This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Imagine yourself as a data professional tasked with creating an efficient datapipeline to streamline processes and generate real-time information. That’s where Mage AI comes in to ensure that the lenders operating online gain a competitive edge. Sounds challenging, right?
It serves as the primary means for communicating with relational databases, where most organizations store crucial data. SQL plays a significant role including analyzing complex data, creating datapipelines, and efficiently managing data warehouses.
Relational Graph Transformers represent the next evolution in Relational Deep Learning, allowing AI systems to seamlessly navigate and learn from data spread across multiple tables.
Almost every tech company today is up to its neck in generative AI, with Google focused on enhancing search, Microsoft betting the house on business productivity gains with its family of copilots, and startups like Runway AI and Stability AI going all-in on video and image creation. Why is data integrity important?
Datapipelines automatically fetch information from various disparate sources for further consolidation and transformation into high-performing data storage. There are a number of challenges in data storage , which datapipelines can help address. Choosing the right datapipeline solution.
Modern datapipeline platform provider Matillion today announced at Snowflake Data Cloud Summit 2024 that it is bringing no-code Generative AI (GenAI) to Snowflake users with new GenAI capabilities and integrations with Snowflake Cortex AI, Snowflake ML Functions, and support for Snowpark Container Services.
Generative AI applications seem simpleinvoke a foundation model (FM) with the right context to generate a response. Many organizations have siloed generative AI initiatives, with development managed independently by various departments and lines of businesses (LOBs). This approach facilitates centralized governance and operations.
Amazon Bedrock Agents helps you accelerate generative AI application development by orchestrating multistep tasks. With the power of AI automation, you can boost productivity and reduce cost. The generative AI–based application builder assistant from this post will help you accomplish tasks through all three tiers.
The concept of streaming data was born of necessity. More than ever, advanced analytics, ML, and AI are providing the foundation for innovation, efficiency, and profitability. But insights derived from day-old data don’t cut it. Business success is based on how we use continuously changing data.
The landscape of enterprise application development is undergoing a seismic shift with the advent of generative AI. This intuitive platform enables the rapid development of AI-powered solutions such as conversational interfaces, document summarization tools, and content generation apps through a drag-and-drop interface.
This can be useful for data scientists who need to streamline their data science pipeline or automate repetitive tasks. It provides access to a vast database of scholarly articles and books, as well as tools for literature review and data analysis.
Building generative AI applications presents significant challenges for organizations: they require specialized ML expertise, complex infrastructure management, and careful orchestration of multiple services. The following diagram illustrates the conceptual architecture of an AI assistant with Amazon Bedrock IDE.
Business leaders risk compromising their competitive edge if they do not proactively implement generative AI (gen AI). However, businesses scaling AI face entry barriers. This situation will exacerbate data silos, increase costs and complicate the governance of AI and data workloads.
To solve this, Noodoe has integrated large language models (LLMs) through Amazon Bedrock and Amazon Bedrock Agents to deliver intelligent automation, real-time data access, and multilingual support. In this post, we explore how Noodoe uses AI and Amazon Bedrock to optimize EV charging operations.
Resilience plays a pivotal role in the development of any workload, and generative AI workloads are no different. There are unique considerations when engineering generative AI workloads through a resilience lens. In this post, we discuss the different stacks of a generative AI workload and what those considerations should be.
Generative AI applications are gaining widespread adoption across various industries, including regulated industries such as financial services and healthcare. To address this need, AWS generative AI best practices framework was launched within AWS Audit Manager , enabling auditing and monitoring of generative AI applications.
This post introduces HCLTechs AutoWise Companion, a transformative generative AI solution designed to enhance customers vehicle purchasing journey. Powered by generative AI services on AWS and large language models (LLMs) multi-modal capabilities, HCLTechs AutoWise Companion provides a seamless and impactful experience.
Summary: This blog explains how to build efficient datapipelines, detailing each step from data collection to final delivery. Introduction Datapipelines play a pivotal role in modern data architecture by seamlessly transporting and transforming raw data into valuable insights.
Database name : Enter dev. Database user : Enter awsuser. SageMaker Canvas integration with Amazon Redshift provides a unified environment for building and deploying machine learning models, allowing you to focus on creating value with your data rather than focusing on the technical details of building datapipelines or ML algorithms.
The following diagram illustrates the datapipeline for indexing and query in the foundational search architecture. These databases typically use k-nearest (k-NN) indexes built with advanced algorithms such as Hierarchical Navigable Small Worlds (HNSW) and Inverted File (IVF) systems.
Last Updated on March 21, 2023 by Editorial Team Author(s): Data Science meets Cyber Security Originally published on Towards AI. Navigating the World of Data Engineering: A Beginner’s Guide. A GLIMPSE OF DATA ENGINEERING ❤ IMAGE SOURCE: BY AUTHOR Data or data? What are ETL and datapipelines?
The companies include: Talc AI, a service for assessing large language models. Watto AI, an AI program that generates consulting reports. Neum AI, a platform designed to assist companies in maintaining the relevancy of their AI applications with the latest data. Talc AI Talc.ai
Many customers are building generative AI apps on Amazon Bedrock and Amazon CodeWhisperer to create code artifacts based on natural language. Amazon Bedrock is the easiest way to build and scale generative AI applications with foundation models (FMs). This post was co-written with Greg Benson, Chief Scientist; Aaron Kesler, Sr.
The United States published a Blueprint for the AI Bill of Rights. The growth of the AI and Machine Learning (ML) industry has continued to grow at a rapid rate over recent years. Source: A Chat with Andrew on MLOps: From Model-centric to Data-centric AI So how does this data-centric approach fit in with Machine Learning? — Features
This post is a bitesize walk-through of the 2021 Executive Guide to Data Science and AI — a white paper packed with up-to-date advice for any CIO or CDO looking to deliver real value through data. Automation Automating datapipelines and models ➡️ 6. Download the free, unabridged version here.
Summary: Data engineering tools streamline data collection, storage, and processing. Learning these tools is crucial for building scalable datapipelines. offers Data Science courses covering these tools with a job guarantee for career growth. What Does a Data Engineer Do?
Implementing a data fabric architecture is the answer. What is a data fabric? Data fabric is defined by IBM as “an architecture that facilitates the end-to-end integration of various datapipelines and cloud environments through the use of intelligent and automated systems.”
This is enforced with the `more` excerpt separator. --> AI caught everyone’s attention in 2023 with Large Language Models (LLMs) that can be instructed to perform general tasks, such as translation or coding, just by prompting. In this post, we analyze the trend toward compound AI systems and what it means for AI developers.
This post presents a solution that uses a generative artificial intelligence (AI) to standardize air quality data from low-cost sensors in Africa, specifically addressing the air quality data integration problem of low-cost sensors. This allows for data to be aggregated for further manufacturer-agnostic analysis.
AI, serverless computing, and edge technologies redefine cloud-based Data Science workflows. Defining Cloud Computing in Data Science Cloud computing provides on-demand access to computing resources such as servers, storage, databases, and software over the Internet. billion in 2023 to USD 1,266.4
Data scientists and ML engineers require capable tooling and sufficient compute for their work. To pave the way for the growth of AI, BMW Group needed to make a leap regarding scalability and elasticity while reducing operational overhead, software licensing, and hardware management.
As AI technologies continue to evolve, understanding the functionalities and development stages of LLM applications is essential for both new and seasoned developers. Data annotation: Adding relevant metadata to enhance the model’s learning capabilities. KLU.ai: Offers no-code solutions for smooth data source integration.
This orchestration process encompasses interactions with external APIs, retrieval of contextual data from vector databases, and maintaining memory across multiple LLM calls. This makes it easy to connect your datapipeline to the data sources that you need. It is known for its extensibility and modularity.
Summary: Time series databases (TSDBs) are built for efficiently storing and analyzing data that changes over time. This data, often from sensors or IoT devices, is typically collected at regular intervals. Buckle up as we navigate the intricacies of storing and analysing this dynamic data.
Generative artificial intelligence (generative AI) has enabled new possibilities for building intelligent systems. Recent improvements in Generative AI based large language models (LLMs) have enabled their use in a variety of applications surrounding information retrieval.
The acronym ETL—Extract, Transform, Load—has long been the linchpin of modern data management, orchestrating the movement and manipulation of data across systems and databases. This methodology has been pivotal in data warehousing, setting the stage for analysis and informed decision-making.
Generative artificial intelligence (gen AI) is transforming the business world by creating new opportunities for innovation, productivity and efficiency. This guide offers a clear roadmap for businesses to begin their gen AI journey. Most teams should include at least four types of team members.
AI and generative Al can lead to major enterprise advancements and productivity gains. One popular gen AI use case is customer service and personalization. Gen AI chatbots have quickly transformed the way that customers interact with organizations. Another less obvious use case is fraud detection and prevention.
AIs transformative impact extends throughout the modern business landscape, with telecommunications emerging as a key area of innovation. Fastweb , one of Italys leading telecommunications operators, recognized the immense potential of AI technologies early on and began investing in this area in 2019.
Data is the differentiator as business leaders look to utilize their competitive edge as they implement generative AI (gen AI). Leaders feel the pressure to infuse their processes with artificial intelligence (AI) and are looking for ways to harness the insights in their data platforms to fuel this movement.
It must integrate seamlessly across data technologies in the stack to execute various workflows—all while maintaining a strong focus on performance and governance. Two key technologies that have become foundational for this type of architecture are the Snowflake AIData Cloud and Dataiku. Let’s say your company makes cars.
It is critical for AI models to capture not only the context, but also the cultural specificities to produce a more natural sounding translation. Translation memory A translation memory is a database that stores previously translated text segments (typically sentences or phrases) along with their corresponding translations.
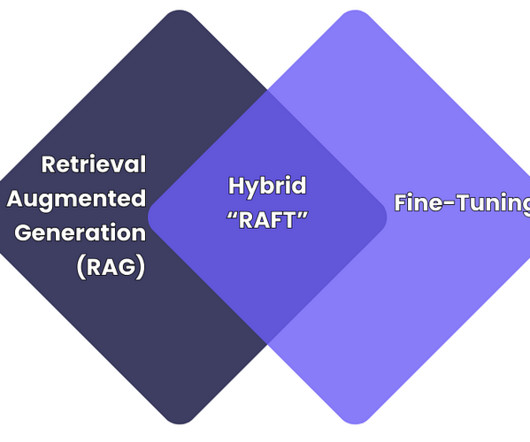
Originally published on Towards AI. RAFT vs Fine-Tuning Image created by author As the use of large language models (LLMs) grows within businesses, to automate tasks, analyse data, and engage with customers; adapting these models to specific needs (e.g.,
The University of British Columbia (UBC) Cloud Innovation Centre (CIC) has become a hub for innovation by prototyping generative AI applications in collaboration with public sector sponsors. Importance of rapid prototyping in AI development Rapid prototyping is critical in AI development.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content