This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
7 Best Platforms to Practice SQL • Explainable AI: 10 Python Libraries for Demystifying Your Model's Decisions • ChatGPT: Everything You Need to Know • DataLakes and SQL: A Match Made in Data Heaven • Google Data Analytics Certification Review for 2023
As one of the largest AWS customers, Twilio engages with data, artificial intelligence (AI), and machine learning (ML) services to run their daily workloads. Data is the foundational layer for all generative AI and ML applications.
NOTE : Since we used an SQL query engine to query the dataset for this demonstration, the prompts and generated outputs mention SQL below. The question in the preceding example doesn’t require a lot of complex analysis on the data returned from the ETF dataset. A user can ask a business- or industry-related question for ETFs.
In the ever-evolving world of big data, managing vast amounts of information efficiently has become a critical challenge for businesses across the globe. As datalakes gain prominence as a preferred solution for storing and processing enormous datasets, the need for effective data version control mechanisms becomes increasingly evident.
Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. Data engineers use data warehouses, datalakes, and analytics tools to load, transform, clean, and aggregate data.
Our goal was to improve the user experience of an existing application used to explore the counters and insights data. The data is stored in a datalake and retrieved by SQL using Amazon Athena. The following figure shows a search query that was translated to SQL and run.
Structured Query Language (SQL) is a complex language that requires an understanding of databases and metadata. Today, generative AI can enable people without SQL knowledge. The solution in this post aims to bring enterprise analytics operations to the next level by shortening the path to your data using natural language.
DataLakes have been around for well over a decade now, supporting the analytic operations of some of the largest world corporations. Such data volumes are not easy to move, migrate or modernize. The challenges of a monolithic datalake architecture Datalakes are, at a high level, single repositories of data at scale.
Unified data storage : Fabric’s centralized datalake, Microsoft OneLake, eliminates data silos and provides a unified storage system, simplifying data access and retrieval. OneLake is designed to store a single copy of data in a unified location, leveraging the open-source Apache Parquet format.
Generative AI has opened up a lot of potential in the field of AI. One such area that is evolving is using natural language processing (NLP) to unlock new opportunities for accessing data through intuitive SQL queries. The primary goal is to automatically generate SQL queries from natural language text.
We spoke with Dr. Swami Sivasubramanian, Vice President of Data and AI, shortly after AWS re:Invent 2024 to hear his impressionsand to get insights on how the latest AWS innovations help meet the real-world needs of customers as they build and scale transformative generative AI applications. Canva uses AWS to power 1.2
At the heart of this transformation is the OMRON Data & Analytics Platform (ODAP), an innovative initiative designed to revolutionize how the company harnesses its data assets. The robust security features provided by Amazon S3, including encryption and durability, were used to provide data protection.
Earlier this year, we published the first in a series of posts about how AWS is transforming our seller and customer journeys using generative AI. Using our AI assistant built on Amazon Q, team members are saving hours of time each week. This time adds up individually, but also collectively at the team and organizational level.
Domain experts, for example, feel they are still overly reliant on core IT to access the data assets they need to make effective business decisions. In all of these conversations there is a sense of inertia: Data warehouses and datalakes feel cumbersome and data pipelines just aren't agile enough.
These datasets are often a mix of numerical and text data, at times structured, unstructured, or semi-structured. needed to address some of these challenges in one of their many AI use cases built on AWS. RAG with semantic search – Conventional RAG with semantic search was the last step before moving to SQL generation.
Amazon Redshift powers data-driven decisions for tens of thousands of customers every day with a fully managed, AI-powered cloud data warehouse, delivering the best price-performance for your analytics workloads. Discover how you can use Amazon Redshift to build a data mesh architecture to analyze your data.
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructured data. What is a DataLake? Consistency of data throughout the datalake.
Discover the nuanced dissimilarities between DataLakes and Data Warehouses. Data management in the digital age has become a crucial aspect of businesses, and two prominent concepts in this realm are DataLakes and Data Warehouses. It acts as a repository for storing all the data.
Data management problems can also lead to data silos; disparate collections of databases that don’t communicate with each other, leading to flawed analysis based on incomplete or incorrect datasets. One way to address this is to implement a datalake: a large and complex database of diverse datasets all stored in their original format.
Organizations can maximize the value of their modern data architecture with generative AI solutions while innovating continuously. The natural language capabilities allow non-technical users to query data through conversational English rather than complex SQL. The following diagram illustrates the architecture.
With the current housing shortage and affordability concerns, Rocket simplifies the homeownership process through an intuitive and AI-driven experience. Data exploration and model development were conducted using well-known machine learning (ML) tools such as Jupyter or Apache Zeppelin notebooks.
Although setting up a database to run your analyses may seem like an arduous task, modern open-source time series databases can provide significant benefits to any scientist running time series analysis on a large data set — and with much less effort than you might imagine. Interested in attending an ODSC event?
By running reports on historical data, a data warehouse can clarify what systems and processes are working and what methods need improvement. Data warehouse is the base architecture for artificial intelligence and machine learning (AI/ML) solutions as well.
Dolt Created in 2019, Dolt is an open-source tool for managing SQL databases that uses version control similar to Git. It versions tables instead of files and has a SQL query interface for those tables. However, these tools have functional gaps for more advanced data workflows. It provides both community and enterprise editions.
Specifically, we cover the computer vision and artificial intelligence (AI) techniques used to combine datasets into a list of prioritized tasks for field teams to investigate and mitigate. SageMaker JumpStart provided deployable models that could be trained for object detection use cases with minimal data science knowledge and overhead.
Every day, millions of riders use the Uber app, unwittingly contributing to a complex web of data-driven decisions. This blog takes you on a journey into the world of Uber’s analytics and the critical role that Presto, the open source SQL query engine, plays in driving their success. What is Presto?
Adopting & Scaling AI, a Beginner’s Guide to Prompt Engineering, and Pretraining Large Language Models 5 Concerns Surrounding the Scaling and Adoption of AI From privacy and data security to job displacement and more, these are five concerns that people have about AI right now. What Can AI Teach Us About Data Centers?
It’s distributed both in the cloud and on-premises, allowing extensive use and movement across clouds, apps and networks, as well as stores of data at rest. An architecture designed for data democratization aims to be flexible, integrated, agile and secure to enable the use of data and artificial intelligence (AI) at scale.
Domain experts, for example, feel they are still overly reliant on core IT to access the data assets they need to make effective business decisions. In all of these conversations there is a sense of inertia: Data warehouses and datalakes feel cumbersome and data pipelines just aren't agile enough.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and datalakes, using AWS-designed hardware and ML to deliver the best price-performance at any scale. You can use query_string to filter your dataset by SQL and unload it to Amazon S3.
You can streamline the process of feature engineering and data preparation with SageMaker Data Wrangler and finish each stage of the data preparation workflow (including data selection, purification, exploration, visualization, and processing at scale) within a single visual interface.
Cleanlab GitHub | Website Cleanlab is focused on data-centric AI (DCAI), providing algorithms/interfaces to help companies (across all industries) improve the quality of their datasets and diagnose/fix various issues in them. With Great Expectations , data teams can express what they “expect” from their data using simple assertions.
Businesses face significant hurdles when preparing data for artificial intelligence (AI) applications. The existence of data silos and duplication, alongside apprehensions regarding data quality, presents a multifaceted environment for organizations to manage.
is our enterprise-ready next-generation studio for AI builders, bringing together traditional machine learning (ML) and new generative AI capabilities powered by foundation models. With watsonx.ai, businesses can effectively train, validate, tune and deploy AI models with confidence and at scale across their enterprise.
If you’re curious about leveraging cutting-edge AI capabilities without the headache of managing complex infrastructure, you’ve come to the right place! This is where Azure Machine Learning shines by democratizing access to advanced AI capabilities. Learn more from the Responsible AI dashboard documentation.
Computer Science and Computer Engineering Similar to knowing statistics and math, a data scientist should know the fundamentals of computer science as well. While knowing Python, R, and SQL are expected, you’ll need to go beyond that. Big Data As datasets become larger and more complex, knowing how to work with them will be key.
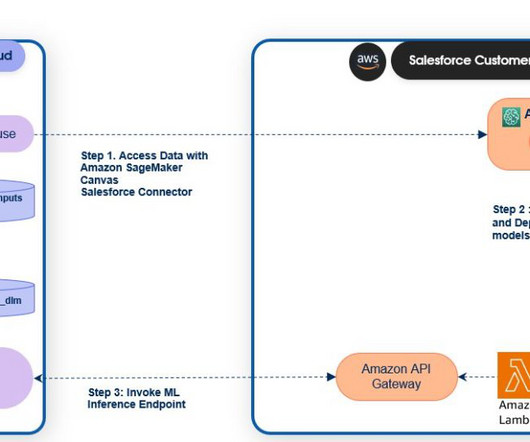
This post is co-authored by Daryl Martis, Director of Product, Salesforce Einstein AI. This is the third post in a series discussing the integration of Salesforce Data Cloud and Amazon SageMaker. Einstein Studio is a gateway to AI tools on Salesforce Data Cloud. Manage Data Cloud profile data ( Data Cloud_profile_api ).
Its PostgreSQL foundation ensures compatibility with most SQL clients. While it shares similarities with PostgreSQL, there are key differences that must be considered during application development. Strengths : High performance with SQL support, easy integration with other AWS services, and strong security features.
Key Skills for Data Science: A data scientist typically needs a blend of skills: Mathematics and Statistics: To understand the theoretical underpinnings of models. Programming: Often in languages like Python or R, using libraries for data manipulation, analysis, and machine learning.
Organizations that want to prove the value of AI by developing, deploying, and managing machine learning models at scale can now do so quickly using the DataRobot AI Platform on Microsoft Azure. This generates reliable business insights and sustains AI-driven value across the enterprise.
Overview: Data science vs data analytics Think of data science as the overarching umbrella that covers a wide range of tasks performed to find patterns in large datasets, structure data for use, train machine learning models and develop artificial intelligence (AI) applications.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content