This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
To reduce costs while continuing to use the power of AI , many companies have shifted to fine tuning LLMs on their domain-specific data using Parameter-Efficient Fine Tuning (PEFT). Manually managing such complexity can often be counter-productive and take away valuable resources from your businesses AI development.
In 2018, I sat in the audience at AWS re:Invent as Andy Jassy announced AWS DeepRacer —a fully autonomous 1/18th scale race car driven by reinforcement learning. At the time, I knew little about AI or machine learning (ML). seconds, securing the 2018 AWS DeepRacer grand champion title!
AWS Trainium and AWS Inferentia based instances, combined with Amazon Elastic Kubernetes Service (Amazon EKS), provide a performant and low cost framework to run LLMs efficiently in a containerized environment. Solution overview The steps to implement the solution are as follows: Create the EKS cluster.
In the context of generative AI , significant progress has been made in developing multimodal embedding models that can embed various data modalities—such as text, image, video, and audio data—into a shared vector space. The AWS Command Line Interface (AWS CLI) installed on your machine to upload the dataset to Amazon S3.
Prerequisites Before you begin, make sure you have the following prerequisites in place: An AWS account and role with the AWS Identity and Access Management (IAM) privileges to deploy the following resources: IAM roles. For this post we’ll use a provisioned Amazon Redshift cluster. A SageMaker domain. Database name : Enter dev.
At ByteDance, we collaborated with Amazon Web Services (AWS) to deploy multimodal large language models (LLMs) for video understanding using AWS Inferentia2 across multiple AWS Regions around the world. The need for AI systems capable of processing various content forms has become increasingly apparent.
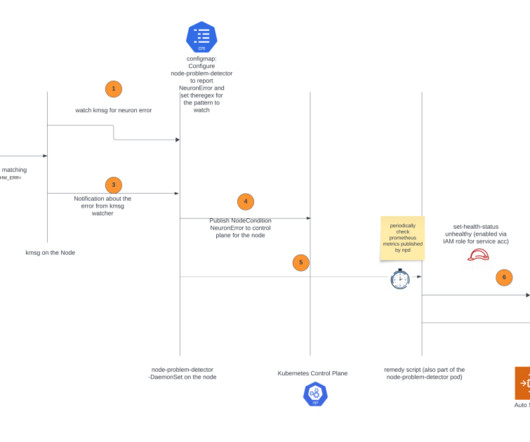
In the post, we introduce the AWS Neuron node problem detector and recovery DaemonSet for AWS Trainium and AWS Inferentia on Amazon Elastic Kubernetes Service (Amazon EKS). eks-5e0fdde Install the required AWS Identity and Access Management (IAM) role for the service account and the node problem detector plugin.
Increasingly, organizations across industries are turning to generative AI foundation models (FMs) to enhance their applications. The launcher interfaces with underlying cluster management systems such as SageMaker HyperPod (Slurm or Kubernetes) or training jobs, which handle resource allocation and scheduling. recipes=recipe-name.
Businesses are under pressure to show return on investment (ROI) from AI use cases, whether predictive machine learning (ML) or generative AI. Only 54% of ML prototypes make it to production, and only 5% of generative AI use cases make it to production. This post is cowritten with Isaac Cameron and Alex Gnibus from Tecton.
AWS was delighted to present to and connect with over 18,000 in-person and 267,000 virtual attendees at NVIDIA GTC, a global artificial intelligence (AI) conference that took place March 2024 in San Jose, California, returning to a hybrid, in-person experience for the first time since 2019.
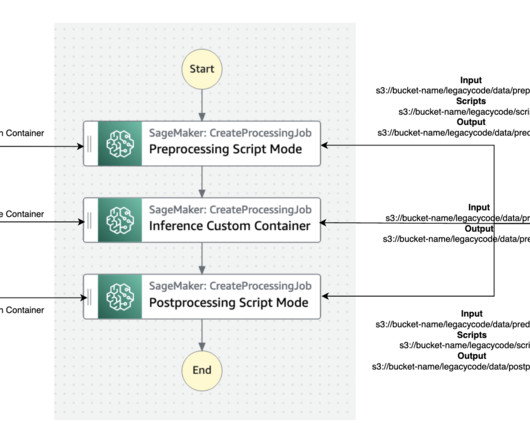
Although setting up a processing cluster is an alternative, it introduces its own set of complexities, from data distribution to infrastructure management. We use the purpose-built geospatial container with SageMaker Processing jobs for a simplified, managed experience to create and run a cluster. format("/".join(tile_prefix),
With the current housing shortage and affordability concerns, Rocket simplifies the homeownership process through an intuitive and AI-driven experience. Communication between the two systems was established through Kerberized Apache Livy (HTTPS) connections over AWS PrivateLink.
Starting with the AWS Neuron 2.18 release , you can now launch Neuron DLAMIs (AWS Deep Learning AMIs) and Neuron DLCs (AWS Deep Learning Containers) with the latest released Neuron packages on the same day as the Neuron SDK release. AWS DLCs provide a set of Docker images that are pre-installed with deep learning frameworks.
The intersection of AI and financial analysis presents a compelling opportunity to transform how investment professionals access and use credit intelligence, leading to more efficient decision-making processes and better risk management outcomes. It became apparent that a cost-effective solution for our generative AI needs was required.
The compute clusters used in these scenarios are composed of more than thousands of AI accelerators such as GPUs or AWS Trainium and AWS Inferentia , custom machine learning (ML) chips designed by Amazon Web Services (AWS) to accelerate deep learning workloads in the cloud.
Amazon Web Services (AWS) is committed to supporting the development of cutting-edge generative artificial intelligence (AI) technologies by companies and organizations across the globe. Let’s dive in and explore how these organizations are transforming what’s possible with generative AI on AWS.
Amazon SageMaker HyperPod is purpose-built to accelerate foundation model (FM) training, removing the undifferentiated heavy lifting involved in managing and optimizing a large training compute cluster. In this solution, HyperPod cluster instances use the LDAPS protocol to connect to the AWS Managed Microsoft AD via an NLB.
Generative AI solutions have the potential to transform businesses by boosting productivity and improving customer experiences, and using large language models (LLMs) with these solutions has become increasingly popular. Despite their wealth of general knowledge, state-of-the-art LLMs only have access to the information they were trained on.
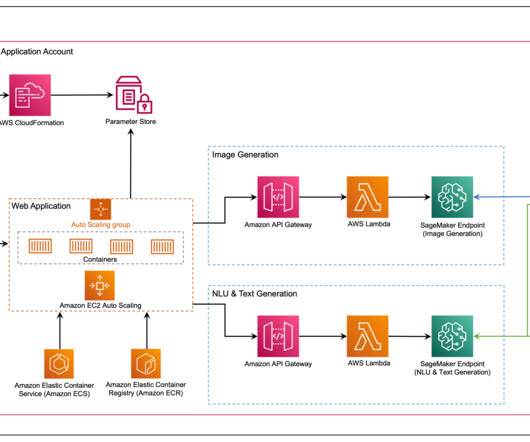
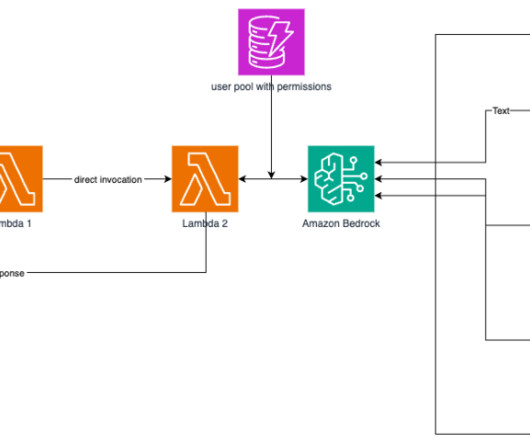
Amazon Bedrock is a fully managed service that makes foundation models (FMs) from leading AI startups and Amazon available through an API, so you can choose from a wide range of FMs to find the model that is best suited for your use case. AWS Lambda The API is a Fastify application written in TypeScript. Its hosted on AWS Lambda.
You can use these techniques together to train complex models that are orders of magnitude faster and rapidly iterate and deploy innovative AI solutions that drive business value. After they’re initiated, SageMaker training jobs spin up the cluster, provisioning the specified number and type of compute instances.
AWS (Amazon Web Services), the comprehensive and evolving cloud computing platform provided by Amazon, is comprised of infrastructure as a service (IaaS), platform as a service (PaaS) and packaged software as a service (SaaS). With its wide array of tools and convenience, AWS has already become a popular choice for many SaaS companies.
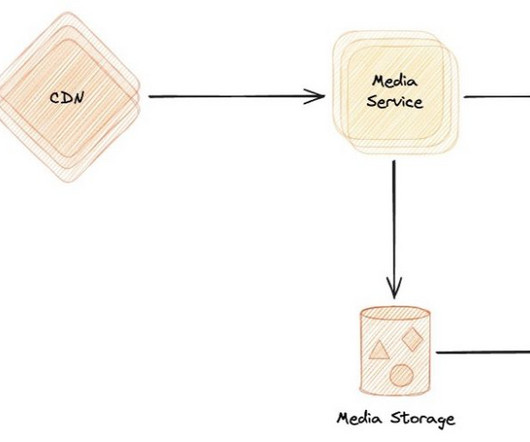
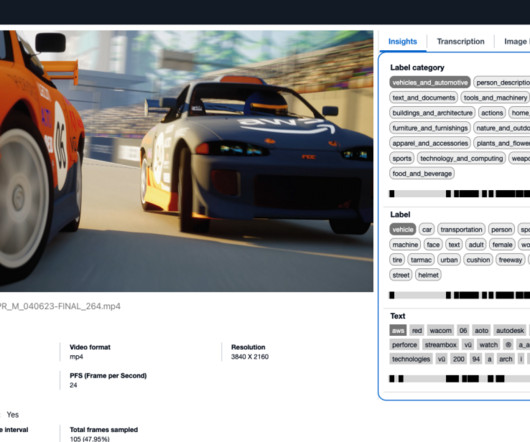
Generative artificial intelligence (AI) has unlocked fresh opportunities for these use cases. In this post, we introduce the Media Analysis and Policy Evaluation solution, which uses AWSAI and generative AI services to provide a framework to streamline video extraction and evaluation processes.
Large language models (LLMs) are making a significant impact in the realm of artificial intelligence (AI). Llama2 by Meta is an example of an LLM offered by AWS. To learn more about Llama 2 on AWS, refer to Llama 2 foundation models from Meta are now available in Amazon SageMaker JumpStart.
For reference, GPT-3, an earlier generation LLM has 175 billion parameters and requires months of non-stop training on a cluster of thousands of accelerated processors. The Carbontracker study estimates that training GPT-3 from scratch may emit up to 85 metric tons of CO2 equivalent, using clusters of specialized hardware accelerators.
CBRE is unlocking the potential of artificial intelligence (AI) to realize value across the entire commercial real estate lifecycle—from guiding investment decisions to managing buildings. The opportunities to unlock value using AI in the commercial real estate lifecycle starts with data at scale.
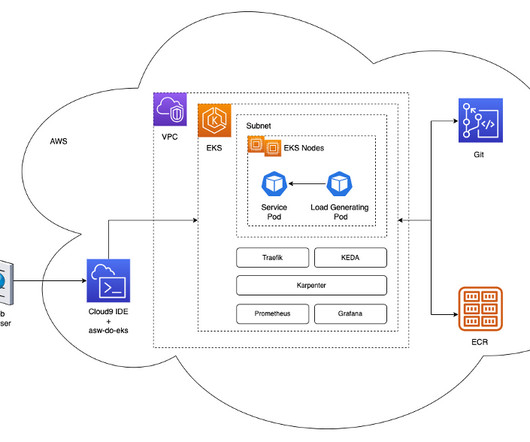
A challenge for DevOps engineers is the additional complexity that comes from using Kubernetes to manage the deployment stage while resorting to other tools (such as the AWS SDK or AWS CloudFormation ) to manage the model building pipeline. kubectl for working with Kubernetes clusters. eksctl for working with EKS clusters.
In this post, we explore how you can use Amazon Q Business , the AWS generative AI-powered assistant, to build a centralized knowledge base for your organization, unifying structured and unstructured datasets from different sources to accelerate decision-making and drive productivity. Choose Create database.
Just recently, generative AI applications have captured everyone’s attention and imagination. We are truly at an exciting inflection point in the widespread adoption of ML, and we believe every customer experience and application will be reinvented with generative AI.
Today, we are announcing that DeepSeek AI s first-generation frontier model, DeepSeek-R1 , is available through Amazon SageMaker JumpStart and Amazon Bedrock Marketplace to deploy for inference. You can now use DeepSeek-R1 to build, experiment, and responsibly scale your generative AI ideas on AWS. 48xlarge for endpoint usage.
In this post, we walk through how to fine-tune Llama 2 on AWS Trainium , a purpose-built accelerator for LLM training, to reduce training times and costs. We review the fine-tuning scripts provided by the AWS Neuron SDK (using NeMo Megatron-LM), the various configurations we used, and the throughput results we saw.
Close collaboration with AWS Trainium has also played a major role in making the Arcee platform extremely performant, not only accelerating model training but also reducing overall costs and enforcing compliance and data integrity in the secure AWS environment. Our cluster consisted of 16 nodes, each equipped with a trn1n.32xlarge
Amazon Web Services is excited to announce the launch of the AWS Neuron Monitor container , an innovative tool designed to enhance the monitoring capabilities of AWS Inferentia and AWS Trainium chips on Amazon Elastic Kubernetes Service (Amazon EKS). The Container Insights dashboard also shows cluster status and alarms.
AWS provides various services catered to time series data that are low code/no code, which both machine learning (ML) and non-ML practitioners can use for building ML solutions. In this post, we seek to separate a time series dataset into individual clusters that exhibit a higher degree of similarity between its data points and reduce noise.
In this post, we’ll summarize training procedure of GPT NeoX on AWS Trainium , a purpose-built machine learning (ML) accelerator optimized for deep learning training. M tokens/$) trained such models with AWS Trainium without losing any model quality. We’ll outline how we cost-effectively (3.2 billion in Pythia. billion in Pythia.
Maximo maintains high-value assets with AI and analytics to optimize performance, extend asset lifecycles and reduce downtime and costs. In this journey, we are seeing an increased interest in migrating and deploying MAS on AWS Cloud. Therefore, Maximo migration and modernization has become even more important for clients.
Tens of thousands of AWS customers use AWS machine learning (ML) services to accelerate their ML development with fully managed infrastructure and tools. The data scientist is responsible for moving the code into SageMaker, either manually or by cloning it from a code repository such as AWS CodeCommit.
The growing need for cost-effective AI models The landscape of generative AI is rapidly evolving. OpenAI launched GPT-4o in May 2024, and Amazon introduced Amazon Nova models at AWS re:Invent in December 2024. The implementation included a provisioned three-node sharded OpenSearch Service cluster.
It is used by businesses across industries for a wide range of applications, including fraud prevention, marketing automation, customer service, artificial intelligence (AI), chatbots, virtual assistants, and recommendations. It provides a large cluster of clusters on a single machine.
With containers, scaling on a cluster becomes much easier. In late 2022, AWS announced the general availability of Amazon EC2 Trn1 instances powered by AWS Trainium accelerators, which are purpose built for high-performance deep learning training. What you get is an ML development environment that is consistent and portable.
Each of these products are infused with artificial intelligence (AI) capabilities to deliver exceptional customer experience. Sprinklr’s specialized AI models streamline data processing, gather valuable insights, and enable workflows and analytics at scale to drive better decision-making and productivity.
This post details how we used Amazon Bedrock to create an AI assistant (Untold Assistant), providing artists with a straightforward way to access our internal resources through a natural language interface integrated directly into their existing Slack workflow. Key AWS services used include: Amazon Bedrock Including Anthropics Claude 3.5
Iambic Therapeutics is a drug discovery startup with a mission to create innovative AI-driven technologies to bring better medicines to cancer patients, faster. Our advanced generative and predictive artificial intelligence (AI) tools enable us to search the vast space of possible drug molecules faster and more effectively.
Building foundation models (FMs) requires building, maintaining, and optimizing large clusters to train models with tens to hundreds of billions of parameters on vast amounts of data. Customers such as Stability AI use SageMaker HyperPod to train their foundation models, including Stable Diffusion. “As
Therefore, ML creates challenges for AWS customers who need to ensure privacy and security across distributed entities without compromising patient outcomes. Solution overview We deploy FedML into multiple EKS clusters integrated with SageMaker for experiment tracking. As always, AWS welcomes your feedback.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content