This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Built into Data Wrangler, is the Chat for data prep option, which allows you to use natural language to explore, visualize, and transform your data in a conversational interface. Amazon QuickSight powers data-driven organizations with unified (BI) at hyperscale. A provisioned or serverless Amazon Redshift datawarehouse.
It powers business decisions, drives AI models, and keeps databases running efficiently. But heres the problem: raw data is often messy. Without proper organization, databases become bloated, slow, and unreliable. Thats where data normalization comes in. Thats where data normalization comes in.
It serves as the primary means for communicating with relational databases, where most organizations store crucial data. SQL plays a significant role including analyzing complex data, creating data pipelines, and efficiently managing datawarehouses.
Summary : This guide provides an in-depth look at the top datawarehouse interview questions and answers essential for candidates in 2025. Covering key concepts, techniques, and best practices, it equips you with the knowledge needed to excel in interviews and demonstrates your expertise in data warehousing.
Artificial Intelligence (AI) is all the rage, and rightly so. By now most of us have experienced how Gen AI and the LLMs (large language models) that fuel it are primed to transform the way we create, research, collaborate, engage, and much more. Can AIs responses be trusted? Can it do it without bias?
SQL (Structured Query Language) is an important tool for data scientists. It is a programming language used to manipulate data stored in relational databases. Mastering SQL concepts allows a data scientist to quickly analyze large amounts of data and make decisions based on their findings.
The main solutions on the market are decentralized file storage networks (DSFN) like Filecoin and Arweave, and decentralized datawarehouses like Space and Time (SxT). Built to seamlessly integrate with existing enterprise systems, the datawarehouse lets businesses tap into blockchain data while publishing query results back on-chain.
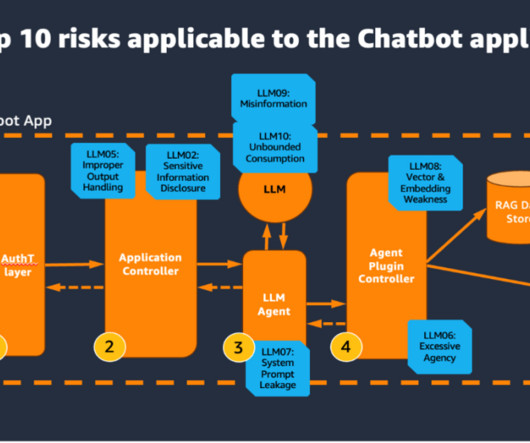
A common use case with generative AI that we usually see customers evaluate for a production use case is a generative AI-powered assistant. If there are security risks that cant be clearly identified, then they cant be addressed, and that can halt the production deployment of the generative AI application.
Organisations must store data in a safe and secure place for which Databases and Datawarehouses are essential. You must be familiar with the terms, but Database and DataWarehouse have some significant differences while being equally crucial for businesses. What is a Database?
Dating back to the 1970s, the data warehousing market emerged when computer scientist Bill Inmon first coined the term ‘datawarehouse’. Created as on-premise servers, the early datawarehouses were built to perform on just a gigabyte scale.
In today’s world, datawarehouses are a critical component of any organization’s technology ecosystem. The rise of cloud has allowed datawarehouses to provide new capabilities such as cost-effective data storage at petabyte scale, highly scalable compute and storage, pay-as-you-go pricing and fully managed service delivery.
Businesses face significant hurdles when preparing data for artificial intelligence (AI) applications. The existence of data silos and duplication, alongside apprehensions regarding data quality, presents a multifaceted environment for organizations to manage.
Data is reported from one central repository, enabling management to draw more meaningful business insights and make faster, better decisions. By running reports on historical data, a datawarehouse can clarify what systems and processes are working and what methods need improvement.
Organizations are building data-driven applications to guide business decisions, improve agility, and drive innovation. Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. The following screenshot illustrates the SageMaker Unified Studio.
A datawarehouse is a centralized repository designed to store and manage vast amounts of structured and semi-structured data from multiple sources, facilitating efficient reporting and analysis. Begin by determining your data volume, variety, and the performance expectations for querying and reporting.
Almost every tech company today is up to its neck in generative AI, with Google focused on enhancing search, Microsoft betting the house on business productivity gains with its family of copilots, and startups like Runway AI and Stability AI going all-in on video and image creation. Why is data integrity important?
Summary: A DataWarehouse consolidates enterprise-wide data for analytics, while a Data Mart focuses on department-specific needs. DataWarehouses offer comprehensive insights but require more resources, whereas Data Marts provide cost-effective, faster access to focused data.
Former Microsoft and Snowflake exec Bob Muglia’s new book is “ The Datapreneurs: The Promise of AI and the Creators Building Our Future.” ” This week: the origins of data, and the future of the digital species. People will use AI for every possible purpose: the good, the bad, and the evil.
In this article, we will delve into the concept of data lakes, explore their differences from datawarehouses and relational databases, and discuss the significance of data version control in the context of large-scale data management. Before we address the questions, ‘ What is data version control ?’
Discover the nuanced dissimilarities between Data Lakes and DataWarehouses. Data management in the digital age has become a crucial aspect of businesses, and two prominent concepts in this realm are Data Lakes and DataWarehouses. It acts as a repository for storing all the data.
With the advent of generative AI solutions, organizations are finding different ways to apply these technologies to gain edge over their competitors. Amazon Bedrock offers a choice of high-performing foundation models from leading AI companies, including AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon, via a single API.
The abilities of an organization towards capturing, storing, and analyzing data; searching, sharing, transferring, visualizing, querying, and updating data; and meeting compliance and regulations are mandatory for any sustainable organization. For example, most datawarehouses […].
Summary: Online Analytical Processing (OLAP) systems in DataWarehouse enable complex Data Analysis by organizing information into multidimensional structures. Key characteristics include fast query performance, interactive analysis, hierarchical data organization, and support for multiple users.
Last Updated on April 11, 2024 by Editorial Team Author(s): ronilpatil Originally published on Towards AI. Image by Author Configure PostgreSQL Database Step 1. Search for RDS Services, click on Create database, and select Standard create & move down. But how EC2 will communicate with this database?
IBM today announced it is launching IBM watsonx.data , a data store built on an open lakehouse architecture, to help enterprises easily unify and govern their structured and unstructured data, wherever it resides, for high-performance AI and analytics. What is watsonx.data?
A point of data entry in a given pipeline. Examples of an origin include storage systems like data lakes, datawarehouses and data sources that include IoT devices, transaction processing applications, APIs or social media. The final point to which the data has to be eventually transferred is a destination.
In today’s digital age where data stands as a prized asset, generative AI serves as the transformative tool to mine its potential. According to a survey by the MIT Sloan Management Review, nearly 85% of executives believe generative AI will enable their companies to obtain or sustain a competitive advantage.
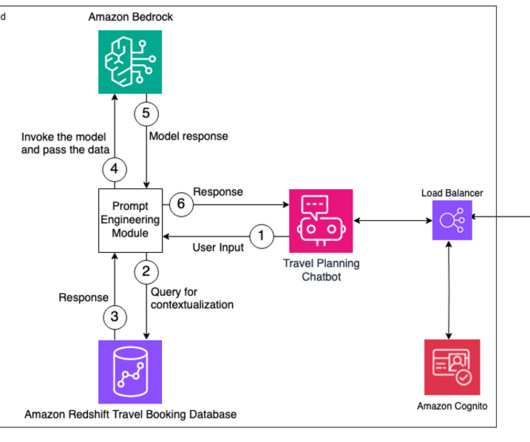
These datasets are often a mix of numerical and text data, at times structured, unstructured, or semi-structured. needed to address some of these challenges in one of their many AI use cases built on AWS. The generated query is then run against the database to fetch the relevant context.
Online analytical processing (OLAP) database systems and artificial intelligence (AI) complement each other and can help enhance data analysis and decision-making when used in tandem. As AI techniques continue to evolve, innovative applications in the OLAP domain are anticipated.
IBM watsonx is changing the game for enterprises of all shapes and sizes, making it easy for them to embed generative AI into their operations. Watsonx is comprised of three components that empower businesses to customize their AI solutions: watsonx.ai The most common use cases from partners often combine several of these AI tasks.
Organizations can maximize the value of their modern data architecture with generative AI solutions while innovating continuously. The natural language capabilities allow non-technical users to query data through conversational English rather than complex SQL. The following diagram illustrates the architecture.
It highlights their unique functionalities and applications, emphasising their roles in maintaining data integrity and facilitating efficient data retrieval in database design and management. Understanding the significance of different types of keys in DBMS is crucial for effective database design and management.
To do so, Presto and Spark need to readily work with existing and modern datawarehouse infrastructures. Now, let’s chat about why datawarehouse optimization is a key value of a data lakehouse strategy. To effectively use raw data, it often needs to be curated within a datawarehouse.
Solution overview With SageMaker Studio JupyterLab notebook’s SQL integration, you can now connect to popular data sources like Snowflake, Athena, Amazon Redshift, and Amazon DataZone. For example, you can visually explore data sources like databases, tables, and schemas directly from your JupyterLab ecosystem.
Thus, was born a single database and the relational model for transactions and business intelligence. Its early success, coupled with IBM WebSphere in the 1990s, put it in the spotlight as the database system for several Olympic games, including 1992 Barcelona, 1996 Atlanta, and the 1998 Winter Olympics in Nagano.
The new Amazon Relational Database Service (Amazon RDS) for Db2 offering allows customers to migrate their existing, self-managed Db2 databases to the cloud and accelerate strategic modernization initiatives. Can Amazon RDS for Db2 be used for running data warehousing workloads?
While databases were the traditional way to store large amounts of data, a new storage method has developed that can store even more significant and varied amounts of data. These are called data lakes. What Are Data Lakes? However, even digital information has to be stored somewhere.
Cost efficiency : Power BI can directly leverage data stored in OneLake, eliminating the need for separate SQL queries and reducing costs associated with data processing. This open format allows for seamless storage and retrieval of data across different databases.
Artificial intelligence (AI) adoption is still in its early stages. As more businesses use AI systems and the technology continues to mature and change, improper use could expose a company to significant financial, operational, regulatory and reputational risks. ” Are foundation models trustworthy?
Amazon Redshift is the most popular cloud datawarehouse that is used by tens of thousands of customers to analyze exabytes of data every day. Conclusion In this post, we demonstrated an end-to-end data and ML flow from a Redshift datawarehouse to SageMaker.
There are many well-known libraries and platforms for data analysis such as Pandas and Tableau, in addition to analytical databases like ClickHouse, MariaDB, Apache Druid, Apache Pinot, Google BigQuery, Amazon RedShift, etc. With Great Expectations , data teams can express what they “expect” from their data using simple assertions.
Five Best Practices for Data Analytics. Extracted data must be saved someplace. There are several choices to consider, each with its own set of advantages and disadvantages: Datawarehouses are used to store data that has been processed for a specific function from one or more sources. Select a Storage Platform.
is our enterprise-ready next-generation studio for AI builders, bringing together traditional machine learning (ML) and new generative AI capabilities powered by foundation models. With watsonx.ai, businesses can effectively train, validate, tune and deploy AI models with confidence and at scale across their enterprise.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content