This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
For example, in the bank marketing use case, the management account would be responsible for setting up the organizational structure for the bank’s data and analytics teams, provisioning separate accounts for data governance, datalakes, and data science teams, and maintaining compliance with relevant financial regulations.
Unified data storage : Fabric’s centralized datalake, Microsoft OneLake, eliminates datasilos and provides a unified storage system, simplifying data access and retrieval. OneLake is designed to store a single copy of data in a unified location, leveraging the open-source Apache Parquet format.
At the heart of this transformation is the OMRON Data & Analytics Platform (ODAP), an innovative initiative designed to revolutionize how the company harnesses its data assets. The robust security features provided by Amazon S3, including encryption and durability, were used to provide data protection.
To make your data management processes easier, here’s a primer on datalakes, and our picks for a few datalake vendors worth considering. What is a datalake? First, a datalake is a centralized repository that allows users or an organization to store and analyze large volumes of data.
Data management problems can also lead to datasilos; disparate collections of databases that don’t communicate with each other, leading to flawed analysis based on incomplete or incorrect datasets. The datalake can then refine, enrich, index, and analyze that data. and various countries in Europe.
Discover the nuanced dissimilarities between DataLakes and Data Warehouses. Data management in the digital age has become a crucial aspect of businesses, and two prominent concepts in this realm are DataLakes and Data Warehouses. It acts as a repository for storing all the data.
There’s no debate that the volume and variety of data is exploding and that the associated costs are rising rapidly. The proliferation of datasilos also inhibits the unification and enrichment of data which is essential to unlocking the new insights. Enter the open data lakehouse.
Businesses face significant hurdles when preparing data for artificial intelligence (AI) applications. The existence of datasilos and duplication, alongside apprehensions regarding data quality, presents a multifaceted environment for organizations to manage.
Sheer volume of data makes automation with Artificial Intelligence & Machine Learning (AI & ML) an imperative. Menninger outlines how modern data governance practices may deploy a basic repository of data; this can help with some level of automation. Datalakes are repositories where much of this data winds up.
By 2026, over 80% of enterprises will deploy AI APIs or generative AI applications. AI models and the data on which they’re trained and fine-tuned can elevate applications from generic to impactful, offering tangible value to customers and businesses. Data is exploding, both in volume and in variety.
What if the problem isn’t in the volume of data, but rather where it is located—and how hard it is to gather? Nine out of 10 IT leaders report that these disconnects, or datasilos, create significant business challenges.* Increase understanding of data sets on hand for data integration or data analysis.
In another decade, the internet and mobile started the generate data of unforeseen volume, variety and velocity. It required a different data platform solution. Hence, DataLake emerged, which handles unstructured and structured data with huge volume. Data fabric and data mesh as concepts have overlaps.
What if the problem isn’t in the volume of data, but rather where it is located—and how hard it is to gather? Nine out of 10 IT leaders report that these disconnects, or datasilos, create significant business challenges.* Increase understanding of data sets on hand for data integration or data analysis.
Key Takeaways Data Fabric is a modern data architecture that facilitates seamless data access, sharing, and management across an organization. Data management recommendations and data products emerge dynamically from the fabric through automation, activation, and AI/ML analysis of metadata.
The first generation of data architectures represented by enterprise data warehouse and business intelligence platforms were characterized by thousands of ETL jobs, tables, and reports that only a small group of specialized data engineers understood, resulting in an under-realized positive impact on the business.
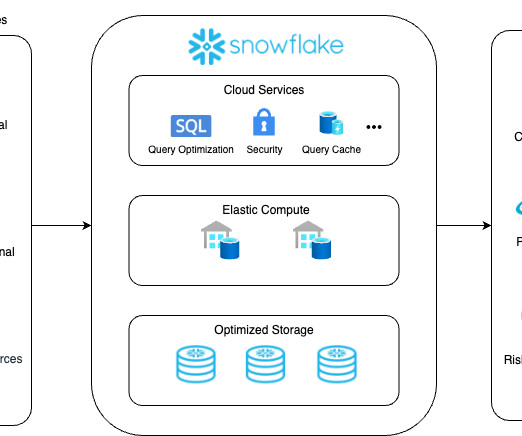
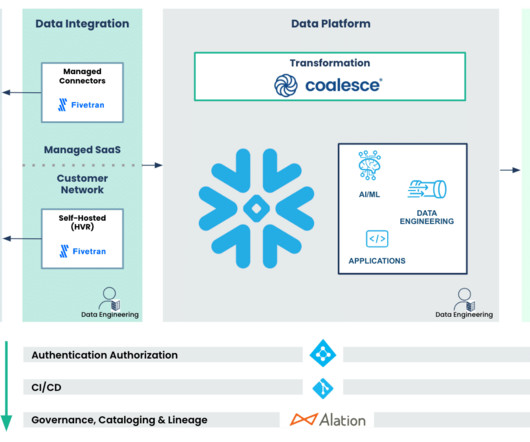
By leveraging cloud-based data platforms such as Snowflake Data Cloud , these commercial banks can aggregate and curate their data to understand individual customer preferences and offer relevant and personalized products.
Summary: Lean data management enhances agility by streamlining data processes, reducing waste, and ensuring accuracy and relevance. By leveraging AI and automation, organisations optimise operations and maintain competitive advantage in fast-changing markets. It enables faster decisions, better collaboration, and scalability.
While this industry has used data and analytics for a long time, many large travel organizations still struggle with datasilos , which prevent them from gaining the most value from their data. What is big data in the travel and tourism industry?
Difficulty in moving non-SAP data into SAP for analytics which encourages datasilos and shadow IT practices as business users search for ways to extract the data (which has data governance implications).
ELT, which stands for Extract, Load, Transform, is a data integration process that shifts the sequence of operations seen in ETL. In ELT, data is extracted from its source and then loaded into a storage system, such as a datalake or data warehouse , before being transformed. Conversely, ELT flips this sequence.
Understanding Data Integration in Data Mining Data integration is the process of combining data from different sources. Thus creating a consolidated view of the data while eliminating datasilos. It ensures that the integrated data is available for analysis and reporting.
This functionality provides access to data by storing it in an open format, increasing flexibility for data exploration and ML modeling used by data scientists, facilitating governed data use of unstructured data, improving collaboration, and reducing datasilos with simplified datalake integration.
In that sense, data modernization is synonymous with cloud migration. Modern data architectures, like cloud data warehouses and cloud datalakes , empower more people to leverage analytics for insights more efficiently. So what’s the appeal of this new infrastructure? Subscribe to Alation's Blog.
With machine learning (ML) and artificial intelligence (AI) applications becoming more business-critical, organizations are in the race to advance their AI/ML capabilities. To realize the full potential of AI/ML, having the right underlying machine learning platform is a prerequisite.
What Are the Top Data Challenges to Analytics? The proliferation of data sources means there is an increase in data volume that must be analyzed. Large volumes of data have led to the development of datalakes , data warehouses, and data management systems.
In the data-driven world we live in today, the field of analytics has become increasingly important to remain competitive in business. In fact, a study by McKinsey Global Institute shows that data-driven organizations are 23 times more likely to outperform competitors in customer acquisition and nine times […].
Both persistent staging and datalakes involve storing large amounts of raw data. But persistent staging is typically more structured and integrated into your overall customer data pipeline. You might choose a cloud data warehouse like the Snowflake AIData Cloud or BigQuery. New user sign-up?
Currently, there are 22 AWS data center regions where 100% of the electricity consumed is matched by renewable energy sources. Additionally, you can use Amazon Q , a generative AI-powered assistant, to surface and generate potential amendments to avoid expensive costs associated with protocol revisions.
Amazon Q Business is a generative AI-powered assistant that can answer questions, provide summaries, generate content, and securely complete tasks based on data and information in your enterprise systems. He has helped Fortune 500 companies with their AIML/Generative AI needs. and overall product accuracy optimizations.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































Let's personalize your content