2024 by Editorial Team Author(s): Cassidy Hilton Originally published on Towards AI. Recapping the Cloud Amplifier and Snowflake Demo The combined power of Snowflake and Domo’s Cloud Amplifier is the best-kept secret in data management right now — and we’re reaching new heights every day.
At ODSC Europe 2024 , Noe Achache, Engineering Manager & Generative AI Lead at Sicara, spoke about the performance challenges and outlined key lessons and best practices for creating successful, high-performing LLM-based solutions. Real-world applications often expose gaps that proper datapreparation could have preempted.
more work on custom LLM pipelines, niche models and frameworks (agents, datapreparation, RAG, fine-tuning) and better foundational LLMs. We think the necessity for internal data and retrieval mechanisms in some form will always remain, and advanced custom LLM pipelines will continue to be essential.
Continuing the 2024 trend of rapid LLM cost reduction, OpenAI’s GPT-4o mini averages about 140x cheaper than GPT-4 was at its release just 16 months ago while also performing better on most benchmarks. Why should you care?
Last Updated on December 20, 2024 by Editorial Team Author(s): Towards AI Editorial Team Originally published on Towards AI. Datapreparation using Roboflow, model loading and configuration PaliGemma2 (including optional LoRA/QLoRA), and data loader creation are explained.
Last Updated on May 9, 2024 by Editorial Team Author(s): Stephen Chege-Tierra Insights Originally published on Towards AI. Conclusion Vertex AI is a major improvement over Google Cloud’s machine learning and data science solutions.
Last Updated on January 12, 2024 by Editorial Team Author(s): Hang Yu Originally published on Towards AI. train_ratio = 0.9train_size = int(len(ratings)*train_ratio)ratings_train = ratings.sample(train_size, random_state=42)ratings_test = ratings[~ratings.index.isin(ratings_train.index)] Now, we have the dataprepared.
We will start by setting up libraries and datapreparation. Setup and DataPreparation For this purpose, we will use the Pump Sensor Dataset , which contains readings of 52 sensors that capture various parameters (e.g., detection of potential failures or issues). temperature, pressure, vibration, etc.) What's next?
Last Updated on June 25, 2024 by Editorial Team Author(s): Mena Wang, PhD Originally published on Towards AI. Image generated by Gemini Spark is an open-source distributed computing framework for high-speed data processing. This practice vastly enhances the speed of my datapreparation for machine learning projects.
Wearable devices (such as fitness trackers, smart watches and smart rings) alone generated roughly 28 petabytes (28 billion megabytes) of data daily in 2020. And in 2024, global daily data generation surpassed 402 million terabytes (or 402 quintillion bytes). Massive, in fact.
Einstein Copilot for Tableau Einstein Copilot for Tableau superpowers analysts with a trusted AI assistant to help accelerate data-driven decision-making. Einstein Copilot for Tableau can also create visualizations from conversational prompts, and provide suggested questions to jumpstart data exploration. September 4, 2024
In this code talk, learn how to preparedata at scale using built-in datapreparation assistance, co-edit the same notebook in real time, and automate conversion of notebook code to production-ready jobs. You can also get behind the wheel yourself on November 30, when the track opens for the 2024 Open Racing.
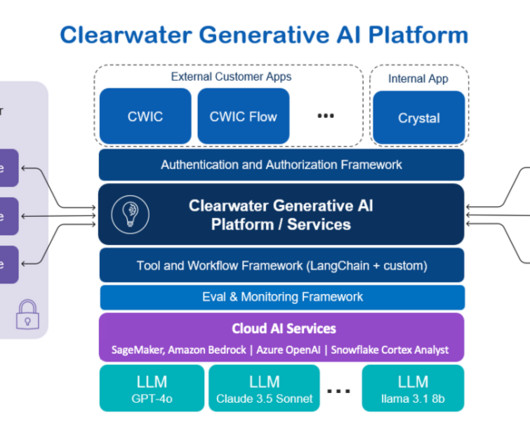
As of September 2024, the AI solution supports three core applications: Clearwater Intelligent Console (CWIC) Clearwaters customer-facing AI application. Datapreparation Upload the assembled documents to an S3 bucket, making sure theyre in a format suitable for the fine-tuning process.
We will start by setting up libraries and datapreparation. Setup and DataPreparation To start, we will first download the Credit Card Fraud Detection dataset, which contains details (e.g., Hence, we need robust and reliable fraud detection systems. for 3000+ credit card transactions. What's next? Kidriavsteva, and R.
The global data warehouse as a service market was valued at USD 9.06 billion by 2031, growing at a CAGR of 25.55% during the forecast period from 2024 to 2031. This rapid growth highlights the increasing reliance on data warehouses for informed decision-making and strategic planning. billion in 2024 to USD 774.00
Access to AWS environments SageMaker and associated AI/ML services are accessed with security guardrails for datapreparation, model development, training, annotation, and deployment. Users from several business units were trained and onboarded to the platform, and that number is expected to grow in 2024.
According to a recent report, the global embedded AI market is projected to reach US$826.70bn in 2030, growing at a compound annual growth rate (CAGR) of 28.46% from 2024 to 2030. This involves: DataPreparation : Collect and preprocess data to ensure it is suitable for training your model.
We expect our first Trainium2 instances to be available to customers in 2024. In early 2024, customers will also be able to redact personally identifiable information (PII) in model responses. And we are collaborating with Anthropic on continued innovation with both Trainium and Inferentia.
billion in 2024, at a CAGR of 10.7%. R and Other Languages While Python dominates, R is also an important tool, especially for statistical modelling and data visualisation. Data Transformation Transforming dataprepares it for Machine Learning models. billion in 2023 to $181.15
In March 2024, AWS announced it will offer the new NVIDIA Blackwell platform, featuring the new GB200 Grace Blackwell chip. Historical data is normally (but not always) independent inter-day, meaning that days can be parsed independently. For a given LOB, some events might be applicable to individual price levels independently.
It is projected to grow at a CAGR of 34.20% in the forecast period (2024-2031). Common Challenges in DataPreparation One of the most common challenges when preparing UCI datasets is dealing with missing data. The global Machine Learning market continues to expand. It was valued at USD 35.80 billion by 2031.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content