This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
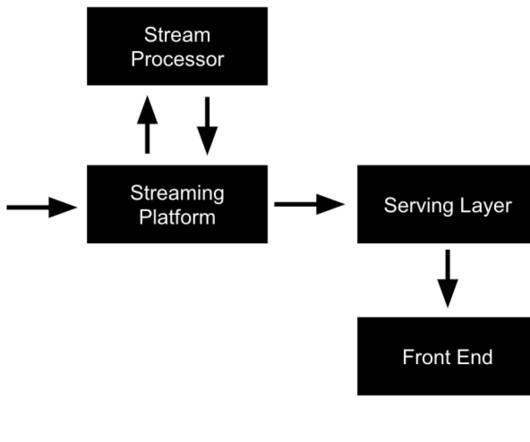
Be sure to check out his talk, “ Apache Kafka for Real-Time Machine Learning Without a DataLake ,” there! The combination of data streaming and machine learning (ML) enables you to build one scalable, reliable, but also simple infrastructure for all machine learning tasks using the Apache Kafka ecosystem.
For example, in the bank marketing use case, the management account would be responsible for setting up the organizational structure for the bank’s data and analytics teams, provisioning separate accounts for data governance, datalakes, and data science teams, and maintaining compliance with relevant financial regulations.
Dremio, the unified lakehouse platform for self-service analytics and AI, announced a breakthrough in datalake analytics performance capabilities, extending its leadership in self-optimizing, autonomous Iceberg data management.
Artificial Intelligence (AI) is all the rage, and rightly so. By now most of us have experienced how Gen AI and the LLMs (large language models) that fuel it are primed to transform the way we create, research, collaborate, engage, and much more. Can AIs responses be trusted? A datalake! Can it do it without bias?
While databases were the traditional way to store large amounts of data, a new storage method has developed that can store even more significant and varied amounts of data. These are called datalakes. What Are DataLakes? In many cases, this could mean using multiple security programs and platforms.
7 Best Platforms to Practice SQL • Explainable AI: 10 Python Libraries for Demystifying Your Model's Decisions • ChatGPT: Everything You Need to Know • DataLakes and SQL: A Match Made in Data Heaven • Google Data Analytics Certification Review for 2023
Recently we’ve seen lots of posts about a variety of different file formats for datalakes. There’s Delta Lake, Hudi, Iceberg, and QBeast, to name a few. It can be tough to keep track of all these datalake formats — let alone figure out why (or if!) And I’m curious to see if you’ll agree.
In the ever-evolving world of big data, managing vast amounts of information efficiently has become a critical challenge for businesses across the globe. As datalakes gain prominence as a preferred solution for storing and processing enormous datasets, the need for effective data version control mechanisms becomes increasingly evident.
MinIO, a provider of high-performance object storage for AI, announced several upcoming enhancements to its AIStor product at NVIDIA GTC. These updates are designed to deepen MinIO’s support for the NVIDIA AI ecosystem and improve the efficiency and utilization of AI infrastructure. It will increase CPU efficiency.
Auch bei Process Mining tut sich gerade viel, Machine Learning hält Einzug ins Process Mining, Prozesse können immer granularer analysiert werden, auch unstrukturierte Daten können unter Einsatz von AI mit in die Analyse einbezogen werden usw. Was gerade zum Trend wird, ist der Aufbau eines Data Lakehouses.
Enterprises migrating on-prem data environments to the cloud in pursuit of more robust, flexible, and integrated analytics and AI/ML capabilities are fueling a surge in cloud datalake implementations. The post How to Ensure Your New Cloud DataLake Is Secure appeared first on DATAVERSITY.
It has been ten years since Pentaho Chief Technology Officer James Dixon coined the term “datalake.” While data warehouse (DWH) systems have had longer existence and recognition, the data industry has embraced the more […]. The post A Bridge Between DataLakes and Data Warehouses appeared first on DATAVERSITY.
Unified data storage : Fabric’s centralized datalake, Microsoft OneLake, eliminates data silos and provides a unified storage system, simplifying data access and retrieval. OneLake is designed to store a single copy of data in a unified location, leveraging the open-source Apache Parquet format.
Data Swamp vs DataLake. When you imagine a lake, it’s likely an idyllic image of a tree-ringed body of reflective water amid singing birds and dabbling ducks. I’ll take the lake, thank you very much. Many organizations have built a datalake to solve their data storage, access, and utilization challenges.
Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. Data engineers use data warehouses, datalakes, and analytics tools to load, transform, clean, and aggregate data.
To make your data management processes easier, here’s a primer on datalakes, and our picks for a few datalake vendors worth considering. What is a datalake? First, a datalake is a centralized repository that allows users or an organization to store and analyze large volumes of data.
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructured data. What is a DataLake? Consistency of data throughout the datalake.
Discover the nuanced dissimilarities between DataLakes and Data Warehouses. Data management in the digital age has become a crucial aspect of businesses, and two prominent concepts in this realm are DataLakes and Data Warehouses. It acts as a repository for storing all the data.
We have solicited insights from experts at industry-leading companies, asking: "What were the main AI, Data Science, Machine Learning Developments in 2021 and what key trends do you expect in 2022?" Read their opinions here.
The data being talked about is useful for businesses to draw insights, formulate strategies, and understand trends and customer behavior, among others. […]. The post Maximize the ROI of Your Enterprise DataLake appeared first on DATAVERSITY.
Data management problems can also lead to data silos; disparate collections of databases that don’t communicate with each other, leading to flawed analysis based on incomplete or incorrect datasets. One way to address this is to implement a datalake: a large and complex database of diverse datasets all stored in their original format.
Real-Time ML with Spark and SBERT, AI Coding Assistants, DataLake Vendors, and ODSC East Highlights Getting Up to Speed on Real-Time Machine Learning with Spark and SBERT Learn more about real-time machine learning by using this approach that uses Apache Spark and SBERT. Is an AI Coding Assistant Right For You?
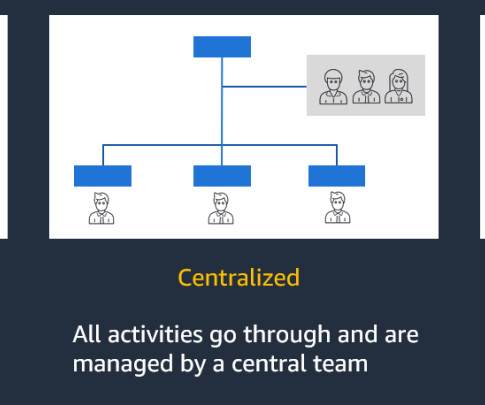
Generative AI can revolutionize organizations by enabling the creation of innovative applications that offer enhanced customer and employee experiences. In this post, we evaluate different generative AI operating model architectures that could be adopted.
As one of the largest AWS customers, Twilio engages with data, artificial intelligence (AI), and machine learning (ML) services to run their daily workloads. Data is the foundational layer for all generative AI and ML applications. The following diagram illustrates the solution architecture.
Author(s): Towards AI Editorial Team Originally published on Towards AI. Good morning, AI enthusiasts! This week, I’m super excited to announce that we are finally releasing our book, ‘Building AI for Production; Enhancing LLM Abilities and Reliability with Fine-Tuning and RAG,’ where we gathered all our learnings.
He is focused on Big Data, DataLakes, Streaming and batch Analytics services and generative AI technologies. He works with strategic customers who are using AI/ML to solve complex business problems. Varun Mehta is a Sr. Solutions Architect at AWS. Outside of work, he loves to spend time with his wife and kids
Domain experts, for example, feel they are still overly reliant on core IT to access the data assets they need to make effective business decisions. In all of these conversations there is a sense of inertia: Data warehouses and datalakes feel cumbersome and data pipelines just aren't agile enough.
Visualization for Clustering Methods Clustering methods are a big part of data science, and here’s a primer on how you can visualize them. Lemley on Generative AI and the Law Here’s what Mark A. Lemley, law Professor at Stanford, thinks about legal issues that arise from generative AI, the memorization problem, and more.
The rise of large language models (LLMs) and foundation models (FMs) has revolutionized the field of natural language processing (NLP) and artificial intelligence (AI). These powerful models, trained on vast amounts of data, can generate human-like text, answer questions, and even engage in creative writing tasks.
By some estimates, unstructured data can make up to 80–90% of all new enterprise data and is growing many times faster than structured data. After decades of digitizing everything in your enterprise, you may have an enormous amount of data, but with dormant value. These services write the output to a datalake.
An inaccurate AI prediction in a marketing campaign is a minor nuisance, but an inaccurate AI prediction on a manufacturing shopfloor can be fatal. Or we create a datalake, which quickly degenerates to a data swamp. Summarization Summarization remains the top use case for generative AI (gen AI) technology.
Building a Business with a Real-Time Analytics Stack, Streaming ML Without a DataLake, and Google’s PaLM 2 Building a Pizza Delivery Service with a Real-Time Analytics Stack The best businesses react quickly and with informed decisions. Here’s a use case of how you can use a real-time analytics stack to build a pizza delivery service.
Artificial intelligence (AI) is now at the forefront of how enterprises work with data to help reinvent operations, improve customer experiences, and maintain a competitive advantage. It’s no longer a nice-to-have, but an integral part of a successful data strategy. Why does AI need an open data lakehouse architecture?
These platforms provide data engineers with the flexibility to develop and deploy IoT applications efficiently. DataLakes for Centralized Storage Datalakes serve as centralized repositories for storing raw and processed IoT data.
Earlier this year, we published the first in a series of posts about how AWS is transforming our seller and customer journeys using generative AI. Using our AI assistant built on Amazon Q, team members are saving hours of time each week. This time adds up individually, but also collectively at the team and organizational level.
We stand on the frontier of an AI revolution. Over the past decade, deep learning arose from a seismic collision of data availability and sheer compute power, enabling a host of impressive AI capabilities. It sounds like a joke, but it’s not, as anyone who has tried to solve business problems with AI may know.
AI-driven revenue optimization The new system enables hoteliers to manage pricing dynamically , making data-driven adjustments across rooms, event spaces, and F&B outlets. The AI-powered automation provides forecasting, strategic planning assistance, and customizable rate management to improve overall profitability.
Recent developments in generative AI models have further sped up the need of ML adoption across industries. However, implementing security, data privacy, and governance controls are still key challenges faced by customers when implementing ML workloads at scale.
In todays fast-paced data-driven world, open-source solutions are transforming industries by providing flexible, scalable, and community-driven innovations. Whether youre a data scientist, engineer, or AI researcher, tapping into open-source technologies can accelerate your work while fostering collaboration.
To accomplish this, eSentire built AI Investigator, a natural language query tool for their customers to access security platform data by using AWS generative artificial intelligence (AI) capabilities. This helps customers quickly and seamlessly explore their security data and accelerate internal investigations.
Every tech evangelist and their grandma was gushing about generative AI, hailing it as the dawn of a new creative epoch. The “wow” factor has waned, replaced by a nagging question: Is AI creative? Is AI creative? As AI matures, its ability to process information, adapt, and learn will exponentially increase.
This post presents a solution that uses a generative artificial intelligence (AI) to standardize air quality data from low-cost sensors in Africa, specifically addressing the air quality data integration problem of low-cost sensors. Qiong (Jo) Zhang , PhD, is a Senior Partner Solutions Architect at AWS, specializing in AI/ML.
Data scientists and ML engineers require capable tooling and sufficient compute for their work. To pave the way for the growth of AI, BMW Group needed to make a leap regarding scalability and elasticity while reducing operational overhead, software licensing, and hardware management.
One groundbreaking technology that has emerged as a game-changer is asset performance management (APM) artificial intelligence (AI). However, embarking on the journey of implementing artificial intelligence (AI) in your asset performance management strategy can be both exciting and daunting.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content