This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data is the foundation to capturing the maximum value from AI technology and solving business problems quickly. To unlock the potential of generative AI technologies, however, there’s a key prerequisite: your data needs to be appropriately prepared.
Implementing a data fabric architecture is the answer. What is a data fabric? Data fabric is defined by IBM as “an architecture that facilitates the end-to-end integration of various datapipelines and cloud environments through the use of intelligent and automated systems.” This leaves more time for data analysis.
Generative artificial intelligence (gen AI) is transforming the business world by creating new opportunities for innovation, productivity and efficiency. This guide offers a clear roadmap for businesses to begin their gen AI journey. Most teams should include at least four types of team members.
Conventional ML development cycles take weeks to many months and requires sparse data science understanding and ML development skills. Business analysts’ ideas to use ML models often sit in prolonged backlogs because of data engineering and data science team’s bandwidth and datapreparation activities.
Data scientists and ML engineers require capable tooling and sufficient compute for their work. To pave the way for the growth of AI, BMW Group needed to make a leap regarding scalability and elasticity while reducing operational overhead, software licensing, and hardware management.
This post presents a solution that uses a generative artificial intelligence (AI) to standardize air quality data from low-cost sensors in Africa, specifically addressing the air quality data integration problem of low-cost sensors. Qiong (Jo) Zhang , PhD, is a Senior Partner Solutions Architect at AWS, specializing in AI/ML.
In the following sections, we provide a detailed, step-by-step guide on implementing these new capabilities, covering everything from datapreparation to job submission and output analysis. This use case serves to illustrate the broader potential of the feature for handling diverse data processing tasks.
AIOPs refers to the application of artificial intelligence (AI) and machine learning (ML) techniques to enhance and automate various aspects of IT operations (ITOps). However, they differ fundamentally in their purpose and level of specialization in AI and ML environments.
is our enterprise-ready next-generation studio for AI builders, bringing together traditional machine learning (ML) and new generative AI capabilities powered by foundation models. With watsonx.ai, businesses can effectively train, validate, tune and deploy AI models with confidence and at scale across their enterprise.
See also Thoughtworks’s guide to Evaluating MLOps Platforms End-to-end MLOps platforms End-to-end MLOps platforms provide a unified ecosystem that streamlines the entire ML workflow, from datapreparation and model development to deployment and monitoring. Might be useful Unlike manual, homegrown, or open-source solutions, neptune.ai
Yunus focused on building a robust datapipeline, merging historical and current-season data to create a comprehensive dataset. Yunus secured third place by delivering a flexible, well-documented solution that bridged data science and Formula 1 strategy. Follow Ocean on Twitter or Telegram to stay up to date.
In today’s landscape, AI is becoming a major focus in developing and deploying machine learning models. It isn’t just about writing code or creating algorithms — it requires robust pipelines that handle data, model training, deployment, and maintenance. As datasets grow, scalable data ingestion and storage become critical.
Purina used artificial intelligence (AI) and machine learning (ML) to automate animal breed detection at scale. The solution focuses on the fundamental principles of developing an AI/ML application workflow of datapreparation, model training, model evaluation, and model monitoring.
Unfortunately, even the data science industry — which should recognize tabular data’s true value — often underestimates its relevance in AI. Many mistakenly equate tabular data with business intelligence rather than AI, leading to a dismissive attitude toward its sophistication.
Continuous ML model retraining is one method to overcome this challenge by relearning from the most recent data. This requires not only well-designed features and ML architecture, but also datapreparation and ML pipelines that can automate the retraining process.
AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, ML, and application development. Above all, this solution offers you a native Spark way to implement an end-to-end datapipeline from Amazon Redshift to SageMaker.
Effective data governance enhances quality and security throughout the data lifecycle. What is Data Engineering? Data Engineering is designing, constructing, and managing systems that enable data collection, storage, and analysis. They are crucial in ensuring data is readily available for analysis and reporting.
Ray AI Runtime (AIR) reduces friction of going from development to production. Amazon SageMaker Pipelines allows orchestrating the end-to-end ML lifecycle from datapreparation and training to model deployment as automated workflows. We set up an end-to-end Ray-based ML workflow, orchestrated using SageMaker Pipelines.
The primary goal of Data Engineering is to transform raw data into a structured and usable format that can be easily accessed, analyzed, and interpreted by Data Scientists, analysts, and other stakeholders. Future of Data Engineering The Data Engineering market will expand from $18.2
Today’s data management and analytics products have infused artificial intelligence (AI) and machine learning (ML) algorithms into their core capabilities. These modern tools will auto-profile the data, detect joins and overlaps, and offer recommendations. 2) Line of business is taking a more active role in data projects.
Efficient data transformation and processing are crucial for data analytics and generating insights. Snowflake AIData Cloud is one of the most powerful platforms, including storage services supporting complex data. Integrating Snowflake with dbt adds another layer of automation and control to the datapipeline.
Machine learning (ML), a subset of artificial intelligence (AI), is an important piece of data-driven innovation. Machine learning engineers take massive datasets and use statistical methods to create algorithms that are trained to find patterns and uncover key insights in data mining projects.
In order to train a model using data stored outside of the three supported storage services, the data first needs to be ingested into one of these services (typically Amazon S3). This requires building a datapipeline (using tools such as Amazon SageMaker Data Wrangler ) to move data into Amazon S3.
Summary: This article explores the significance of ETL Data in Data Management. It highlights key components of the ETL process, best practices for efficiency, and future trends like AI integration and real-time processing, ensuring organisations can leverage their data effectively for strategic decision-making.
Ali Arsanjani, director of cloud partner engineering at Google Cloud , presented a talk entitled “Challenges and Ethics of DLM and LLM Adoption in the Enterprise” at Snorkel AI’s recent Foundation Model Virtual Summit. Datapreparation, train and tune, deploy and monitor. Hope you can all hear me well.
Ali Arsanjani, director of cloud partner engineering at Google Cloud , presented a talk entitled “Challenges and Ethics of DLM and LLM Adoption in the Enterprise” at Snorkel AI’s recent Foundation Model Virtual Summit. Datapreparation, train and tune, deploy and monitor. Hope you can all hear me well.
Data Scientists and Data Analysts have been using ChatGPT for Data Science to generate codes and answers rapidly. Data Manipulation The process through which you can change the data according to your project requirement for further data analysis is known as Data Manipulation.
Data engineers, data scientists and other data professional leaders have been racing to implement gen AI into their engineering efforts. LLM examples include GPT, BERT, and similar advanced AI systems. They are characterized by their enormous size, complexity, and the vast amount of data they process.
Alteryx provides organizations with an opportunity to automate access to data, analytics , data science, and process automation all in one, end-to-end platform. Its capabilities can be split into the following topics: automating inputs & outputs, datapreparation, data enrichment, and data science.
Future Trends and Innovations The evolving landscape of data, characterised by exponential growth, increasing complexity, and the imperative for real-time insights, is driving rapid advancements in data quality practices. AI and Machine Learning These are emerging as powerful tools for enhancing data quality.
Informatica Informatica is a powerful enterprise-grade data management platform offering a range of tools for data integration, transformation, and governance. It supports batch and real-time data processing, making it a preferred choice for large enterprises with complex data workflows.
In this blog, we will provide a comprehensive overview of ETL considerations, introduce key tools such as Fivetran, Salesforce, and Snowflake AIData Cloud , and demonstrate how to set up a pipeline and ingest data between Salesforce and Snowflake using Fivetran. What is Fivetran?
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
DataPreparation: Cleaning, transforming, and preparingdata for analysis and modelling. The Microsoft Certified: Azure Data Scientist Associate certification is highly recommended, as it focuses on the specific tools and techniques used within Azure.
Snowpark Use Cases Data Science Streamlining datapreparation and pre-processing: Snowpark’s Python, Java, and Scala libraries allow data scientists to use familiar tools for wrangling and cleaning data directly within Snowflake, eliminating the need for separate ETL pipelines and reducing context switching.
These activities cover disparate fields such as basic data processing, analytics, and machine learning (ML). And finally, some activities, such as those involved with the latest advances in artificial intelligence (AI), are simply not practically possible, without hardware acceleration.
A traditional machine learning (ML) pipeline is a collection of various stages that include data collection, datapreparation, model training and evaluation, hyperparameter tuning (if needed), model deployment and scaling, monitoring, security and compliance, and CI/CD.
Computer vision is a subfield of artificial intelligence (AI) that teaches computers to see, observe, and interpret visual cues in the world. Preprocess data to mirror real-world deployment conditions. Thorough validation procedures: Evaluate model performance on unseen data during validation, resembling real-world distribution.
We then go over all the project components and processes, from datapreparation, model training, and experiment tracking to model evaluation, to equip you with the skills to construct your own emotion recognition model. BECOME a WRITER at MLearning.ai // FREE ML Tools // Clearview AI Mlearning.ai
Pipelines and platforms are related concepts in MLOps, but they refer to different aspects of the machine learning workflow. The platform typically includes components for the ML ecosystem like data management, feature stores, experiment trackers, a model registry, a testing environment, model serving, and model management.
It must integrate seamlessly across data technologies in the stack to execute various workflows—all while maintaining a strong focus on performance and governance. Two key technologies that have become foundational for this type of architecture are the Snowflake AIData Cloud and Dataiku. Let’s say your company makes cars.
The ZMP analyzes billions of structured and unstructured data points to predict consumer intent by using sophisticated artificial intelligence (AI) to personalize experiences at scale. Further expanding the capabilities of AI in marketing, Zeta Global has developed AI Lookalikes.
Time and time again, we hear about the need for AI to support cross-functional teams and users. To provide the ability to integrate diverse data sources. To offer the flexibility to deploy AI solutions anywhere. The DataRobot AI Cloud Platform is the culmination of nearly a decade of pioneering AI innovation, representing 1.5
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































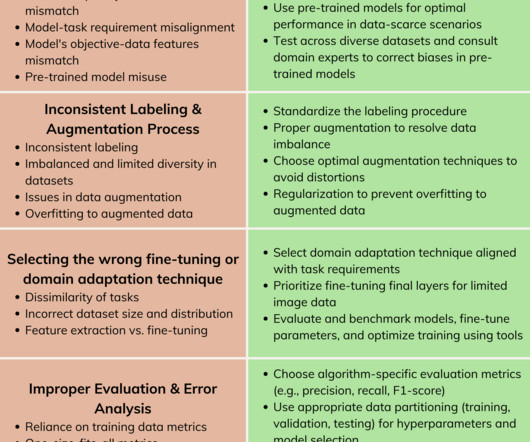











Let's personalize your content