This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The fields of Data Science, Artificial Intelligence (AI), and Large Language Models (LLMs) continue to evolve at an unprecedented pace. In this blog, we will explore the top 7 LLM, data science, and AI blogs of 2024 that have been instrumental in disseminating detailed and updated information in these dynamic fields.
RAG helps models access a specific library or database, making it suitable for tasks that require factual accuracy. Granite 3.0 : IBM launched open-source LLMs for enterprise AI 1. Fine-tuning large language models allows businesses to adapt AI to industry-specific needs 2.
Datapreparation is a crucial step in any machine learning (ML) workflow, yet it often involves tedious and time-consuming tasks. Amazon SageMaker Canvas now supports comprehensive datapreparation capabilities powered by Amazon SageMaker Data Wrangler. Within the data flow, add an Amazon S3 destination node.
Businesses face significant hurdles when preparingdata for artificial intelligence (AI) applications. The existence of data silos and duplication, alongside apprehensions regarding data quality, presents a multifaceted environment for organizations to manage.
Why do some embedded analytics projects succeed while others fail? We surveyed 500+ application teams embedding analytics to find out which analytics features actually move the needle. Read the 6th annual State of Embedded Analytics Report to discover new best practices. Brought to you by Logi Analytics.
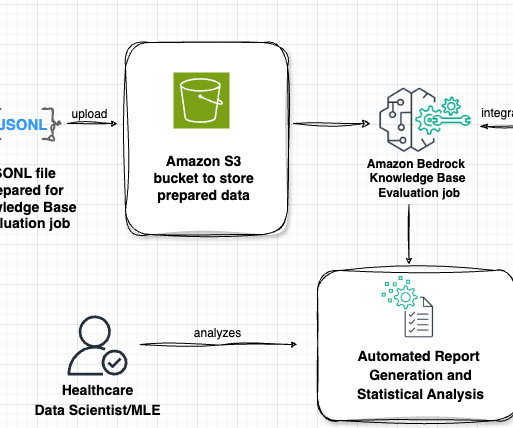
Retrieval Augmented Generation (RAG) has become a crucial technique for improving the accuracy and relevance of AI-generated responses. Knowledge base – You need a knowledge base created in Amazon Bedrock with ingested data and metadata.
Read more about: AI hallucinations and risks associated with large language models AI hallucinations What is RAG? Step 3: Storage in vector database After extracting text chunks, we store and index them for future searches using the RAG application. Retrievers serve as interfaces that return documents based on a query.
This includes sourcing, gathering, arranging, processing, and modeling data, as well as being able to analyze large volumes of structured or unstructured data. The goal of datapreparation is to present data in the best forms for decision-making and problem-solving.
Generative AI is rapidly reshaping industries worldwide, empowering businesses to deliver exceptional customer experiences, streamline processes, and push innovation at an unprecedented scale. Specifically, we discuss Data Replys red teaming solution, a comprehensive blueprint to enhance AI safety and responsible AI practices.
Amazon Bedrock Model Distillation is generally available, and it addresses the fundamental challenge many organizations face when deploying generative AI : how to maintain high performance while reducing costs and latency. We show the latency and output speed comparison for different models in the following figure. Notably, the Llama 3.1
It must integrate seamlessly across data technologies in the stack to execute various workflows—all while maintaining a strong focus on performance and governance. Two key technologies that have become foundational for this type of architecture are the Snowflake AIData Cloud and Dataiku. Let’s say your company makes cars.
SageMaker Unied Studio is an integrated development environment (IDE) for data, analytics, and AI. Discover your data and put it to work using familiar AWS tools to complete end-to-end development workflows, including data analysis, data processing, model training, generative AI app building, and more, in a single governed environment.
Summary: Retrieval-Augmented Generation (RAG) combines information retrieval and generative models to improve AI output. Introduction In the rapidly evolving landscape of Artificial Intelligence (AI), Retrieval-Augmented Generation (RAG) has emerged as a transformative approach that enhances the capabilities of language models.
Conventional ML development cycles take weeks to many months and requires sparse data science understanding and ML development skills. Business analysts’ ideas to use ML models often sit in prolonged backlogs because of data engineering and data science team’s bandwidth and datapreparation activities.
Generative artificial intelligence (gen AI) is transforming the business world by creating new opportunities for innovation, productivity and efficiency. This guide offers a clear roadmap for businesses to begin their gen AI journey. Most teams should include at least four types of team members.
Last Updated on November 9, 2024 by Editorial Team Author(s): Houssem Ben Braiek Originally published on Towards AI. Datapreparation isn’t just a part of the ML engineering process — it’s the heart of it. Join thousands of data leaders on the AI newsletter. Published via Towards AI
While AI solutions do present potential benefits such as increased efficiency and cost reduction, it is crucial for businesses and society to thoroughly consider the ethical and social implications before widespread adoption. The resulting vector representations can then be stored in a vector database.
This trend toward multimodality enhances the capabilities of AI systems in tasks like cross-modal retrieval, where a query in one modality (such as text) retrieves data in another modality (such as images or design files). All businesses, across industry and size, can benefit from multimodal AI search.
Generative artificial intelligence ( generative AI ) models have demonstrated impressive capabilities in generating high-quality text, images, and other content. However, these models require massive amounts of clean, structured training data to reach their full potential. Clean data is important for good model performance.
Online analytical processing (OLAP) database systems and artificial intelligence (AI) complement each other and can help enhance data analysis and decision-making when used in tandem. As AI techniques continue to evolve, innovative applications in the OLAP domain are anticipated.
Last Updated on December 20, 2024 by Editorial Team Author(s): Towards AI Editorial Team Originally published on Towards AI. You might also enjoy the practical tutorials on building an AI research agent using Pydantic AI and the step-by-step guide on fine-tuning the PaliGemma2 model for object detection. Enjoy the read!
Data scientists and ML engineers require capable tooling and sufficient compute for their work. To pave the way for the growth of AI, BMW Group needed to make a leap regarding scalability and elasticity while reducing operational overhead, software licensing, and hardware management.
This post presents a solution that uses a generative artificial intelligence (AI) to standardize air quality data from low-cost sensors in Africa, specifically addressing the air quality data integration problem of low-cost sensors. This allows for data to be aggregated for further manufacturer-agnostic analysis.
Imagine a future where artificial intelligence (AI) seamlessly collaborates with existing supply chain solutions, redefining how organizations manage their assets. If you’re currently using traditional AI, advanced analytics, and intelligent automation, aren’t you already getting deep insights into asset performance?
In our previous blog posts, we explored various techniques such as fine-tuning large language models (LLMs), prompt engineering, and Retrieval Augmented Generation (RAG) using Amazon Bedrock to generate impressions from the findings section in radiology reports using generative AI. Part 1 focused on model fine-tuning.
GenASL is a generative artificial intelligence (AI) -powered solution that translates speech or text into expressive ASL avatar animations, bridging the gap between spoken and written language and sign language. Users can input audio, video, or text into GenASL, which generates an ASL avatar video that interprets the provided data.
With this new capability, you can securely ask questions on single documents, without the overhead of setting up a vector database or ingesting data, making it effortless for businesses to use their enterprise data. You only need to provide a relevant data file as input and choose your FM to get started.
Now all you need is some guidance on generative AI and machine learning (ML) sessions to attend at this twelfth edition of re:Invent. And although generative AI has appeared in previous events, this year we’re taking it to the next level. And although our track focuses on generative AI, many other tracks have related sessions.
Ensuring high-quality data A crucial aspect of downstream consumption is data quality. Studies have shown that 80% of time is spent on datapreparation and cleansing, leaving only 20% of time for data analytics. This leaves more time for data analysis. Let’s use address data as an example.
The sample dataset Upload the dataset to Amazon S3 and crawl the data to create an AWS Glue database and tables. For instructions to catalog the data, refer to Populating the AWS Glue Data Catalog. Choose Data Wrangler in the navigation pane. On the Import and prepare dropdown menu, choose Tabular.
Solution overview With SageMaker Studio JupyterLab notebook’s SQL integration, you can now connect to popular data sources like Snowflake, Athena, Amazon Redshift, and Amazon DataZone. For example, you can visually explore data sources like databases, tables, and schemas directly from your JupyterLab ecosystem.
Last Updated on January 29, 2024 by Editorial Team Author(s): Cassidy Hilton Originally published on Towards AI. Recapping the Cloud Amplifier and Snowflake Demo The combined power of Snowflake and Domo’s Cloud Amplifier is the best-kept secret in data management right now — and we’re reaching new heights every day.
Each component in this ecosystem is very important in the data-driven decision-making process for an organization. Data Sources and Collection Everything in data science begins with data. Data can be generated from databases, sensors, social media platforms, APIs, logs, and web scraping.
We believe generative AI has the potential over time to transform virtually every customer experience we know. Innovative startups like Perplexity AI are going all in on AWS for generative AI. And at the top layer, we’ve been investing in game-changing applications in key areas like generative AI-based coding.
Nowadays, the majority of our customers is excited about large language models (LLMs) and thinking how generative AI could transform their business. In this post, we discuss how to operationalize generative AI applications using MLOps principles leading to foundation model operations (FMOps).
In this post, we showcase how to build an end-to-end generative AI application for enterprise search with Retrieval Augmented Generation (RAG) by using Haystack pipelines and the Falcon-40b-instruct model from Amazon SageMaker JumpStart and Amazon OpenSearch Service. It also hosts foundation models solely developed by Amazon, such as AlexaTM.
Amazon SageMaker Data Wrangler is a single visual interface that reduces the time required to preparedata and perform feature engineering from weeks to minutes with the ability to select and clean data, create features, and automate datapreparation in machine learning (ML) workflows without writing any code.
For readers who work in ML/AI, it’s well understood that machine learning models prefer feature vectors of numerical information. However, the majority of enterprise data remains unleveraged from an analytics and machine learning perspective, and much of the most valuable information remains in relational database schemas such as OLAP.
What they’re testing: Basic datapreparation awareness as it relates to visualization. Sample Answer: “First, I’d try to understand why the data is missing is it random, or is there a pattern? The approach depends on the context and the amount of missing data. How would you approach this?
However, companies are discovering that performing full fine tuning for these models with their data isnt cost effective. To reduce costs while continuing to use the power of AI , many companies have shifted to fine tuning LLMs on their domain-specific data using Parameter-Efficient Fine Tuning (PEFT).
This problem often stems from inadequate user value, underwhelming performance, and an absence of robust best practices for building and deploying LLM tools as part of the AI development lifecycle. Real-world applications often expose gaps that proper datapreparation could have preempted. Evaluation: Tools likeNotion.
RAG provides additional knowledge to the LLM through its input prompt space and its architecture typically consists of the following components: Indexing : Prepare a corpus of unstructured text, parse and chunk it, and then, embed each chunk and store it in a vector database.
Snowflake is an AWS Partner with multiple AWS accreditations, including AWS competencies in machine learning (ML), retail, and data and analytics. You can import data from multiple data sources, such as Amazon Simple Storage Service (Amazon S3), Amazon Athena , Amazon Redshift , Amazon EMR , and Snowflake.
AI platform tools enable knowledge workers to analyze data, formulate predictions and execute tasks with greater speed and precision than they can manually. AI plays a pivotal role as a catalyst in the new era of technological advancement. PwC calculates that “AI could contribute up to USD 15.7 trillion in value.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content