This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
CMU researchers are presenting 143 papers at the Thirteenth International Conference on Learning Representations (ICLR 2025), held from April 24 – 28 at the Singapore EXPO. The paper analyzes two families of self-improvement algorithms: one based on supervised fine-tuning (SFT) and one on reinforcement learning (RLHF).
In this article, we introduce the 2025 CVPR EARTHVISION Data Challenge an initiative by the Horizon Europe Embed2Scale consortium to advance neural compression for Earth Observation data. Currently, hand-crafted compression algorithms, often designed for general image data like JPEG2000, are applied.
Last Updated on April 24, 2025 by Editorial Team Author(s): SETIA BUDI SUMANDRA Originally published on Towards AI. Thats the motto of Unsupervised Learning a fascinating branch of machine learning where algorithmslearn patterns from unlabeled data. No Label, No Problem. Not part of the Mediums partner program?
By basing decisions on data and algorithms rather than gut feelings, businesses can reduce the influence of bias in critical systems. You will need to implement algorithms that let it choose actions on its own. Reinforcement Learning (RL) is a popular choice because it mimics how humans learn: by trial and error.
These labels provide crucial context for machine learning models, enabling them to make informed decisions and predictions. By 2025, a mind-boggling 463 exabytes of data will be created daily worldwide. These tasks are indispensable, as algorithms heavily rely on pattern recognition to make informed decisions.
Machine Learning (ML) is a subset of Artificial Intelligence (AI) that enables machines to improve their task performance by learning from data rather than following explicit instructions. ML algorithms use statistical methods to identify patterns in data, allowing systems to make predictions or decisions without human intervention.
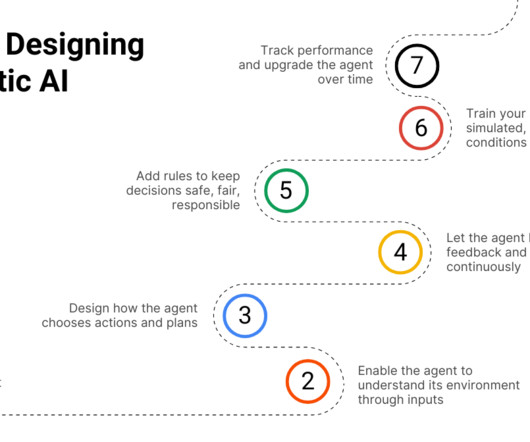
Last Updated on February 19, 2025 by Editorial Team Author(s): Talha Nazar Originally published on Towards AI. Unlike traditional software programs, AI agents use machine learning models to adapt their behavior based on data. Decision-Making: Algorithms to process inputs and decide on actions. Pandas: For data manipulation.
These include unsupervised or semi-supervisedlearning. It relies on machine learningalgorithms. Two Generative AI models are generative adversarial networks (GANs) and transformer-based models. GANs excel in creating visual and multimedia data. Transformer-based models, such as GPT, specialize in generating text.
As per the recent report by Nasscom and Zynga, the number of data science jobs in India is set to grow from 2,720 in 2018 to 16,500 by 2025. Top 5 Colleges to Learn Data Science (Online Platforms) 1. The amount increases with experience and varies from industry to industry.
Text labeling has enabled all sorts of frameworks and strategies in machine learning. Automated Labeling At the other extreme side of the labeling process, we can fully delegate the annotation to algorithms or pre-trained models. As of 2025, it is valued at approximately $14B.
Text labeling has enabled all sorts of frameworks and strategies in machine learning. Automated Labeling At the other extreme side of the labeling process, we can fully delegate the annotation to algorithms or pre-trained models. As of 2025, it is valued at approximately $14B.
Machine Learning Can Help Create Better Mesh Networks to Resolve Dead Zone Problems Pandemic conditions have forced many to work and study from home, making us scramble to set up our workspaces. They can also use perceptrons, which are supervisedlearningalgorithms for binary classification to monitor and deter malicious route floods.
Whether its algorithmic trading , risk assessment, fraud detection , credit scoring, or market analysis, the accuracy and depth of financial data can make or break an AI-driven solution. Model Selection: Choose between supervisedlearning (regression, classification) and unsupervised learning (clustering, anomaly detection).
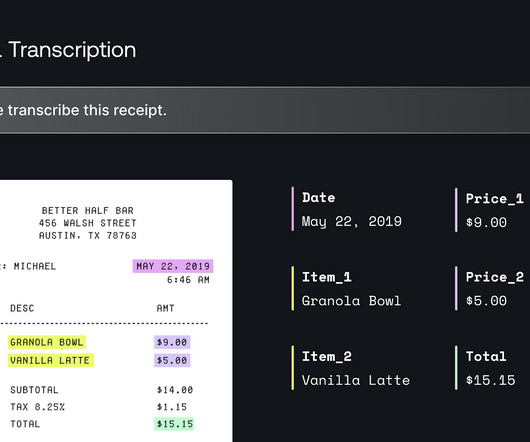
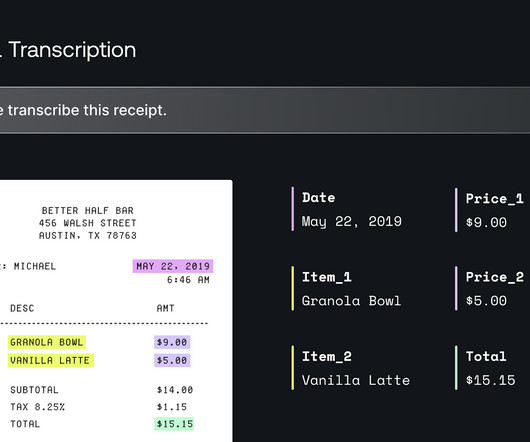
In this post, we explore how you can use Amazon Bedrock to generate high-quality categorical ground truth data, which is crucial for training machine learning (ML) models in a cost-sensitive environment. They'll evaluate it for inclusion in our 2025 roadmap. Lets look at how generative AI can help solve this problem.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















Let's personalize your content