This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Be sure to check out his talk, “ Apache Kafka for Real-Time Machine Learning Without a DataLake ,” there! The combination of data streaming and machine learning (ML) enables you to build one scalable, reliable, but also simple infrastructure for all machine learning tasks using the Apache Kafka ecosystem.
Artificial Intelligence (AI) is all the rage, and rightly so. By now most of us have experienced how Gen AI and the LLMs (large language models) that fuel it are primed to transform the way we create, research, collaborate, engage, and much more. Can AIs responses be trusted? A datalake! Can it do it without bias?
Dremio, the unified lakehouse platform for self-service analytics and AI, announced a breakthrough in datalake analytics performance capabilities, extending its leadership in self-optimizing, autonomous Iceberg data management.
While databases were the traditional way to store large amounts of data, a new storage method has developed that can store even more significant and varied amounts of data. These are called datalakes. What Are DataLakes? However, even digital information has to be stored somewhere.
In the ever-evolving world of big data, managing vast amounts of information efficiently has become a critical challenge for businesses across the globe. As datalakes gain prominence as a preferred solution for storing and processing enormous datasets, the need for effective data version control mechanisms becomes increasingly evident.
Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. Data engineers use data warehouses, datalakes, and analytics tools to load, transform, clean, and aggregate data.
Businesses face significant hurdles when preparing data for artificial intelligence (AI) applications. The existence of data silos and duplication, alongside apprehensions regarding data quality, presents a multifaceted environment for organizations to manage.
We spoke with Dr. Swami Sivasubramanian, Vice President of Data and AI, shortly after AWS re:Invent 2024 to hear his impressionsand to get insights on how the latest AWS innovations help meet the real-world needs of customers as they build and scale transformative generative AI applications. Canva uses AWS to power 1.2
Unified data storage : Fabric’s centralized datalake, Microsoft OneLake, eliminates data silos and provides a unified storage system, simplifying data access and retrieval. OneLake is designed to store a single copy of data in a unified location, leveraging the open-source Apache Parquet format.
Earlier this year, we published the first in a series of posts about how AWS is transforming our seller and customer journeys using generative AI. Using our AI assistant built on Amazon Q, team members are saving hours of time each week. This time adds up individually, but also collectively at the team and organizational level.
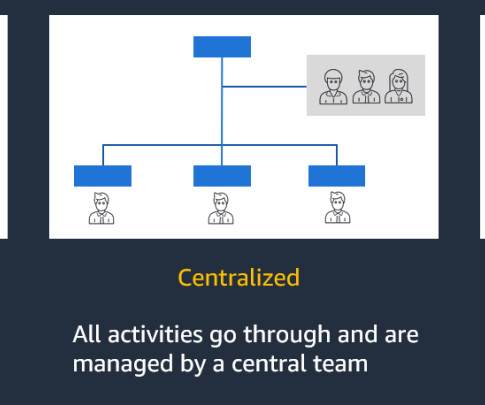
Generative AI can revolutionize organizations by enabling the creation of innovative applications that offer enhanced customer and employee experiences. In this post, we evaluate different generative AI operating model architectures that could be adopted.
Discover the nuanced dissimilarities between DataLakes and Data Warehouses. Data management in the digital age has become a crucial aspect of businesses, and two prominent concepts in this realm are DataLakes and Data Warehouses. It acts as a repository for storing all the data.
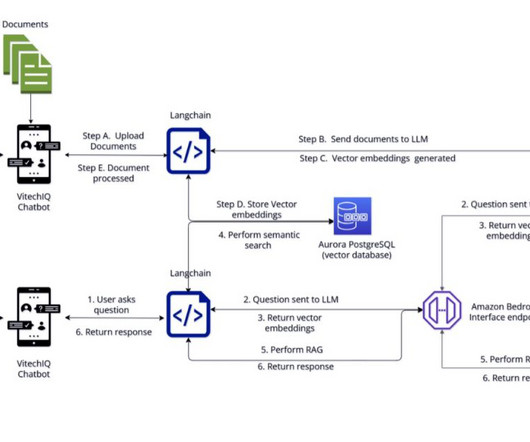
As one of the largest AWS customers, Twilio engages with data, artificial intelligence (AI), and machine learning (ML) services to run their daily workloads. Data is the foundational layer for all generative AI and ML applications. The following diagram illustrates the solution architecture.
The following question requires complex industry knowledge-based analysis of data from multiple columns in the ETF database. He is focused on Big Data, DataLakes, Streaming and batch Analytics services and generative AI technologies. Varun Mehta is a Sr. Solutions Architect at AWS.
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructured data. What is a DataLake? Consistency of data throughout the datalake.
By some estimates, unstructured data can make up to 80–90% of all new enterprise data and is growing many times faster than structured data. After decades of digitizing everything in your enterprise, you may have an enormous amount of data, but with dormant value. These services write the output to a datalake.
Generative AI has opened up a lot of potential in the field of AI. One such area that is evolving is using natural language processing (NLP) to unlock new opportunities for accessing data through intuitive SQL queries. The primary goal is to automatically generate SQL queries from natural language text.
In todays fast-paced data-driven world, open-source solutions are transforming industries by providing flexible, scalable, and community-driven innovations. Whether youre a data scientist, engineer, or AI researcher, tapping into open-source technologies can accelerate your work while fostering collaboration.
Data management problems can also lead to data silos; disparate collections of databases that don’t communicate with each other, leading to flawed analysis based on incomplete or incorrect datasets. The datalake can then refine, enrich, index, and analyze that data. and various countries in Europe.
Generative AI models have the potential to revolutionize enterprise operations, but businesses must carefully consider how to harness their power while overcoming challenges such as safeguarding data and ensuring the quality of AI-generated content. Set up the database access and network access.
Data Collection and Integration Data engineers are responsible for designing robust data collection systems that gather information from various IoT devices and sensors. This data is then integrated into centralized databases for further processing and analysis.
Be sure to check out his talk, “ What is a Time-series Database and Why do I Need One? Most data scientists are familiar with the concept of time series data and work with it often. The time series database (TSDB) , however, is still an underutilized tool in the data science community. at ODSC West 2023.
Amazon Bedrock is a fully managed service that makes FMs from leading AI startups and Amazon available via an API, so one can choose from a wide range of FMs to find the model that is best suited for their use case. Prompt engineering Prompt engineering is crucial for the knowledge retrieval system.
Amazon Redshift powers data-driven decisions for tens of thousands of customers every day with a fully managed, AI-powered cloud data warehouse, delivering the best price-performance for your analytics workloads. Learn more about the AWS zero-ETL future with newly launched AWS databases integrations with Amazon Redshift.
Data storage databases. Your SaaS company can store and protect any amount of data using Amazon Simple Storage Service (S3), which is ideal for datalakes, cloud-native applications, and mobile apps. Artificial intelligence (AI). Well, let’s find out. Messages and notification. Cost-effective.
Data warehouse is the base architecture for artificial intelligence and machine learning (AI/ML) solutions as well. Benefits of new data warehousing technology Everything is data, regardless of whether it’s structured, semi-structured, or unstructured.
Data scientists and ML engineers require capable tooling and sufficient compute for their work. To pave the way for the growth of AI, BMW Group needed to make a leap regarding scalability and elasticity while reducing operational overhead, software licensing, and hardware management.
The Future of the Single Source of Truth is an Open DataLake Organizations that strive for high-performance data systems are increasingly turning towards the ELT (Extract, Load, Transform) model using an open datalake. To DIY you need to: host an API, build a UI, and run or rent a database.
This post presents a solution that uses a generative artificial intelligence (AI) to standardize air quality data from low-cost sensors in Africa, specifically addressing the air quality data integration problem of low-cost sensors. This allows for data to be aggregated for further manufacturer-agnostic analysis.
Nowadays, the majority of our customers is excited about large language models (LLMs) and thinking how generative AI could transform their business. In this post, we discuss how to operationalize generative AI applications using MLOps principles leading to foundation model operations (FMOps).
To accomplish this, eSentire built AI Investigator, a natural language query tool for their customers to access security platform data by using AWS generative artificial intelligence (AI) capabilities. This helps customers quickly and seamlessly explore their security data and accelerate internal investigations.
Adding new data to the storage requires pulling the existing data, then calculating the new hash before pushing back the whole data. DVC lacks crucial relational database features, making it an unsuitable choice for those familiar with relational databases. So, Dolt’s integration with Git makes it easier to learn.
Organizations can maximize the value of their modern data architecture with generative AI solutions while innovating continuously. The natural language capabilities allow non-technical users to query data through conversational English rather than complex SQL. The following diagram illustrates the architecture.
These datasets are often a mix of numerical and text data, at times structured, unstructured, or semi-structured. needed to address some of these challenges in one of their many AI use cases built on AWS. The generated query is then run against the database to fetch the relevant context.
Our goal was to improve the user experience of an existing application used to explore the counters and insights data. The data is stored in a datalake and retrieved by SQL using Amazon Athena. The problem Making data accessible to users through applications has always been a challenge.
This characteristic reflects the growing sources and types of data collected over time. Variety Variety delineates the different data types involved, encompassing structured data like databases, unstructured data such as text and multimedia content, and semi-structured data found in logs and sensor data.
Comprehensive data privacy laws in at least four states are going into effect this year, and more than a dozen states have similar legislation in the works. Database management may become increasingly complex as organizations must account for more of these laws.
Amazon DataZone is a data management service that makes it quick and convenient to catalog, discover, share, and govern data stored in AWS, on-premises, and third-party sources. The sample dataset Upload the dataset to Amazon S3 and crawl the data to create an AWS Glue database and tables.
Now all you need is some guidance on generative AI and machine learning (ML) sessions to attend at this twelfth edition of re:Invent. And although generative AI has appeared in previous events, this year we’re taking it to the next level. And although our track focuses on generative AI, many other tracks have related sessions.
Through a partnership spanning more than 25 years, IBM has helped the Augusta National Golf Club capture, analyze, distribute and use data to bring fans closer to the action, culminating in the AI-powered Masters digital experience and mobile app.
At AWS, we are transforming our seller and customer journeys by using generative artificial intelligence (AI) across the sales lifecycle. Prospecting, opportunity progression, and customer engagement present exciting opportunities to utilize generative AI, using historical data, to drive efficiency and effectiveness.
Online analytical processing (OLAP) database systems and artificial intelligence (AI) complement each other and can help enhance data analysis and decision-making when used in tandem. As AI techniques continue to evolve, innovative applications in the OLAP domain are anticipated.
A point of data entry in a given pipeline. Examples of an origin include storage systems like datalakes, data warehouses and data sources that include IoT devices, transaction processing applications, APIs or social media. The final point to which the data has to be eventually transferred is a destination.
There are many well-known libraries and platforms for data analysis such as Pandas and Tableau, in addition to analytical databases like ClickHouse, MariaDB, Apache Druid, Apache Pinot, Google BigQuery, Amazon RedShift, etc. With Great Expectations , data teams can express what they “expect” from their data using simple assertions.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content