
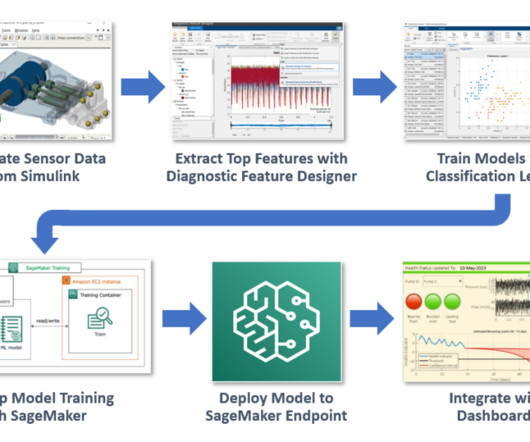
VAST Data Adds Blocks to Unified Storage Platform
insideBIGDATA
FEBRUARY 19, 2025
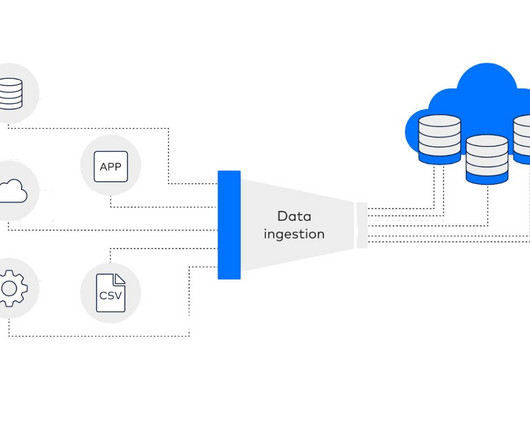
VAST also added the VAST Event Broker, an Apache Kafka-compatible event streaming service for real-time data ingestion and […]

insideBIGDATA
FEBRUARY 19, 2025
VAST also added the VAST Event Broker, an Apache Kafka-compatible event streaming service for real-time data ingestion and […]

databricks
AUGUST 12, 2024
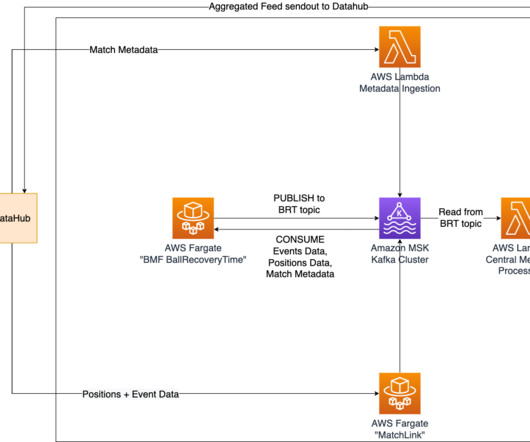
The blog explores data streams from NASA satellites using Apache Kafka and Databricks. It demonstrates ingestion and transformation with Delta Live Tables in SQL and AI/BI-powered analysis of supernova events.
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.

IBM Journey to AI blog
FEBRUARY 12, 2024
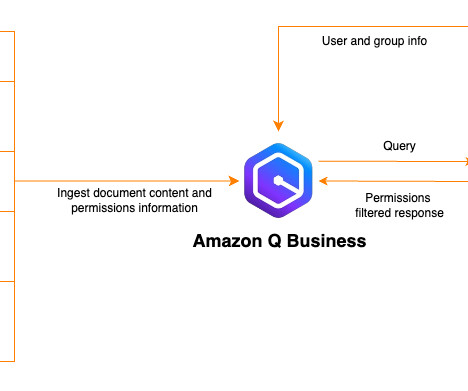
At the forefront of this event-driven revolution is Apache Kafka, the widely recognized and dominant open-source technology for event streaming. While most enterprises have already recognized how Apache Kafka provides a strong foundation for EDA, they often fall behind in unlocking its true potential.

IBM Journey to AI blog
NOVEMBER 3, 2023
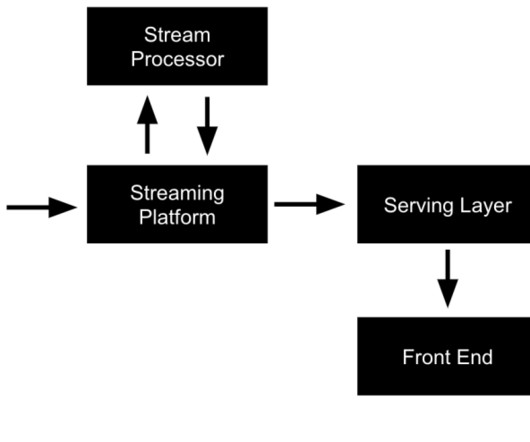
Apache Kafka and Apache Flink working together Anyone who is familiar with the stream processing ecosystem is familiar with Apache Kafka: the de-facto enterprise standard for open-source event streaming. With Apache Kafka, you get a raw stream of events from everything that is happening within your business.

IBM Journey to AI blog
SEPTEMBER 4, 2024
Apache Kafka is an open-source , distributed streaming platform that allows developers to build real-time, event-driven applications. With Apache Kafka, developers can build applications that continuously use streaming data records and deliver real-time experiences to users. How does Apache Kafka work?

Towards AI
FEBRUARY 29, 2024
Last Updated on February 29, 2024 by Editorial Team Author(s): Hira Akram Originally published on Towards AI. Within this article, we will explore the significance of these pipelines and utilise robust tools such as Apache Kafka and Spark to manage vast streams of data efficiently.

ODSC - Open Data Science
MAY 31, 2023
Be sure to check out his talk, “ Apache Kafka for Real-Time Machine Learning Without a Data Lake ,” there! The combination of data streaming and machine learning (ML) enables you to build one scalable, reliable, but also simple infrastructure for all machine learning tasks using the Apache Kafka ecosystem.

Expert insights. Personalized for you.





































Let's personalize your content