This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
It serves as the primary means for communicating with relational databases, where most organizations store crucial data. SQL plays a significant role including analyzing complex data, creating datapipelines, and efficiently managing datawarehouses. appeared first on Analytics Vidhya.
Built into Data Wrangler, is the Chat for data prep option, which allows you to use natural language to explore, visualize, and transform your data in a conversational interface. Amazon QuickSight powers data-driven organizations with unified (BI) at hyperscale. A provisioned or serverless Amazon Redshift datawarehouse.
Almost every tech company today is up to its neck in generative AI, with Google focused on enhancing search, Microsoft betting the house on business productivity gains with its family of copilots, and startups like Runway AI and Stability AI going all-in on video and image creation. Why is data integrity important?
Datapipelines automatically fetch information from various disparate sources for further consolidation and transformation into high-performing data storage. There are a number of challenges in data storage , which datapipelines can help address. The movement of data in a pipeline from one point to another.
But with the sheer amount of data continually increasing, how can a business make sense of it? Robust datapipelines. What is a DataPipeline? A datapipeline is a series of processing steps that move data from its source to its destination. The answer?
A datawarehouse is a centralized repository designed to store and manage vast amounts of structured and semi-structured data from multiple sources, facilitating efficient reporting and analysis. Begin by determining your data volume, variety, and the performance expectations for querying and reporting.
Summary: This blog explains how to build efficient datapipelines, detailing each step from data collection to final delivery. Introduction Datapipelines play a pivotal role in modern data architecture by seamlessly transporting and transforming raw data into valuable insights.
Data is the differentiator as business leaders look to utilize their competitive edge as they implement generative AI (gen AI). Leaders feel the pressure to infuse their processes with artificial intelligence (AI) and are looking for ways to harness the insights in their data platforms to fuel this movement.
Domain experts, for example, feel they are still overly reliant on core IT to access the data assets they need to make effective business decisions. In all of these conversations there is a sense of inertia: Datawarehouses and data lakes feel cumbersome and datapipelines just aren't agile enough.
But with the sheer amount of data continually increasing, how can a business make sense of it? Robust datapipelines. What is a DataPipeline? A datapipeline is a series of processing steps that move data from its source to its destination. The answer?
Artificial intelligence (AI) adoption is still in its early stages. As more businesses use AI systems and the technology continues to mature and change, improper use could expose a company to significant financial, operational, regulatory and reputational risks. ” Are foundation models trustworthy?
Over the past few decades, the corporate data landscape has changed significantly. The shift from on-premise databases and spreadsheets to the modern era of cloud datawarehouses and AI/ LLMs has transformed what businesses can do with data. This is where Fivetran and the Modern Data Stack come in.
But the implementation of AI is only one piece of the puzzle. The tasks behind efficient, responsible AI lifecycle management The continuous application of AI and the ability to benefit from its ongoing use require the persistent management of a dynamic and intricate AI lifecycle—and doing so efficiently and responsibly.
Amazon Redshift is the most popular cloud datawarehouse that is used by tens of thousands of customers to analyze exabytes of data every day. AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, ML, and application development.
But good data—and actionable insights—are hard to get. Traditionally, organizations built complex datapipelines to replicate data. Those data architectures were brittle, complex, and time intensive to build and maintain, requiring data duplication and bloated datawarehouse investments.
But good data—and actionable insights—are hard to get. Traditionally, organizations built complex datapipelines to replicate data. Those data architectures were brittle, complex, and time intensive to build and maintain, requiring data duplication and bloated datawarehouse investments.
is our enterprise-ready next-generation studio for AI builders, bringing together traditional machine learning (ML) and new generative AI capabilities powered by foundation models. With watsonx.ai, businesses can effectively train, validate, tune and deploy AI models with confidence and at scale across their enterprise.
In the world of AI-driven data workflows, Brij Kishore Pandey, a Principal Engineer at ADP and a respected LinkedIn influencer, is at the forefront of integrating multi-agent systems with Generative AI for ETL pipeline orchestration. Transformation : Data is cleaned, formatted, and enriched. What is an Agent?
In July 2023, Matillion launched their fully SaaS platform called Data Productivity Cloud, aiming to create a future-ready, everyone-ready, and AI-ready environment that companies can easily adopt and start automating their datapipelines coding, low-coding, or even no-coding at all. Or would you even go to that directly?
Run pandas at scale on your datawarehouse Most enterprise data teams store their data in a database or datawarehouse, such as Snowflake, BigQuery, or DuckDB. Ponder solves this problem by translating your pandas code to SQL that can be understood by your datawarehouse.
In this post, you will learn about the 10 best datapipeline tools, their pros, cons, and pricing. A typical datapipeline involves the following steps or processes through which the data passes before being consumed by a downstream process, such as an ML model training process.
Effective data governance enhances quality and security throughout the data lifecycle. What is Data Engineering? Data Engineering is designing, constructing, and managing systems that enable data collection, storage, and analysis. ETL is vital for ensuring data quality and integrity. from 2025 to 2030.
Data engineering is a hot topic in the AI industry right now. And as data’s complexity and volume grow, its importance across industries will only become more noticeable. But what exactly do data engineers do? So let’s do a quick overview of the job of data engineer, and maybe you might find a new interest.
Cleanlab GitHub | Website Cleanlab is focused on data-centric AI (DCAI), providing algorithms/interfaces to help companies (across all industries) improve the quality of their datasets and diagnose/fix various issues in them. You can also get data science training on-demand wherever you are with our Ai+ Training platform.
Overview: Data science vs data analytics Think of data science as the overarching umbrella that covers a wide range of tasks performed to find patterns in large datasets, structure data for use, train machine learning models and develop artificial intelligence (AI) applications.
It highlights key components of the ETL process, best practices for efficiency, and future trends like AI integration and real-time processing, ensuring organisations can leverage their data effectively for strategic decision-making. Introduction ETL plays a crucial role in Data Management.
Domain experts, for example, feel they are still overly reliant on core IT to access the data assets they need to make effective business decisions. In all of these conversations there is a sense of inertia: Datawarehouses and data lakes feel cumbersome and datapipelines just aren't agile enough.
Unfortunately accessing data across various locations and file types and then operationalizing that data for AI usage has traditionally been a painfully manual, time-consuming, and costly process. Ahmad Khan, Head of AI/ML Strategy at Snowflake, discusses the challenges of operationalizing ML in a recent talk.
Unfortunately accessing data across various locations and file types and then operationalizing that data for AI usage has traditionally been a painfully manual, time-consuming, and costly process. Ahmad Khan, Head of AI/ML Strategy at Snowflake, discusses the challenges of operationalizing ML in a recent talk.
The primary goal of Data Engineering is to transform raw data into a structured and usable format that can be easily accessed, analyzed, and interpreted by Data Scientists, analysts, and other stakeholders. Future of Data Engineering The Data Engineering market will expand from $18.2
Best practices are a pivotal part of any software development, and data engineering is no exception. This ensures the datapipelines we create are robust, durable, and secure, providing the desired data to the organization effectively and consistently. Below are the best practices.
Data Analytics in the Age of AI, When to Use RAG, Examples of Data Visualization with D3 and Vega, and ODSC East Selling Out Soon Data Analytics in the Age of AI Let’s explore the multifaceted ways in which AI is revolutionizing data analytics, making it more accessible, efficient, and insightful than ever before.
the presenters elaborated on the common pain points of the cloud datawarehouse today and predicted what it may look like in the future. With the rise of AI, the speakers speculated that the future modern data stack may not be designed with human consumers in mind, but set up instead for AI/ML.
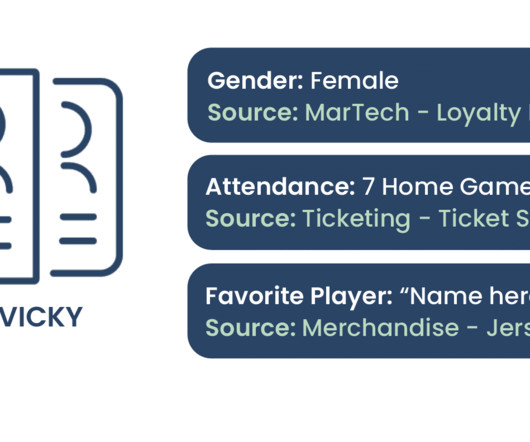
We are going to break down what we know about Victory Vicky based on all the data sources we have moved into our datawarehouse. The loyalty program is located in the MarTech Stack and moves data effortlessly into the datawarehouse. This information is also funneled into the datawarehouse.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create datapipelines, ETL processes, and databases to facilitate smooth data flow and storage. Read more to know. Cloud Platforms: AWS, Azure, Google Cloud, etc.
Must Read Blogs: Exploring the Power of DataWarehouse Functionality. Data Lakes Vs. DataWarehouse: Its significance and relevance in the data world. Exploring Differences: Database vs DataWarehouse. It is commonly used in datawarehouses for business analytics and reporting.
Hello from our new, friendly, welcoming, definitely not an AI overlord cookie logo! The second is to provide a directed acyclic graph (DAG) for datapipelining and model building. Teams that primarily access hosted data or assets (e.g., These options include DVC, Pachyderm and Quilt.
Also Read: Top 10 Data Science tools for 2024. It is a process for moving and managing data from various sources to a central datawarehouse. This process ensures that data is accurate, consistent, and usable for analysis and reporting. This process helps organisations manage large volumes of data efficiently.
This open-source streaming platform enables the handling of high-throughput data feeds, ensuring that datapipelines are efficient, reliable, and capable of handling massive volumes of data in real-time. You can also get data science training on-demand wherever you are with our Ai+ Training platform.
It is a data integration process that involves extracting data from various sources, transforming it into a suitable format, and loading it into a target system, typically a datawarehouse. ETL is the backbone of effective data management, ensuring organisations can leverage their data for informed decision-making.
Organizations can search for PII using methods such as keyword searches, pattern matching, data loss prevention tools, machine learning (ML), metadata analysis, data classification software, optical character recognition (OCR), document fingerprinting, and encryption.
But good data—and actionable insights—are hard to get. Traditionally, organizations built complex datapipelines to replicate data. Those data architectures were brittle, complex, and time intensive to build and maintain, requiring data duplication and bloated datawarehouse investments.
When you make it easier to work with events, other users like analysts and data engineers can start gaining real-time insights and work with datasets when it matters most. As a result, you reduce the skills barrier and increase your speed of data processing by preventing important information from getting stuck in a datawarehouse.
Using 3rd party tooling is essential if you’re a Snowflake AIData Cloud customer. Getting your data into Snowflake, creating analytics applications from the data, and even ensuring your Snowflake account runs smoothly all require some sort of tool. The post What Free Tools Pair Well With The Snowflake AIData Cloud?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content