This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction SQL is easily one of the most important languages in the computer world. It serves as the primary means for communicating with relational databases, where most organizations store crucial data. SQL plays a significant role including analyzing complex data, creating data pipelines, and efficiently managing datawarehouses.
SQL (Structured Query Language) is an important tool for data scientists. It is a programming language used to manipulate data stored in relational databases. Mastering SQL concepts allows a data scientist to quickly analyze large amounts of data and make decisions based on their findings.
Built into Data Wrangler, is the Chat for data prep option, which allows you to use natural language to explore, visualize, and transform your data in a conversational interface. Amazon QuickSight powers data-driven organizations with unified (BI) at hyperscale. A provisioned or serverless Amazon Redshift datawarehouse.
Summary : This guide provides an in-depth look at the top datawarehouse interview questions and answers essential for candidates in 2025. Covering key concepts, techniques, and best practices, it equips you with the knowledge needed to excel in interviews and demonstrates your expertise in data warehousing.
The main solutions on the market are decentralized file storage networks (DSFN) like Filecoin and Arweave, and decentralized datawarehouses like Space and Time (SxT). Built to seamlessly integrate with existing enterprise systems, the datawarehouse lets businesses tap into blockchain data while publishing query results back on-chain.
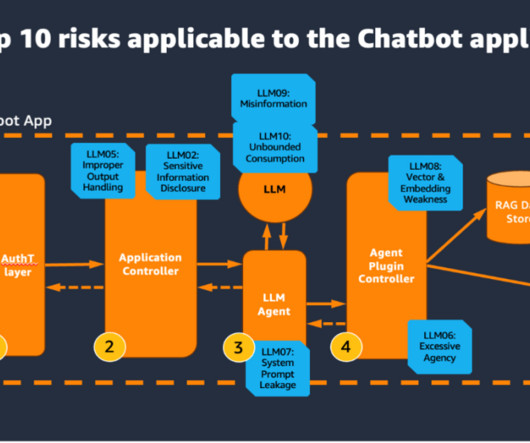
A common use case with generative AI that we usually see customers evaluate for a production use case is a generative AI-powered assistant. If there are security risks that cant be clearly identified, then they cant be addressed, and that can halt the production deployment of the generative AI application.
In the process of working on their ML tasks, data scientists typically start their workflow by discovering relevant data sources and connecting to them. They then use SQL to explore, analyze, visualize, and integrate data from various sources before using it in their ML training and inference.
Amazon Redshift powers data-driven decisions for tens of thousands of customers every day with a fully managed, AI-powered cloud datawarehouse, delivering the best price-performance for your analytics workloads.
It powers business decisions, drives AI models, and keeps databases running efficiently. But heres the problem: raw data is often messy. Thats where data normalization comes in. Its a structured process that organizes data to reduce redundancy and improve efficiency. Think about itdata is everywhere. Simple, right?
Organizations are building data-driven applications to guide business decisions, improve agility, and drive innovation. Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. The following screenshot illustrates the SageMaker Unified Studio.
We spoke with Dr. Swami Sivasubramanian, Vice President of Data and AI, shortly after AWS re:Invent 2024 to hear his impressionsand to get insights on how the latest AWS innovations help meet the real-world needs of customers as they build and scale transformative generative AI applications. Canva uses AWS to power 1.2
Dating back to the 1970s, the data warehousing market emerged when computer scientist Bill Inmon first coined the term ‘datawarehouse’. Created as on-premise servers, the early datawarehouses were built to perform on just a gigabyte scale.
A datawarehouse is a centralized repository designed to store and manage vast amounts of structured and semi-structured data from multiple sources, facilitating efficient reporting and analysis. Begin by determining your data volume, variety, and the performance expectations for querying and reporting.
Almost every tech company today is up to its neck in generative AI, with Google focused on enhancing search, Microsoft betting the house on business productivity gains with its family of copilots, and startups like Runway AI and Stability AI going all-in on video and image creation. Why is data integrity important?
Data is reported from one central repository, enabling management to draw more meaningful business insights and make faster, better decisions. By running reports on historical data, a datawarehouse can clarify what systems and processes are working and what methods need improvement.
At the heart of this transformation is the OMRON Data & Analytics Platform (ODAP), an innovative initiative designed to revolutionize how the company harnesses its data assets. The robust security features provided by Amazon S3, including encryption and durability, were used to provide data protection.
These datasets are often a mix of numerical and text data, at times structured, unstructured, or semi-structured. needed to address some of these challenges in one of their many AI use cases built on AWS. RAG with semantic search – Conventional RAG with semantic search was the last step before moving to SQL generation.
Discover the nuanced dissimilarities between Data Lakes and DataWarehouses. Data management in the digital age has become a crucial aspect of businesses, and two prominent concepts in this realm are Data Lakes and DataWarehouses. It acts as a repository for storing all the data.
Domain experts, for example, feel they are still overly reliant on core IT to access the data assets they need to make effective business decisions. In all of these conversations there is a sense of inertia: Datawarehouses and data lakes feel cumbersome and data pipelines just aren't agile enough.
Sigma Computing , a cloud-based analytics platform, helps data analysts and business professionals maximize their data with collaborative and scalable analytics. One of Sigma’s key features is its support for custom SQL queries and CSV file uploads. These tools allow users to handle more advanced data tasks and analyses.
In this article, we will delve into the concept of data lakes, explore their differences from datawarehouses and relational databases, and discuss the significance of data version control in the context of large-scale data management. Schema Enforcement: Datawarehouses use a “schema-on-write” approach.
One of the most common applications of generative artificial intelligence (AI) and large language models (LLMs) in an enterprise environment is answering questions based on the enterprise’s knowledge corpus. Natural language is ambiguous and imprecise, whereas data adheres to rigid schemas.
Data can be generated from databases, sensors, social media platforms, APIs, logs, and web scraping. Data can be in structured (like tables in databases), semi-structured (like XML or JSON), or unstructured (like text, audio, and images) form.
IBM today announced it is launching IBM watsonx.data , a data store built on an open lakehouse architecture, to help enterprises easily unify and govern their structured and unstructured data, wherever it resides, for high-performance AI and analytics. What is watsonx.data?
With the advent of generative AI solutions, organizations are finding different ways to apply these technologies to gain edge over their competitors. Amazon Bedrock offers a choice of high-performing foundation models from leading AI companies, including AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon, via a single API.
Unified data storage : Fabric’s centralized data lake, Microsoft OneLake, eliminates data silos and provides a unified storage system, simplifying data access and retrieval. Flexible compute capacity One of the key advantages of Microsoft Fabric is its ability to optimize compute capacity across different workloads.
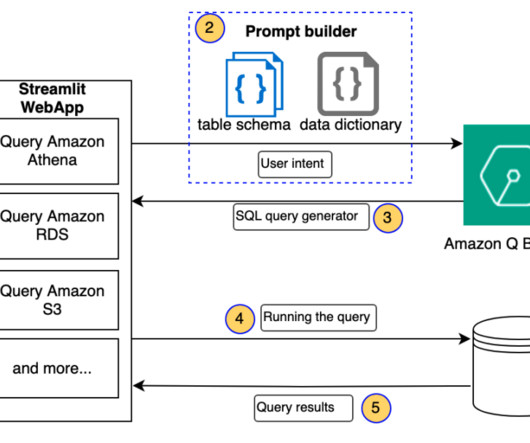
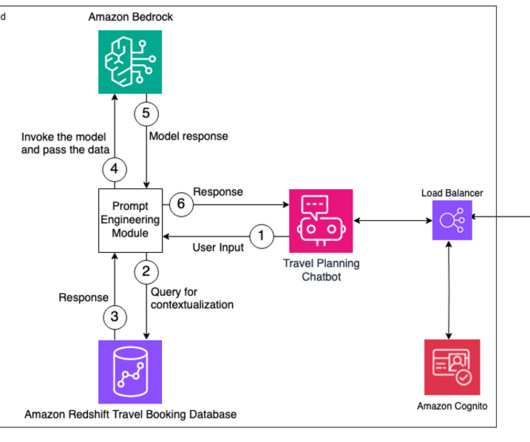
Organizations can maximize the value of their modern data architecture with generative AI solutions while innovating continuously. The natural language capabilities allow non-technical users to query data through conversational English rather than complex SQL. The following diagram illustrates the architecture.
It must integrate seamlessly across data technologies in the stack to execute various workflows—all while maintaining a strong focus on performance and governance. Two key technologies that have become foundational for this type of architecture are the Snowflake AIData Cloud and Dataiku. Let’s say your company makes cars.
Amazon Redshift is the most popular cloud datawarehouse that is used by tens of thousands of customers to analyze exabytes of data every day. You can use query_string to filter your dataset by SQL and unload it to Amazon S3. If you’re familiar with SageMaker and writing Spark code, option B could be your choice.
Codd published his famous paper “ A Relational Model of Data for Large Shared Data Banks.” Boyce to create Structured Query Language (SQL). Its robust architecture and proven performance have given businesses uninterrupted access to critical data while powering their enterprise-level applications.
As a bonus, well check out Matillions AI Copilot and see how AI can help take workflow design to the next level. A Matillion pipeline is a collection of jobs that extract, load, and transform (ETL/ELT) data from various sources into a target system, such as a cloud datawarehouse like Snowflake.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
Summary: Online Analytical Processing (OLAP) systems in DataWarehouse enable complex Data Analysis by organizing information into multidimensional structures. Key characteristics include fast query performance, interactive analysis, hierarchical data organization, and support for multiple users.
is our enterprise-ready next-generation studio for AI builders, bringing together traditional machine learning (ML) and new generative AI capabilities powered by foundation models. With watsonx.ai, businesses can effectively train, validate, tune and deploy AI models with confidence and at scale across their enterprise.
Domain experts, for example, feel they are still overly reliant on core IT to access the data assets they need to make effective business decisions. In all of these conversations there is a sense of inertia: Datawarehouses and data lakes feel cumbersome and data pipelines just aren't agile enough.
Cleanlab GitHub | Website Cleanlab is focused on data-centric AI (DCAI), providing algorithms/interfaces to help companies (across all industries) improve the quality of their datasets and diagnose/fix various issues in them. With Great Expectations , data teams can express what they “expect” from their data using simple assertions.
Run pandas at scale on your datawarehouse Most enterprise data teams store their data in a database or datawarehouse, such as Snowflake, BigQuery, or DuckDB. Ponder solves this problem by translating your pandas code to SQL that can be understood by your datawarehouse.
Businesses face significant hurdles when preparing data for artificial intelligence (AI) applications. The existence of data silos and duplication, alongside apprehensions regarding data quality, presents a multifaceted environment for organizations to manage.
Over the past few decades, the corporate data landscape has changed significantly. The shift from on-premise databases and spreadsheets to the modern era of cloud datawarehouses and AI/ LLMs has transformed what businesses can do with data. Designed to cheaply and efficiently process large quantities of data.
They all agree that a Datamart is a subject-oriented subset of a datawarehouse focusing on a particular business unit, department, subject area, or business functionality. The Datamart’s data is usually stored in databases containing a moving frame required for data analysis, not the full history of data.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content