This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The healthcare industry faces arguably the highest stakes when it comes to datagovernance. For starters, healthcare organizations constantly encounter vast (and ever-increasing) amounts of highly regulated personal data. healthcare, managing the accuracy, quality and integrity of data is the focus of datagovernance.
But with the sheer amount of data continually increasing, how can a business make sense of it? Robust datapipelines. What is a DataPipeline? A datapipeline is a series of processing steps that move data from its source to its destination. The answer?
The recent success of artificial intelligence based large language models has pushed the market to think more ambitiously about how AI could transform many enterprise processes. However, consumers and regulators have also become increasingly concerned with the safety of both their data and the AI models themselves.
At the heart of this transformation is the OMRON Data & Analytics Platform (ODAP), an innovative initiative designed to revolutionize how the company harnesses its data assets. Datagovernance challenges Maintaining consistent datagovernance across different systems is crucial but complex.
Key Takeaways Data quality ensures your data is accurate, complete, reliable, and up to date – powering AI conclusions that reduce costs and increase revenue and compliance. Data observability continuously monitors datapipelines and alerts you to errors and anomalies. stored: where is it located?
Implementing a data fabric architecture is the answer. What is a data fabric? Data fabric is defined by IBM as “an architecture that facilitates the end-to-end integration of various datapipelines and cloud environments through the use of intelligent and automated systems.”
This will become more important as the volume of this data grows in scale. DataGovernanceDatagovernance is the process of managing data to ensure its quality, accuracy, and security. Datagovernance is becoming increasingly important as organizations become more reliant on data.
Moreover, data integration platforms are emerging as crucial orchestrators, simplifying intricate datapipelines and facilitating seamless connectivity across disparate systems and data sources. These platforms provide a unified view of data, enabling businesses to derive insights from diverse datasets efficiently.
That’s why many organizations invest in technology to improve data processes, such as a machine learning datapipeline. However, data needs to be easily accessible, usable, and secure to be useful — yet the opposite is too often the case. These data requirements could be satisfied with a strong datagovernance strategy.
A well-designed data architecture should support business intelligence and analysis, automation, and AI—all of which can help organizations to quickly seize market opportunities, build customer value, drive major efficiencies, and respond to risks such as supply chain disruptions.
But with the sheer amount of data continually increasing, how can a business make sense of it? Robust datapipelines. What is a DataPipeline? A datapipeline is a series of processing steps that move data from its source to its destination. The answer?
But the implementation of AI is only one piece of the puzzle. The tasks behind efficient, responsible AI lifecycle management The continuous application of AI and the ability to benefit from its ongoing use require the persistent management of a dynamic and intricate AI lifecycle—and doing so efficiently and responsibly.
The financial services industry has been in the process of modernizing its datagovernance for more than a decade. But as we inch closer to global economic downturn, the need for top-notch governance has become increasingly urgent. That’s why datapipeline observability is so important.
The emergence of generative AI prompted several prominent companies to restrict its use because of the mishandling of sensitive internal data. According to CNN, some companies imposed internal bans on generative AI tools while they seek to better understand the technology and many have also blocked the use of internal ChatGPT.
Data democratization instead refers to the simplification of all processes related to data, from storage architecture to data management to data security. It also requires an organization-wide datagovernance approach, from adopting new types of employee training to creating new policies for data storage.
Key Takeaways By deploying technologies that can learn and improve over time, companies that embrace AI and machine learning can achieve significantly better results from their data quality initiatives. Here are five data quality best practices which business leaders should focus.
Key Takeaways Leverage AI to achieve digital transformation goals: enhanced efficiency, decision-making, customer experiences, and more. Address common challenges in managing SAP master data by using AI tools to automate SAP processes and ensure data quality. This involves various professionals.
Due to the convergence of events in the data analytics and AI landscape, many organizations are at an inflection point. Furthermore, a global effort to create new data privacy laws, and the increased attention on biases in AI models, has resulted in convoluted business processes for getting data to users.
What is Data Observability? It is the practice of monitoring, tracking, and ensuring data quality, reliability, and performance as it moves through an organization’s datapipelines and systems. Data quality tools help maintain high data quality standards. Tools Used in Data Observability?
Key components include data modelling, warehousing, pipelines, and integration. Effective datagovernance enhances quality and security throughout the data lifecycle. What is Data Engineering? They are crucial in ensuring data is readily available for analysis and reporting. from 2025 to 2030.
In today’s fast-paced business environment, the significance of Data Observability cannot be overstated. Data Observability enables organizations to detect anomalies, troubleshoot issues, and maintain datapipelines effectively. How Are Data Quality and Data Observability Similar—and How Are They Different?
With Azure Machine Learning, data scientists can leverage pre-built models, automate machine learning tasks, and seamlessly integrate with other Azure services, making it an efficient and scalable solution for machine learning projects in the cloud. Might be useful Unlike manual, homegrown, or open-source solutions, neptune.ai
AIOPs refers to the application of artificial intelligence (AI) and machine learning (ML) techniques to enhance and automate various aspects of IT operations (ITOps). However, they differ fundamentally in their purpose and level of specialization in AI and ML environments.
Gen AI is quickly reshaping industries, and the pace of innovation is incredible to witness. While building gen AI application pilots is fairly straightforward, scaling them to production-ready, customer-facing implementations is a novel challenge for enterprises, and especially for the financial services sector.
This trust depends on an understanding of the data that inform risk models: where does it come from, where is it being used, and what are the ripple effects of a change? Moreover, banks must stay in compliance with industry regulations like BCBS 239, which focus on improving banks’ risk data aggregation and risk reporting capabilities.
This is why, when data moves, it’s imperative for organizations to prioritize data discovery. Data discovery is also critical for datagovernance , which, when ineffective, can actually hinder organizational growth. The Cloud Data Migration Challenge. Datapipeline orchestration.
Modern data architectures, like cloud data warehouses and cloud data lakes , empower more people to leverage analytics for insights more efficiently. Access the resources your data applications need — no more, no less. DataPipeline Automation. What Is the Role of DataGovernance in Data Modernization?
At phData, we’re lucky to work with a wide range of customers spanning multiple verticals to solve their toughest data and AI challenges. Designing New DataPipelines Takes a Considerable Amount of Time and Knowledge Designing new ingestion pipelines is a complex undertaking that demands significant time and expertise.
Who should have access to sensitive data? How can my analysts discover where data is located? All of these questions describe a concept known as datagovernance. The Snowflake AIData Cloud has built an entire blanket of features called Horizon, which tackles all of these questions and more.
Summary: This article explores the significance of ETL Data in Data Management. It highlights key components of the ETL process, best practices for efficiency, and future trends like AI integration and real-time processing, ensuring organisations can leverage their data effectively for strategic decision-making.
In particular, its progress depends on the availability of related technologies that make the handling of huge volumes of data possible. These technologies include the following: Datagovernance and management — It is crucial to have a solid data management system and governance practices to ensure data accuracy, consistency, and security.
Key Takeaways: Data integration is vital for real-time data delivery across diverse cloud models and applications, and for leveraging technologies like generative AI. It synthesizes all the metadata around your organization’s data assets and arranges the information into a simple, easy-to-understand format.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create datapipelines, ETL processes, and databases to facilitate smooth data flow and storage. Read more to know. Cloud Platforms: AWS, Azure, Google Cloud, etc.
And because data assets within the catalog have quality scores and social recommendations, Alex has greater trust and confidence in the data she’s using for her decision-making recommendations. This is especially helpful when handling massive amounts of big data. Protected and compliant data.
Over time, we called the “thing” a data catalog , blending the Google-style, AI/ML-based relevancy with more Yahoo-style manual curation and wikis. Thus was born the data catalog. In our early days, “people” largely meant data analysts and business analysts. After that came datagovernance , privacy, and compliance staff.
Data as the foundation of what the business does is great – but how do you support that? The Snowflake AIData Cloud is the platform that will support that and much more! It is the ideal single source of truth to support analytics and drive data adoption – the foundation of the data culture!
Additionally, Alation and Paxata announced the new data exploration capabilities of Paxata in the Alation Data Catalog, where users can find trusted data assets and, with a single click, work with their data in Paxata’s Self-Service Data Prep Application. 3) Data professionals come in all shapes and forms.
This May, were heading to Boston for ODSC East 2025, where data scientists, AI engineers, and industry leaders will gather to explore the latest advancements in AI, machine learning, and data engineering. Were also going to start another AI Bootcamp cohort in April if you want to experience everything live.
Though just about every industry imaginable utilizes the skills of a data-focused professional, each has its own challenges, needs, and desired outcomes. This is why you’ll often find that there are jobs in AI specific to an industry, or desired outcome when it comes to data. Well then, you’re in luck.
Let’s demystify this using the following personas and a real-world analogy: Data and ML engineers (owners and producers) – They lay the groundwork by feeding data into the feature store Data scientists (consumers) – They extract and utilize this data to craft their models Data engineers serve as architects sketching the initial blueprint.
This article will discuss managing unstructured data for AI and ML projects. You will learn the following: Why unstructured data management is necessary for AI and ML projects. How to properly manage unstructured data. The different tools used in unstructured data management. What is Unstructured Data?
A broken datapipeline might bring operational systems to a halt, or it could cause executive dashboards to fail, reporting inaccurate KPIs to top management. Is your datagovernance structure up to the task? Read What Is Data Observability? Complexity leads to risk.
This is the practice of creating, updating and consistently enforcing the processes, rules and standards that prevent errors, data loss, data corruption, mishandling of sensitive or regulated data, and data breaches. Learn more about designing the right data architecture to elevate your data quality here.
Snowflake Cortex is a suite of pre-built machine learning models and AI capabilities designed to accelerate the deployment of AI-driven solutions within the Snowflake ecosystem. Cortex ML functions are aimed at Predictive AI use cases, such as anomaly detection, forecasting , customer segmentation , and predictive analytics.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
























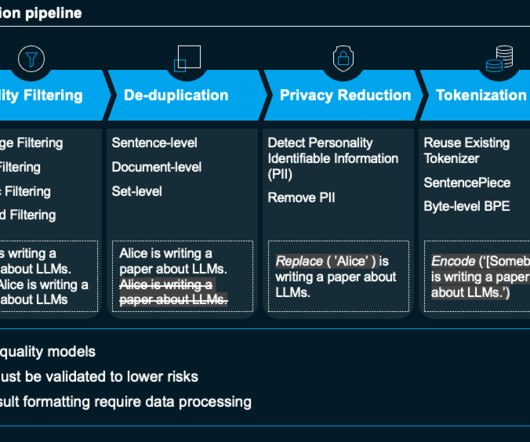











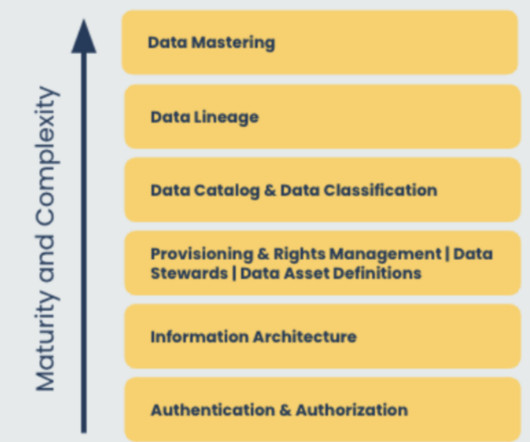














Let's personalize your content