This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This post is part of an ongoing series about governing the machine learning (ML) lifecycle at scale. This post dives deep into how to set up data governance at scale using Amazon DataZone for the data mesh. The data mesh is a modern approach to data management that decentralizes data ownership and treats data as a product.
Be sure to check out his talk, “ Apache Kafka for Real-Time Machine Learning Without a DataLake ,” there! The combination of data streaming and machine learning (ML) enables you to build one scalable, reliable, but also simple infrastructure for all machine learning tasks using the Apache Kafka ecosystem.
Customers of every size and industry are innovating on AWS by infusing machine learning (ML) into their products and services. Recent developments in generative AI models have further sped up the need of ML adoption across industries.
By some estimates, unstructured data can make up to 80–90% of all new enterprise data and is growing many times faster than structured data. After decades of digitizing everything in your enterprise, you may have an enormous amount of data, but with dormant value. These services write the output to a datalake.
The agency wanted to use AI [artificial intelligence] and ML to automate document digitization, and it also needed help understanding each document it digitizes, says Duan. The demand for modernization is growing, and Precise can help government agencies adopt AI/ML technologies.
With that, the need for data scientists and machine learning (ML) engineers has grown significantly. Data scientists and ML engineers require capable tooling and sufficient compute for their work. Data scientists and ML engineers require capable tooling and sufficient compute for their work.
MinIO, a provider of high-performance object storage for AI, announced several upcoming enhancements to its AIStor product at NVIDIA GTC. These updates are designed to deepen MinIO’s support for the NVIDIA AI ecosystem and improve the efficiency and utilization of AI infrastructure. It will increase CPU efficiency.
One groundbreaking technology that has emerged as a game-changer is asset performance management (APM) artificial intelligence (AI). However, embarking on the journey of implementing artificial intelligence (AI) in your asset performance management strategy can be both exciting and daunting.
Now all you need is some guidance on generative AI and machine learning (ML) sessions to attend at this twelfth edition of re:Invent. And although generative AI has appeared in previous events, this year we’re taking it to the next level. And although our track focuses on generative AI, many other tracks have related sessions.
LLM companies are businesses that specialize in developing and deploying Large Language Models (LLMs) and advanced machine learning (ML) models. Open AI In the rapidly evolving field of artificial intelligence, OpenAI stands out as a leading force in the LLM world. What are LLM Companies?
Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. Data engineers use data warehouses, datalakes, and analytics tools to load, transform, clean, and aggregate data.
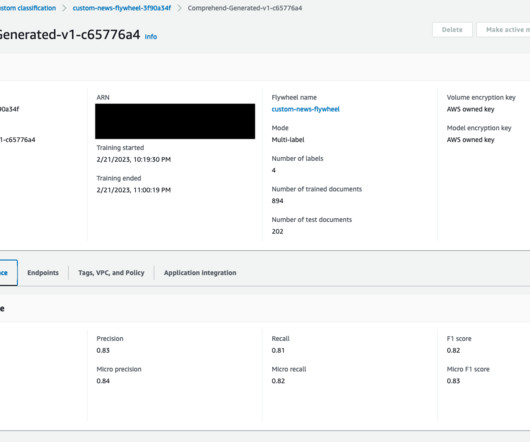
This post presents a solution that uses a workflow and AWS AI and machine learning (ML) services to provide actionable insights based on those transcripts. We use multiple AWS AI/ML services, such as Contact Lens for Amazon Connect and Amazon SageMaker , and utilize a combined architecture. Validation set 11 1500 0.82
Enterprises migrating on-prem data environments to the cloud in pursuit of more robust, flexible, and integrated analytics and AI/ML capabilities are fueling a surge in cloud datalake implementations. The post How to Ensure Your New Cloud DataLake Is Secure appeared first on DATAVERSITY.
Starting today, you can interactively prepare large datasets, create end-to-end data flows, and invoke automated machine learning (AutoML) experiments on petabytes of data—a substantial leap from the previous 5 GB limit. Organizations often struggle to extract meaningful insights and value from their ever-growing volume of data.
Amazon Redshift is the most popular cloud data warehouse that is used by tens of thousands of customers to analyze exabytes of data every day. SageMaker Studio is the first fully integrated development environment (IDE) for ML. The next step is to build ML models using features selected from one or multiple feature groups.
Real-Time ML with Spark and SBERT, AI Coding Assistants, DataLake Vendors, and ODSC East Highlights Getting Up to Speed on Real-Time Machine Learning with Spark and SBERT Learn more about real-time machine learning by using this approach that uses Apache Spark and SBERT. Is an AI Coding Assistant Right For You?
Generative AI can revolutionize organizations by enabling the creation of innovative applications that offer enhanced customer and employee experiences. In this post, we evaluate different generative AI operating model architectures that could be adopted.
In 1992, Thomson Reuters (TR) released its first AI legal research service, WIN (Westlaw Is Natural), an innovation at the time, as most search engines only supported Boolean terms and connectors. With this tremendous increase of AI services, the next milestone for TR was to streamline innovation, and facilitate collaboration.
He is actively working on projects in the ML space and has presented at numerous conferences including Strata and GlueCon. He is focused on Big Data, DataLakes, Streaming and batch Analytics services and generative AI technologies. Arghya Banerjee is a Sr. Varun Mehta is a Sr. Solutions Architect at AWS.
Nowadays, the majority of our customers is excited about large language models (LLMs) and thinking how generative AI could transform their business. In this post, we discuss how to operationalize generative AI applications using MLOps principles leading to foundation model operations (FMOps).
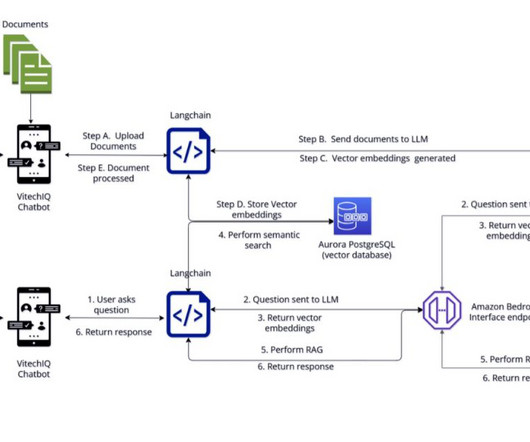
As one of the largest AWS customers, Twilio engages with data, artificial intelligence (AI), and machine learning (ML) services to run their daily workloads. Data is the foundational layer for all generative AI and ML applications. The following diagram illustrates the solution architecture.
To make your data management processes easier, here’s a primer on datalakes, and our picks for a few datalake vendors worth considering. What is a datalake? First, a datalake is a centralized repository that allows users or an organization to store and analyze large volumes of data.
With the current housing shortage and affordability concerns, Rocket simplifies the homeownership process through an intuitive and AI-driven experience. Data exploration and model development were conducted using well-known machine learning (ML) tools such as Jupyter or Apache Zeppelin notebooks.
Amazon DataZone is a data management service that makes it quick and convenient to catalog, discover, share, and govern data stored in AWS, on-premises, and third-party sources. Enterprises can use no-code ML solutions to streamline their operations and optimize their decision-making without extensive administrative overhead.
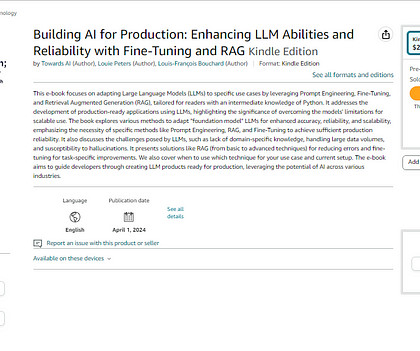
Author(s): Towards AI Editorial Team Originally published on Towards AI. Good morning, AI enthusiasts! This week, I’m super excited to announce that we are finally releasing our book, ‘Building AI for Production; Enhancing LLM Abilities and Reliability with Fine-Tuning and RAG,’ where we gathered all our learnings.
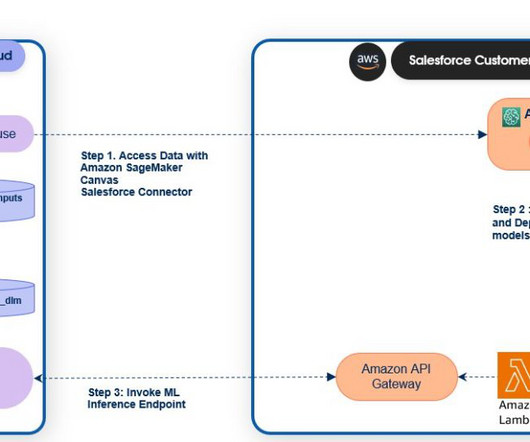
This post is co-authored by Daryl Martis, Director of Product, Salesforce Einstein AI. This is the third post in a series discussing the integration of Salesforce Data Cloud and Amazon SageMaker. SageMaker endpoints can be registered to the Salesforce Data Cloud to activate predictions in Salesforce.
This post presents a solution that uses a generative artificial intelligence (AI) to standardize air quality data from low-cost sensors in Africa, specifically addressing the air quality data integration problem of low-cost sensors. Qiong (Jo) Zhang , PhD, is a Senior Partner Solutions Architect at AWS, specializing in AI/ML.
At the heart of this transformation is the OMRON Data & Analytics Platform (ODAP), an innovative initiative designed to revolutionize how the company harnesses its data assets. The robust security features provided by Amazon S3, including encryption and durability, were used to provide data protection.
If you’re curious about leveraging cutting-edge AI capabilities without the headache of managing complex infrastructure, you’ve come to the right place! This is where Azure Machine Learning shines by democratizing access to advanced AI capabilities. Learn more from the MLflow with Azure ML documentation.
Generative AI models have the potential to revolutionize enterprise operations, but businesses must carefully consider how to harness their power while overcoming challenges such as safeguarding data and ensuring the quality of AI-generated content. This type of data is often used in ML and artificial intelligence applications.
This post is co-authored by Daryl Martis, Director of Product, Salesforce Einstein AI. This is the second post in a series discussing the integration of Salesforce Data Cloud and Amazon SageMaker. This completes the setup to enable data access from Salesforce Data Cloud to SageMaker Studio to build AI and machine learning (ML) models.
These platforms provide data engineers with the flexibility to develop and deploy IoT applications efficiently. DataLakes for Centralized Storage Datalakes serve as centralized repositories for storing raw and processed IoT data.
SageMaker endpoints can be registered with Salesforce Data Cloud to activate predictions in Salesforce. Requests and responses between Salesforce and Amazon Bedrock pass through the Einstein Trust Layer , which promotes responsible AI use across Salesforce.
This post, part of the Governing the ML lifecycle at scale series ( Part 1 , Part 2 , Part 3 ), explains how to set up and govern a multi-account ML platform that addresses these challenges. An enterprise might have the following roles involved in the ML lifecycles. This ML platform provides several key benefits.
Specifically, we cover the computer vision and artificial intelligence (AI) techniques used to combine datasets into a list of prioritized tasks for field teams to investigate and mitigate. Data preparation SageMaker Ground Truth employs a human workforce made up of Northpower volunteers to annotate a set of 10,000 images.
Artificial intelligence (AI) is now at the forefront of how enterprises work with data to help reinvent operations, improve customer experiences, and maintain a competitive advantage. It’s no longer a nice-to-have, but an integral part of a successful data strategy. Why does AI need an open data lakehouse architecture?
Amazon Redshift powers data-driven decisions for tens of thousands of customers every day with a fully managed, AI-powered cloud data warehouse, delivering the best price-performance for your analytics workloads. Discover how you can use Amazon Redshift to build a data mesh architecture to analyze your data.
To accomplish this, eSentire built AI Investigator, a natural language query tool for their customers to access security platform data by using AWS generative artificial intelligence (AI) capabilities. This helps customers quickly and seamlessly explore their security data and accelerate internal investigations.
This combination of great models and continuous adaptation is what will lead to a successful machine learning (ML) strategy. MLOps focuses on the intersection of data science and data engineering in combination with existing DevOps practices to streamline model delivery across the ML development lifecycle.
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, data engineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. and Pandas or Apache Spark DataFrames.
Through a partnership spanning more than 25 years, IBM has helped the Augusta National Golf Club capture, analyze, distribute and use data to bring fans closer to the action, culminating in the AI-powered Masters digital experience and mobile app.
As with many burgeoning fields and disciplines, we don’t yet have a shared canonical infrastructure stack or best practices for developing and deploying data-intensive applications. What does a modern technology stack for streamlined ML processes look like? Why: Data Makes It Different. All ML projects are software projects.
Amazon Bedrock is a fully managed service that makes FMs from leading AI startups and Amazon available via an API, so one can choose from a wide range of FMs to find the model that is best suited for their use case. These factors led to the selection of Amazon Aurora PostgreSQL as the store for vector embeddings.
Whether youre new to AI development or an experienced practitioner, this post provides step-by-step guidance and code examples to help you build more reliable AI applications. Chaithanya Maisagoni is a Senior Software Development Engineer (AI/ML) in Amazons Worldwide Returns and ReCommerce organization.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








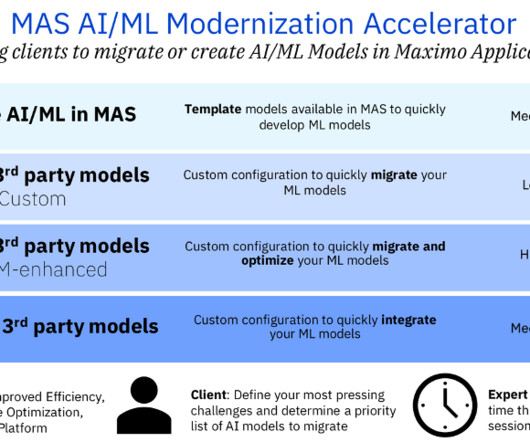








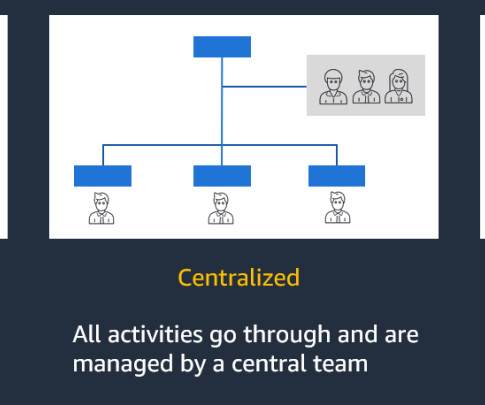





























Let's personalize your content